本文主要是介绍欧洲最大云厂商遇火灾,数据安全任重道远!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
3月10日欧洲最大云计算厂商OVH位于斯特拉斯堡的数据中心,发生历史上史无前例的灾难性事件,整个数据中心被大伙烧毁。3月11日至今仍在努力恢复中。影响包括火爆全球的视频游戏制作公司Rust、Deribit、英法波政府平台等在内的360万个网站。在云迅猛发展的今天,我们该如何应对不确定性带来的业务不可持续和数据安全灾难呢?
01 OVHCloud火灾事回顾
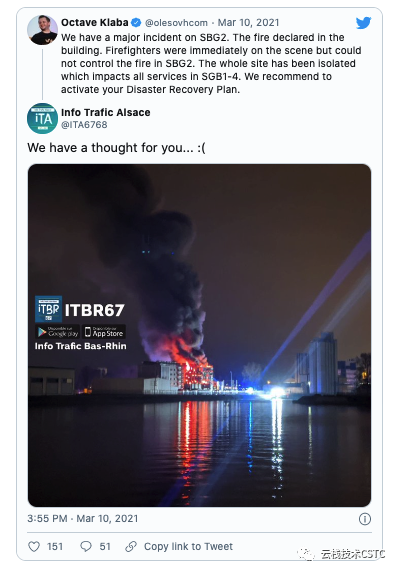
3月10日 周三深夜,OVHcloud位于斯特拉斯堡的SBG2数据中心被大伙烧毁,同时SBG1数据中心也部分受损,SBG3和SBG4数据中心因受消防保护,被迫停服。360万个站点处于离线状态。
3月11日 火灾造成的破坏程度超过了想象,OVHcloud宣布下周在重新开放斯特拉斯堡的数据中心,同时将Roubaix和Gravelines数据中心的服务器交付给受影响的客户用于恢复。未来几周内,将10000新服务器用于重建斯特拉斯堡数据中心。根据Gartner分析师分析,推测此次火灾是由于UPS故障导致的。
3月12日 保护和清理现场,为火灾中幸存的SBG1 SBG3 SBG4三个数据中心重新恢复电力和网络。
02 分析与推测
按照数据中心建设与运营的标准,每个设施内部都应该配置相应的消防系统,包括自动报警设备等,但此次火灾居然烧掉了整个SBG2数据中心,是否在机房消防维护及消防应急演练存在不足呢?
日常运维工作是否存在不规范的现象?发生火灾时,值班员工做什么?(至少从OVHcloud反馈看,没有看到行动项)
不同AZ之间如果有较好的灾备能力,是否至少保障数据不丢失,也可以帮助用户在较短时间内恢复业务?
03 灾备与业务连续性
定义
我们先看两个定义,灾难恢复(DR)与业务连续性(BCM):
灾难恢复DRP:目标是尽量减少灾难或中断带来的影响,意味着需要采取必要的步骤以确保资源、人员和业务流程能够及时恢复运行。侧重技术层面,是BCP的一个组成部分。
业务连续性BCP:基于企业战略的、处理长期的、面向中断中和后维持业务连续性的规划,核心是保证组织和业务持续运作。侧重业务层面。
对于各行各业而言,用户数据、系统数据均是企业最核心、最重要的财富,业务的稳定运行、IT系统功能正常是企业最重要的发展诉求。而这些诉求常常因为一些不可预期不可力抗“天灾人祸”变得十分困难,例如自然灾害、物理损坏、逻辑错误还是人为故障等都会导致不可用、功能异常甚至完全中断或数据丢失。我们该如何应对呢?答案就是DRP和BCP,永远要有PLAN B。
关键技术指标
进行灾备解决方案设计时,需关注灾备的两个关键技术指标:
RTO:RecoveryTime Object,恢复时间目标。指灾难发生后,从IT系统宕机导致业务停顿之刻开始,到IT系统恢复至可以支持各部门运作,业务恢复运营之时,此两点之间的时间段称为RTO。RTO是反映业务恢复及时性的指标,体现了企业能容忍的IT系统最长恢复时间。RTO值越小,代表容灾系统的恢复能力越强,但企业投资也越高。
RPO:Recovery Point Object,恢复点目标。指灾难发生后,容灾系统进行数据恢复,恢复得来的数据所对应的时间点称为RPO。RPO是反映数据丢失量的指标,体现了企业能容忍的最大数据丢失量的指标。RPO值越小,代表企业数据丢失越少,企业损失越小。
灾备等级
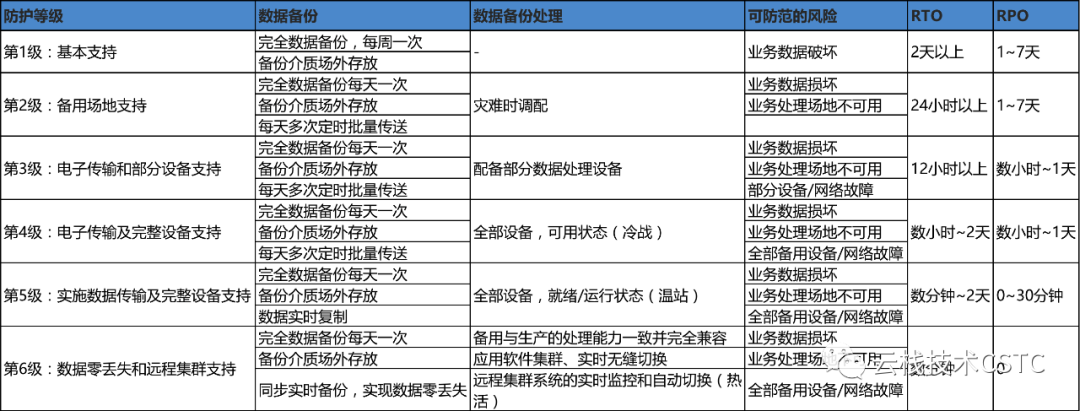
《中华人民共和国国家标准 GB/T 20988-2007 信息安全技术信息系统灾难恢复规范》
灾备要领
灾备方案的核心就是围绕平衡RTO和RPO的要求,找到最佳的总体投入(TCO)和投资回报(ROI):
做好数据异机备份[全备/增量](首要考虑的)
定义服务与业务SLA及容忍度
解决单点故障,服务本身容错
同朵云同Region内不同AZ多可用区容错(同城冷/热)
数据不同Region间备份
同朵云不同Region之间容错(异地冷/热)
多云之间数据备份(冷)
多云之间容错(冷/热,成本较高)
计划性验证数据备份有效及灾难恢复演练
人员重要岗位备份
最后,灾备恢复千万条,数据备份第一条!
长按二维码加群一起聊聊~

长按二维码关注公众号

*本公众号所发布内容仅代表作者观点,不代表社区立场
这篇关于欧洲最大云厂商遇火灾,数据安全任重道远!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




