本文主要是介绍QWEN technical report,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
通义千问-Qwen技术报告细节分享 - 知乎写在前面大家好,我是刘聪NLP。 阿里在很早前就开源了Qwen-7B模型,但不知道为什么又下架了。就在昨天阿里又开源了Qwen-14B模型(原来的7B模型也放出来了),同时还放出了Qwen的技术报告内容。今天特此来给大家分…![]() https://zhuanlan.zhihu.com/p/6583926091.introduction
https://zhuanlan.zhihu.com/p/6583926091.introduction
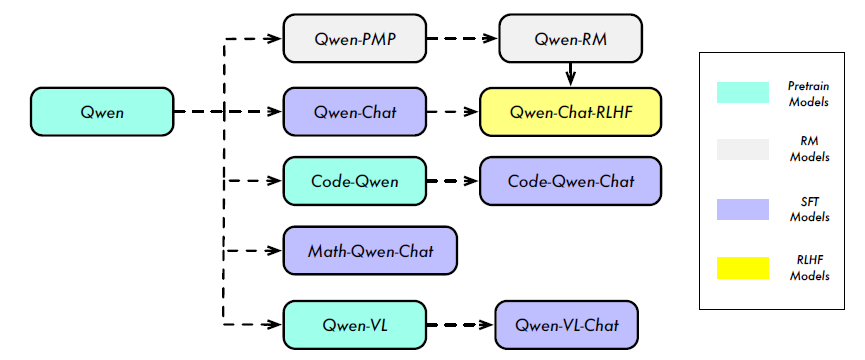
3万亿token,
2.pretraining
2.1 data
去重,精确匹配去重和使用MinHash和LSH模糊去重,过滤低质量的数据,采用了基于规则和基于机器学习的方法的组合,使用多个模型对内容进行评分,包括语言模型、文本质量评分模型以及用于识别有可能含有不合适的内容的模型。构建了一个高达3万亿个token的数据集。
2.2 tokenization
采用字节对编码BPE分词,使用tiktoken。在中文,增加了常用的汉字和词汇以及其它语言中的词汇,遵循llama系列的方法,将数字拆分成单个数字,最终词汇为152k。压缩率:一个汉字能够转成多少token,比如0.52个token,意味着一句话能够转成更少的token。
2.3 architecture
结构基本和llama对齐。
embedding和output project:对于embedding层和lm_head层不进行权重共享,是两个独立的权重。
positional embedding:RoPE
bias:在qkv中添加了偏差,以增强模型外推能力。
Pre-RMSNorm
激活函数:SwiGLU
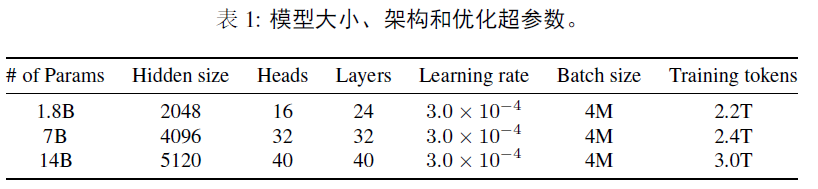
2.4 training
上下文长度:2048,采用flash attention,AdamW,BFloat16
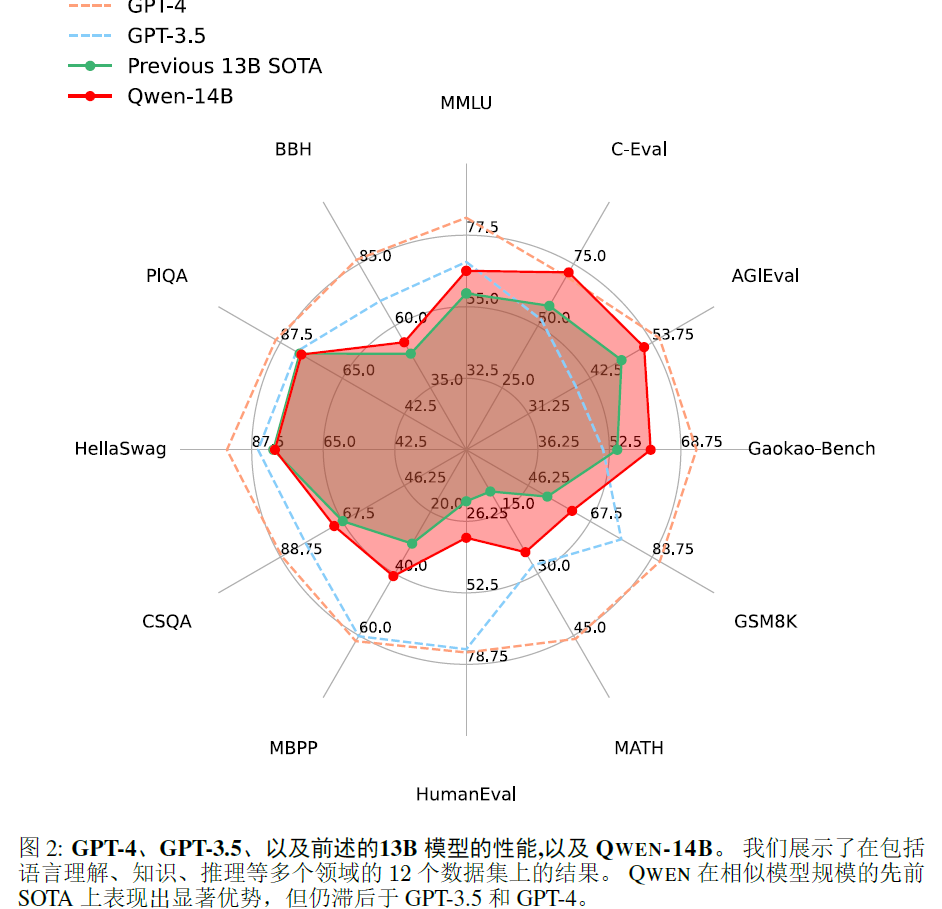
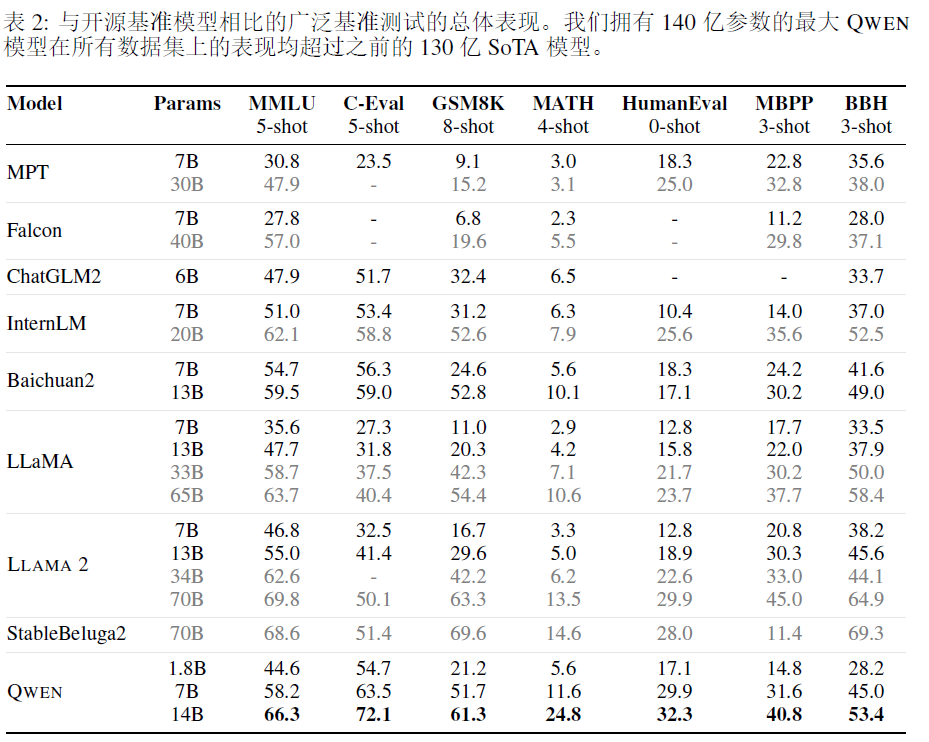
2.5 experimental results
这篇关于QWEN technical report的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - MultiModal篇](https://i-blog.csdnimg.cn/direct/5cd8f3334ae74386b28c9736370a95f2.jpeg#pic_center)
