本文主要是介绍别乱用开源数据集!这点不注意,小心被推上风口浪尖,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

本文来源:OpenDataLab
更多资料获取:有道云笔记
为了共享科研成果,许多AI 研究员选择开源自己的项目和数据集。但开源不等于毫无限制,不代表使用者可以为所欲为。不正确的使用方式,会带来许多法律风险。
本文介绍数据集 License 的基本知识,教你看懂和正确使用它们。

IBM论文被曝抄袭开源项目
这两天,接连2篇入选的论文被曝抄袭,让原本就备受关注的CVPR 2022 站到了风口浪尖。
一篇是来自韩国首尔大学 AI 研究团队的论文,入选了 CVPR Oral(口头报告),被曝出涉嫌抄袭10篇论文,甚至出现原句照抄的内容。
另外,IBM 一篇入选的论文也被举报涉嫌抄袭,来自平安科技的研究员向CVPR 2022 program chairs 举证,指出 IBM 的 TableFormer 从方法论、预处理、后期处理、文字行检测与识别等9个方面抄袭了自己团队2021年的开源项目 TableMASTER。爆料者表示,很多痕迹都可以看出,IBM 基于他们开源的预训练模型训练,只是改了一些细节。[1][2]
![]()
IBM 相关 TableFormer论文被指抄袭(图源:参考资料[7])
这引发了国内外 AI 研究员的热烈讨论。有网友调侃,抄袭的论文都能拿Oral,而认认真真做实验的论文却因为各种理由被拒,得好好研究一下这是如何做到的。
其背后透露出的是科研人的苦楚、对论文审查结果的不满,还有对开源项目不规范使用的担忧。

数据集开放协议介绍
在倡导开源共享的今天,开源不仅仅是一种热爱分享的极客精神,而是已经成为一种分布式可信的开发模式。许可协议(License)则是规范知识产权保护与作品使用权限的有力载体。
不管是算法、模型、数据集,从创造之初就和其他创意作品一样默认享有著作权。许可协议则是基于著作权法,为了实现作品的自由分发以及自由修改,而提出的一系列标准化的公共许可合同,便于作品拥有人授权给其他人使用。
软件与其他类型的创意作品有较大不同,常用“开源协议”来规范开源软件的使用。比如,常见的Apache v2、BSD、MIT、GPL、LGPL等,有的数据集也会采用这类开源协议,经常接触开源项目的朋友比较熟悉,就不做过多展开。
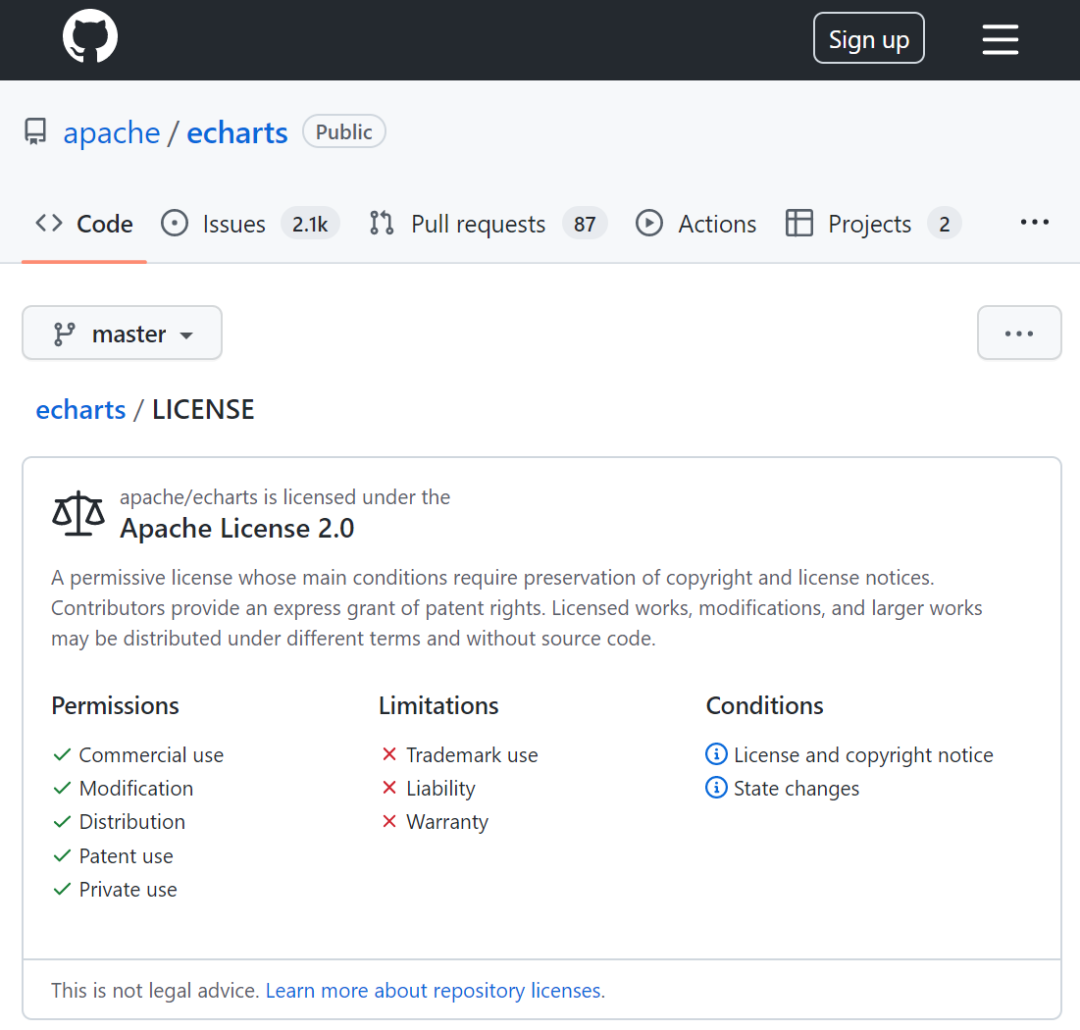
代码托管平台的开源协议示意(图源:Github)
而常用的数据集许可协议有3种来源:
● 知识共享 (CC)
● 开放数据共享 (ODC)
● 社区数据许可协议 (CDLA)

知识共享许可协议
知识共享这一非营利性组织于2001年成立。知识共享组织提供了6种非独占的、不可撤销的标准化著作权许可协议,每个许可协议都有自己的使用条款,便于作品的作者放弃自己的部分著作权,从而有助于作品的共享。[3]
知识共享许可协议(Creative Commons license),即CC许可协议,是目前全球最受欢迎的数据集许可证,主要涉及4项权利,署名(BY)权,继承(SA)权,非盈利(NC)权,禁止演绎(ND)权。
(需要注意的是,CC许可协议是著作权许可协议,因此只涉及著作权及相关的邻接权,而不涉及专利、商标等其他知识产权,也不涉及肖像权、隐私权、形象权等其他权利。[4])
1. 六种CC许可协议
● CC BY
(Attribution 署名)
保留原作者姓名,允许基于商业目的传播、改编或者二次创作。
● CC BY-SA
(Attribution-ShareAlike 署名-相同方式共享)
保留原作者姓名,并且新作品也使用相同的许可协议,才能对原作进行基于商业目的的改编和二次创作。
● CC BY-ND
(Attribution-NoDerivs 署名-禁止演绎)
保留原作者姓名,允许商用,但是不能改编原作与他人分享。
● CC BY-NC
(Attribution-Noncommercial 署名-非商业性)
保留原作者姓名,允许非商业目的重新编排、改编或者再创作,但是不能商用。基于原作的演绎作品无需使用相同的许可协议。
● CC BY-NC-SA
(Attribution-NonCommercial-ShareAlike 署名-非商业性使用-相同方式共享)
需保留原作者姓名,并在基于原作创作的新作品适用同类型的许可协议,即可基于非商业目的对原作重新编排、改编或者再创作。
● CC BY-NC-ND
(Attribution-NonCommercial-NoDerivs 署名-非商业使用-禁止演绎)
这是六种主要许可协议中限制最为严格的,保留原作者姓名,允许下载和分享,但是不能对原作进行任何形式的修改和商用。

CC许可协议示意(图源:参考资料[5])
2. 公共领域许可协议
● CC0
知识共享组织于2009年发布了一种放弃著作权的便捷方式,即CC0。严格来讲CC0并非双方的许可合同,而是一种单方的声明。选择CC0作为许可协议,则说明作者将数据集捐赠给公众使用,此数据集完全公有,使用时无需署名,也无其他限制。

开放数据共享许可证
开放数据共享 (ODC) 为开放数据提供合法工具。他们提供三种许可类型,每种都有自己的使用条款!
● ODC-PDDL
这是开放数据共享公共领域专用许可证,版权所有者永久删除所有版权,不保留任何权利。这对应于CC0 许可协议。
● ODC-BY
这是开放数据共享署名许可。你可以自由分享和改编,但需要注明出处,允许商业用途。这对应于CC BY(署名)许可。
● ODC-ODbL
这是开放数据共享开放数据库许可证。你可以自由分享和改编,并在基于原作创作的新作品适用同类型的许可协议。允许商业用途。这对应于CC BY-SA (署名-相同方式共享)许可协议。

社区数据许可协议
2017年,Linux 基金会提出了社区数据许可协议 (CDLA) 为社区提供了开放的数据共享选项。他们提供两种许可类型,每种都有自己的使用条款。[5]
● CDLA-Permissive-2.0
这是社区数据许可协议的第二个版本。对开放数据的贡献者和使用者不作要求。你可以使用、修改和共享,许可协议不对结果的使用、修改或共享施加任何限制或义务。
● CDLA-Sharing-1.0
这属于copyleft(强制共享)许可类别,你可以使用、修改和共享,但无论是否修改,基于原作创作的新作品必须与原始版本有相同的许可协议。

社区数据许可协议 (CDLA)官网(图源:参考资料[6])
以上就是常见的数据集的许可协议类型,也即是我们常说的数据集License 的含义。你学会解读了吗?

License结构化描述与审核
在OpenDataHub,我们贴心地帮大家整理好了各个数据集的License信息,并且从Permission, Limitations, Condition三个方面进行结构化梳理,使之更加完善,方便大家自主查询。
同时,平台也建立了严格的安全审核机制,核实了每个数据集的分发依据,确保每个可获得的数据集都是符合授权的,使大家能够快速、便捷、安全无忧地使用。
还等什么,快来试试吧。
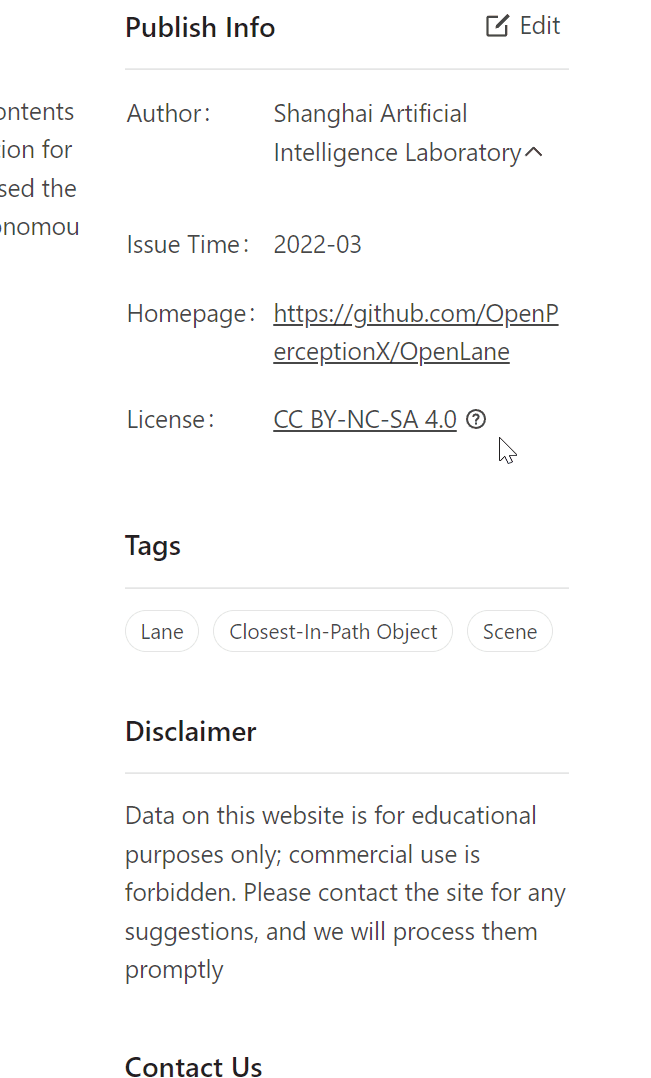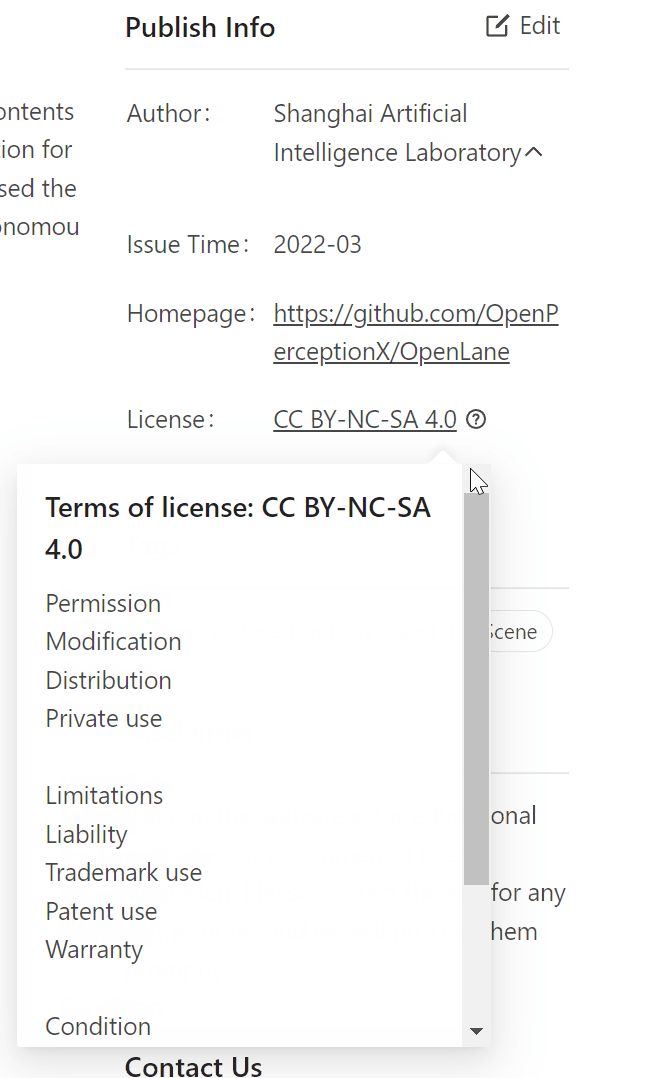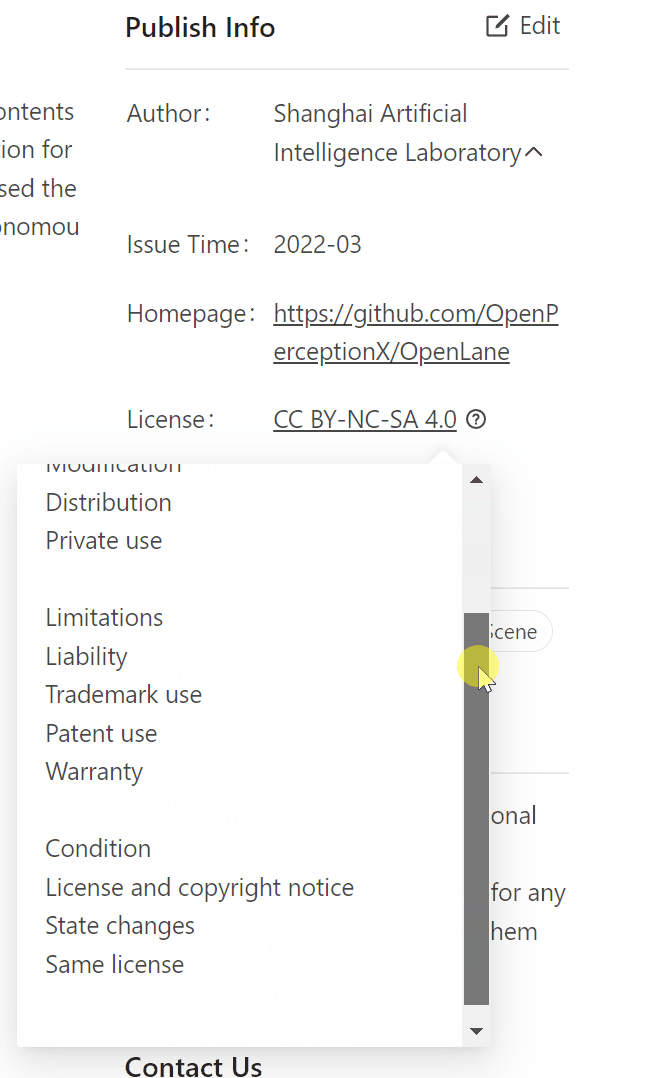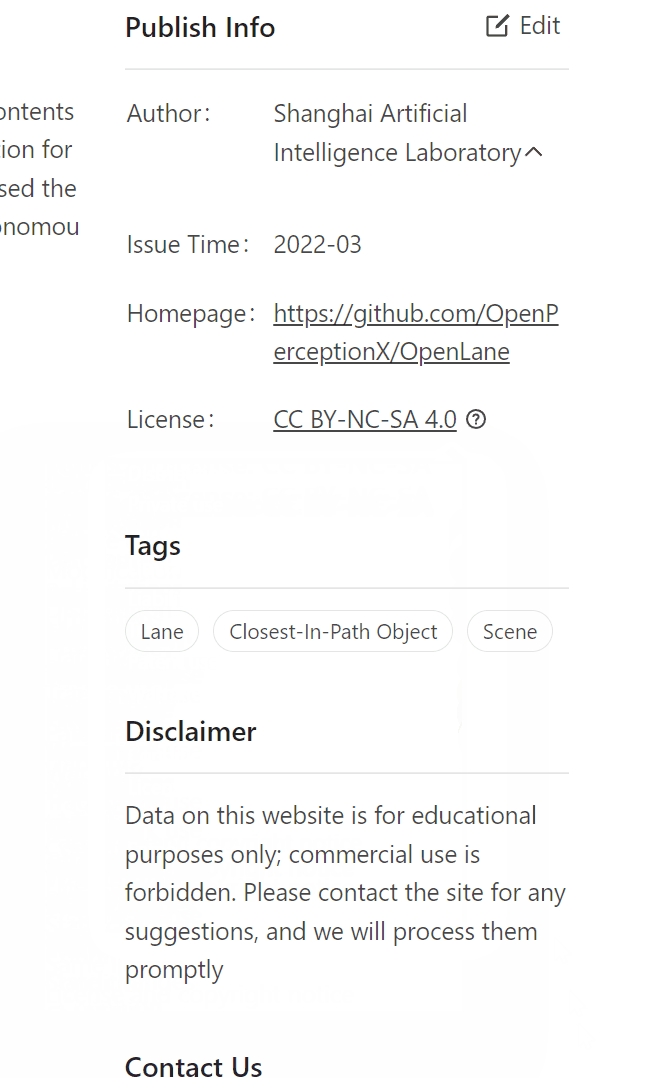
OpenDataHub数据集License示意
(图源:https://opendatalab.com/)
参考资料
[1]https://zhuanlan.zhihu.com/p/115911178
[2]https://www.youtube.com/watch?v=UCmkpLduptU
[3]https://wiki.creativecommons.org/wiki/Considerations_for_licensors_and_licensees#Make_sure_the_material_is_appropriate_for_CC_licensing.
[4]https://www.reddit.com/r/MachineLearning/comments/vlpnuw/d_ibm_zurich_research_plagiarised_our_paper_and/
[5]https://creativecommons.org/
[6]https://cdla.dev/sharing-1-0/
[7]https://www.reddit.com/r/MachineLearning/comments/vlpnuw/d_ibm_zurich_research_plagiarised_our_paper_and/
这篇关于别乱用开源数据集!这点不注意,小心被推上风口浪尖的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







