本文主要是介绍阿里云OSS图床和百度OCR获取ak, sk,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
阿里云OSS和百度OCR每月都有免费的额度的, 除非使用频率极高或者密钥泄露, 正常情况下够用了, 超出后要扣费的, 所以不建议把自己的密钥发给他人使用
为啥要使用自己的账户来上传图片呢? 别人的图床说不定哪天就挂了, 当然还有很多其他的方式, 看个人习惯吧
使用阿里云oss好像是要先冲钱的, 正常情况下冲个一元钱也够用很久了, 因为没超额度是不扣钱的
获取阿里云的Access Key
https://oss.console.aliyun.com/
没有账号就注册一个
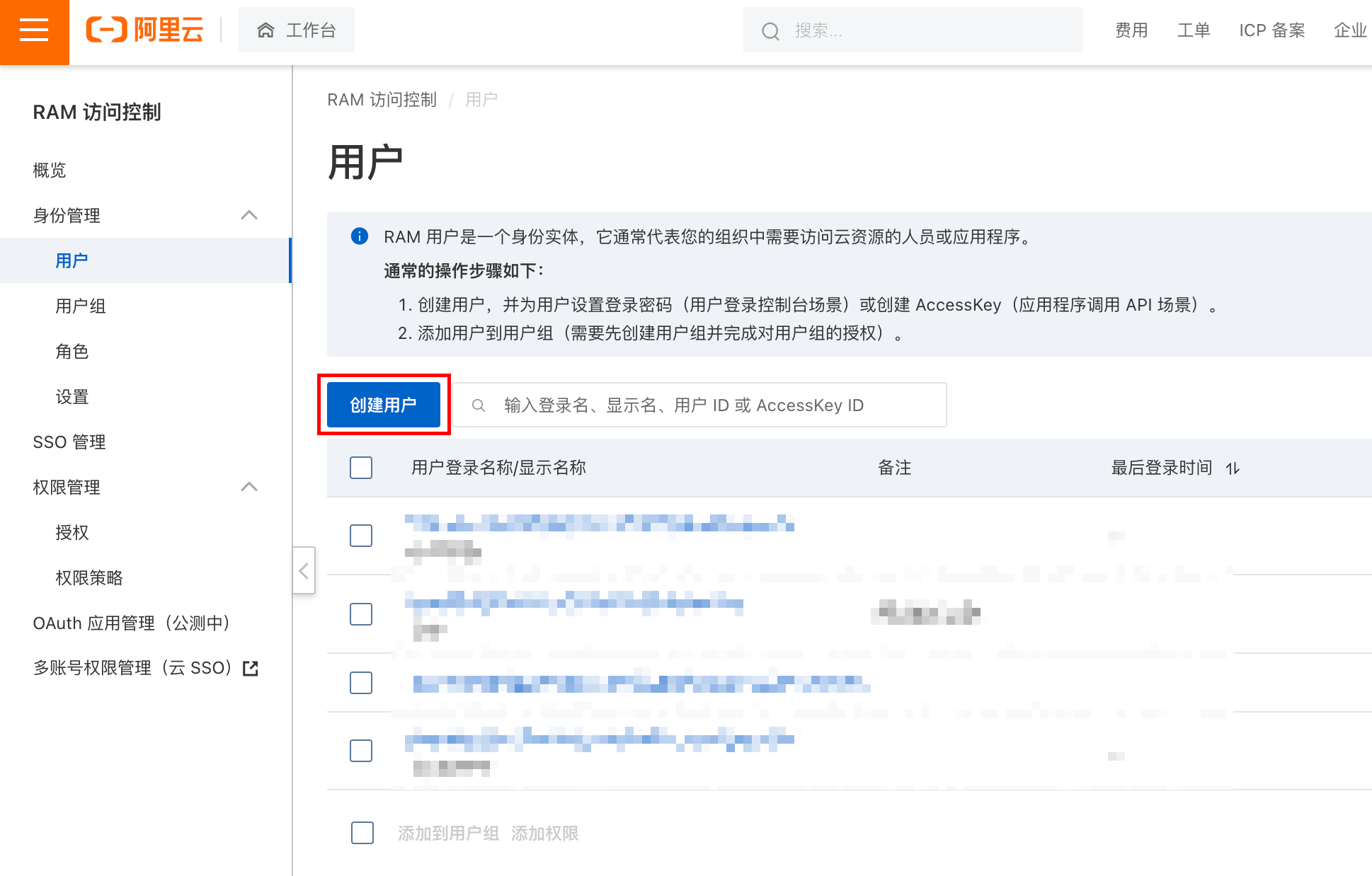
创建一个用户
https://ram.console.aliyun.com/users
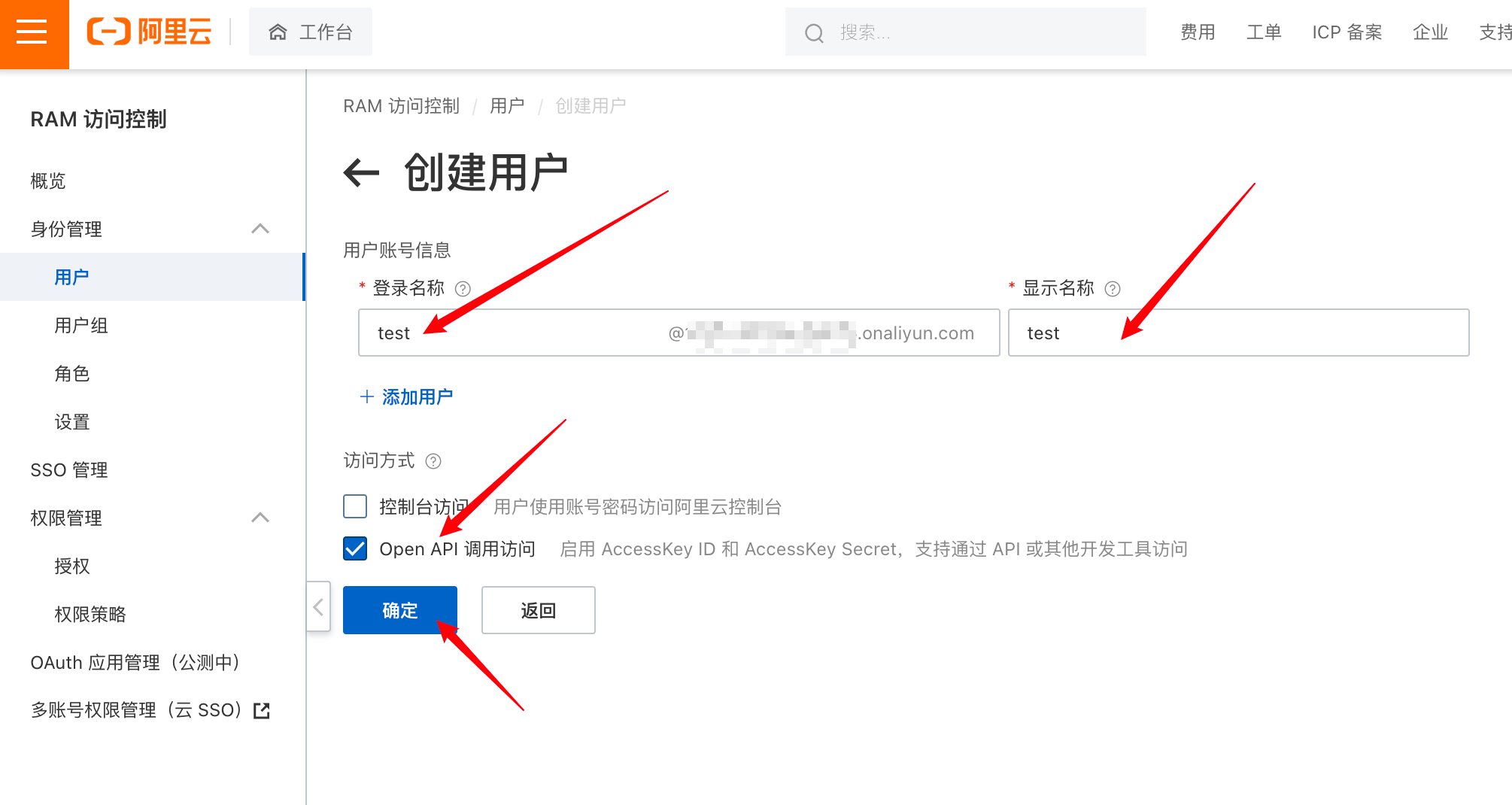
点击确认后有个安全验证
将AccessKey ID和AccessKey Secret复制下来, 新建一个记事本保存下来, 一会儿要用

https://ram.console.aliyun.com/users
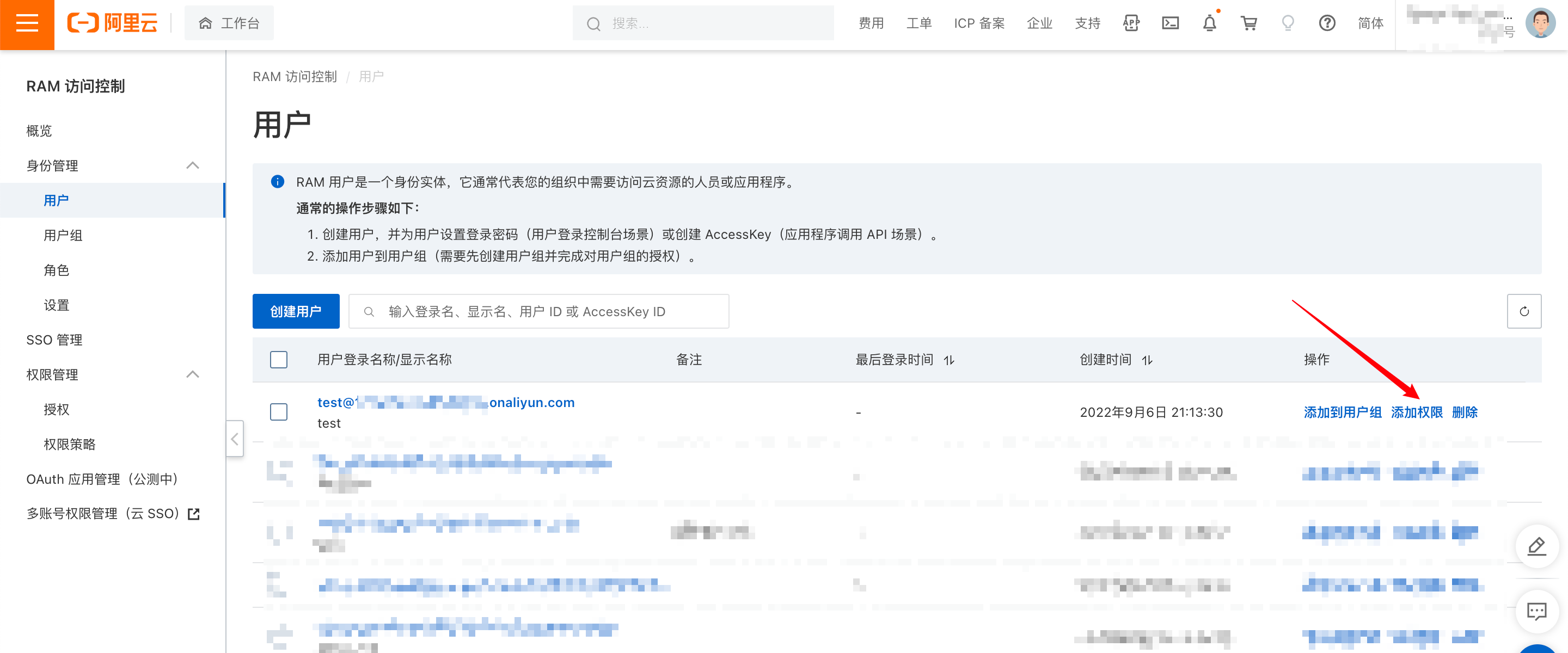
现在给账户添加权限
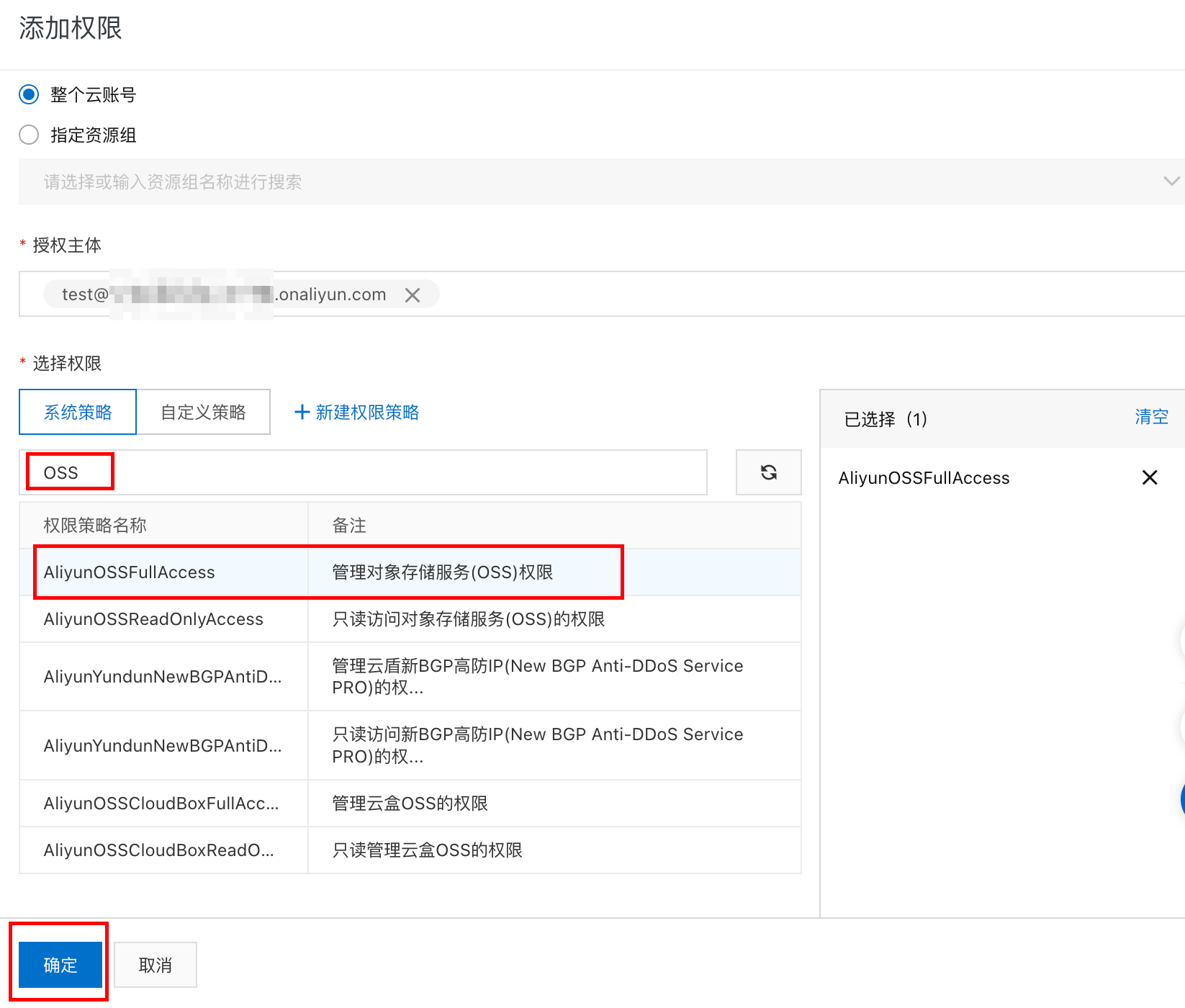
下一步没使用过oss的还需要开通下
创建bucket
https://oss.console.aliyun.com/bucket
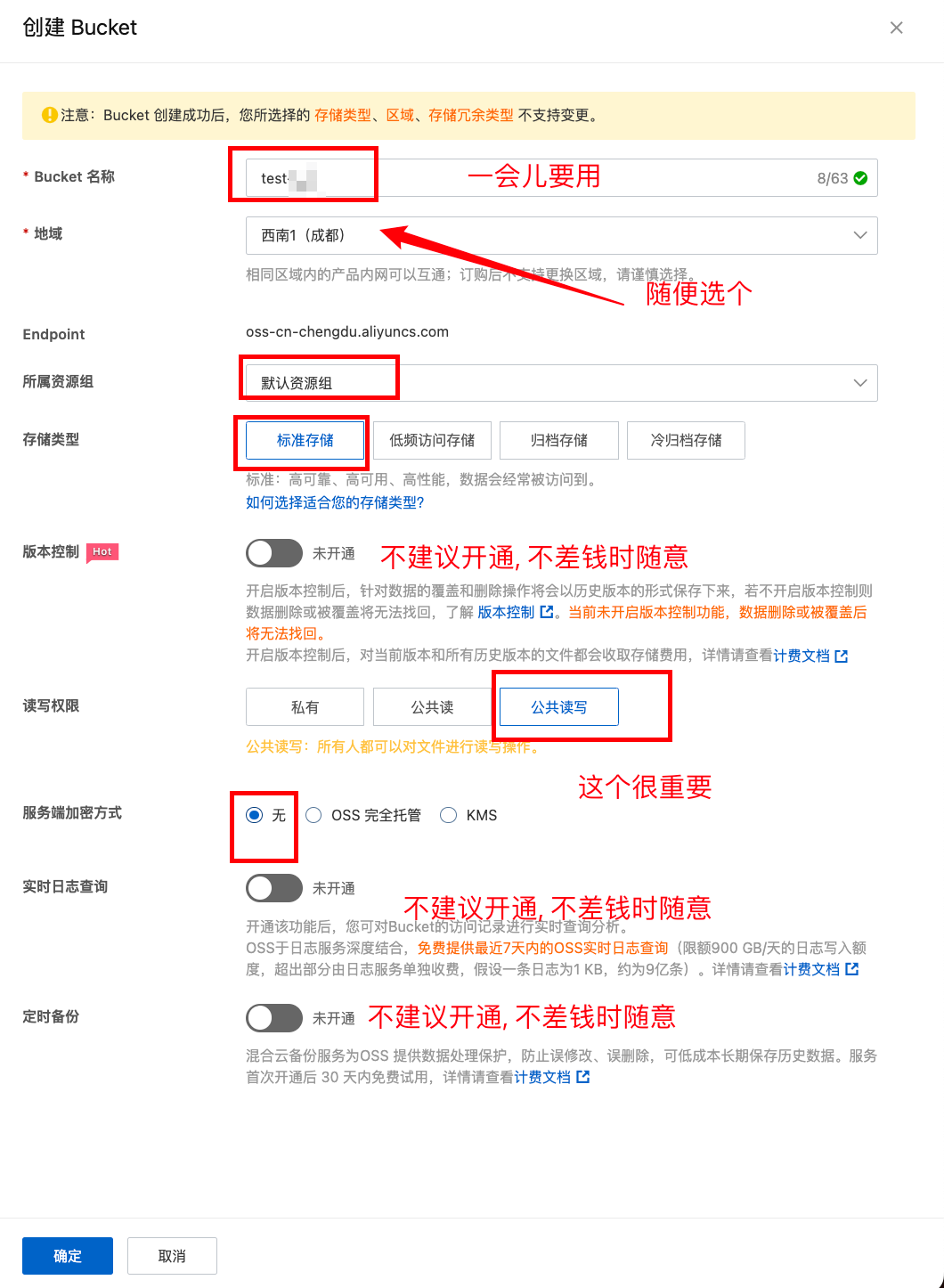
选好后点击确定
设置一下权限
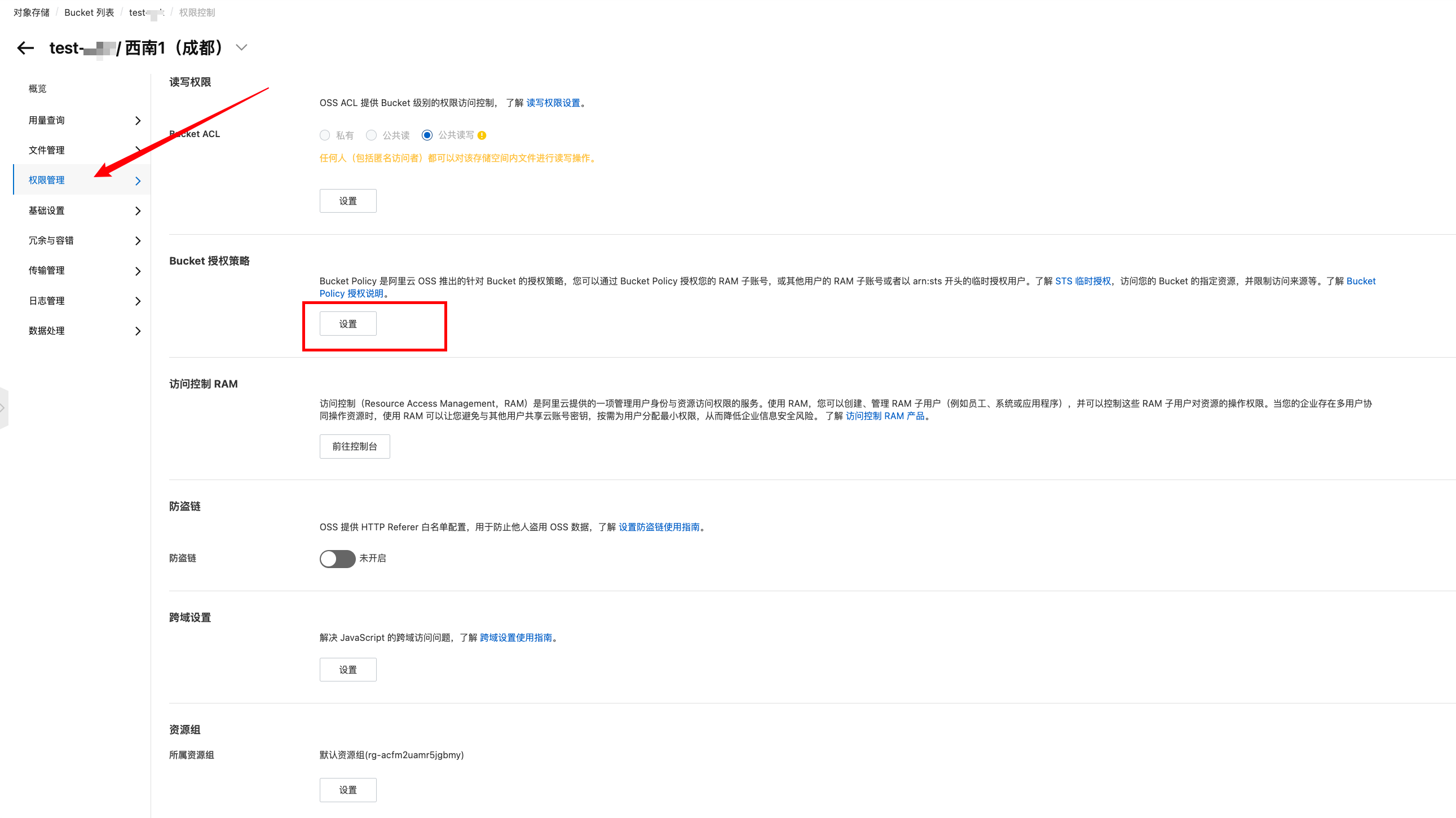
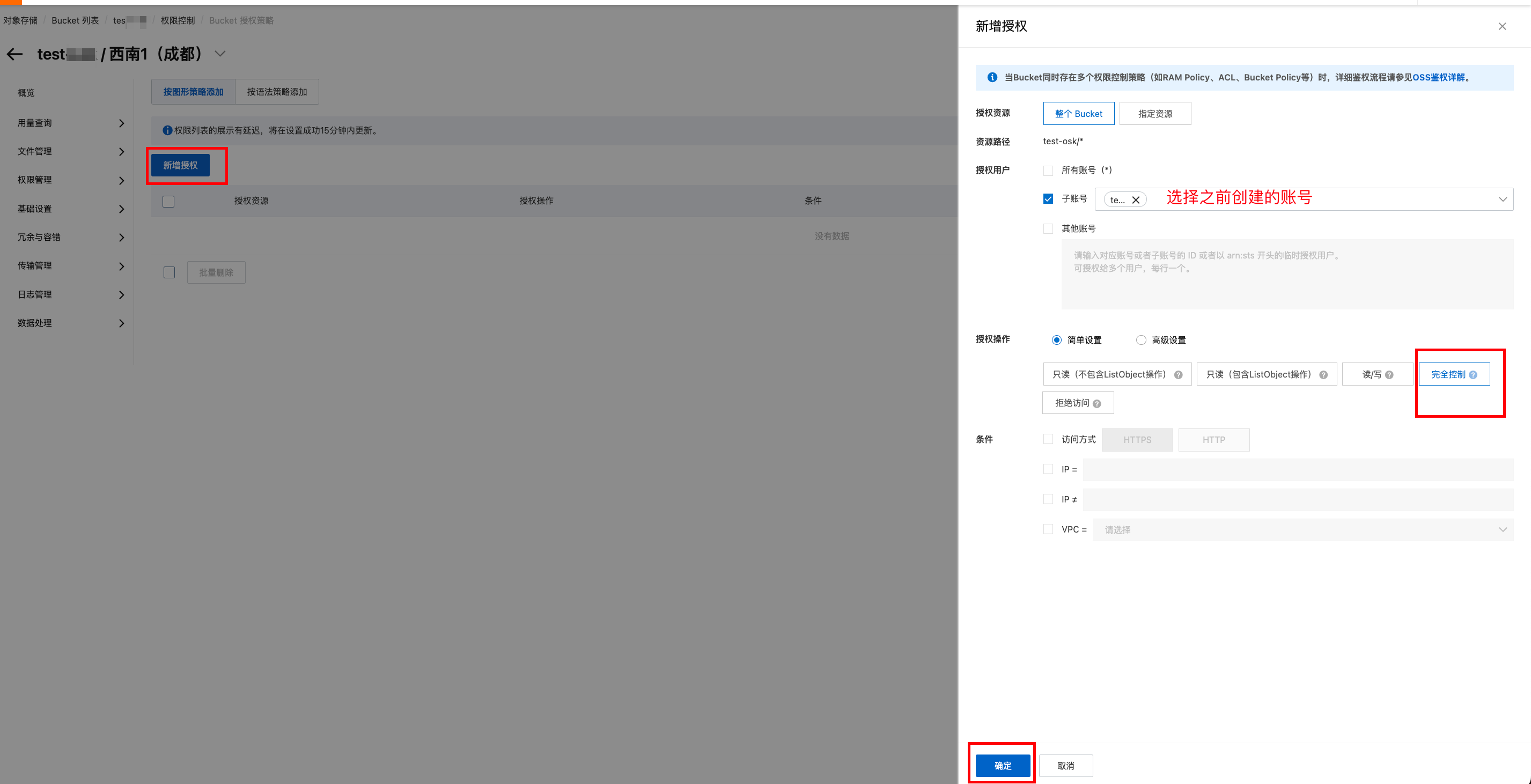
回到概览
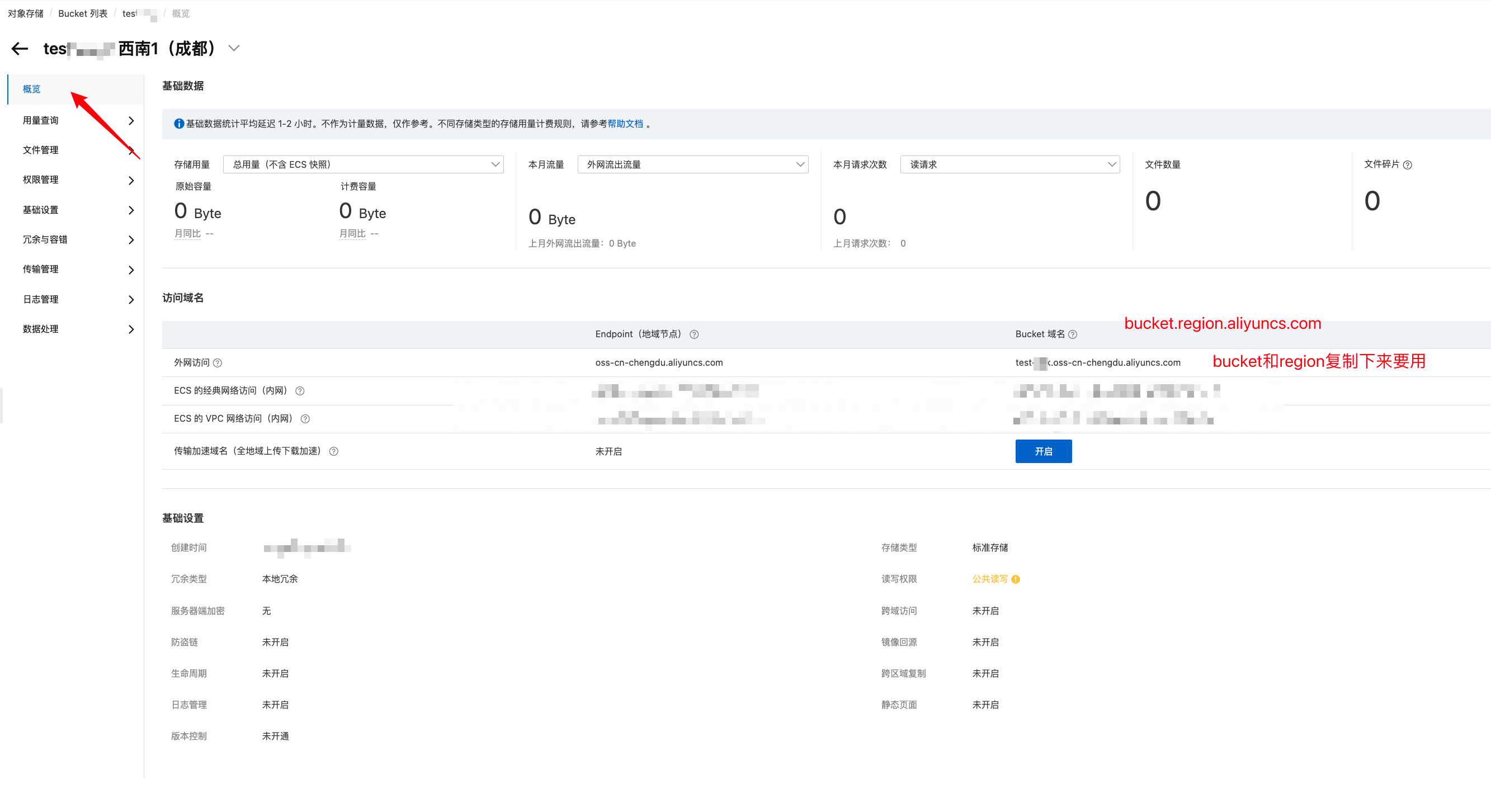
bucket和region可以在Bucket 域名中获取
到现在已经获取到 AccessKey ID, AccessKey Secret, bucket, region
获取百度OCR
https://ai.baidu.com/tech/ocr
没有账号的先注册个账号, 注册后打开上面地址
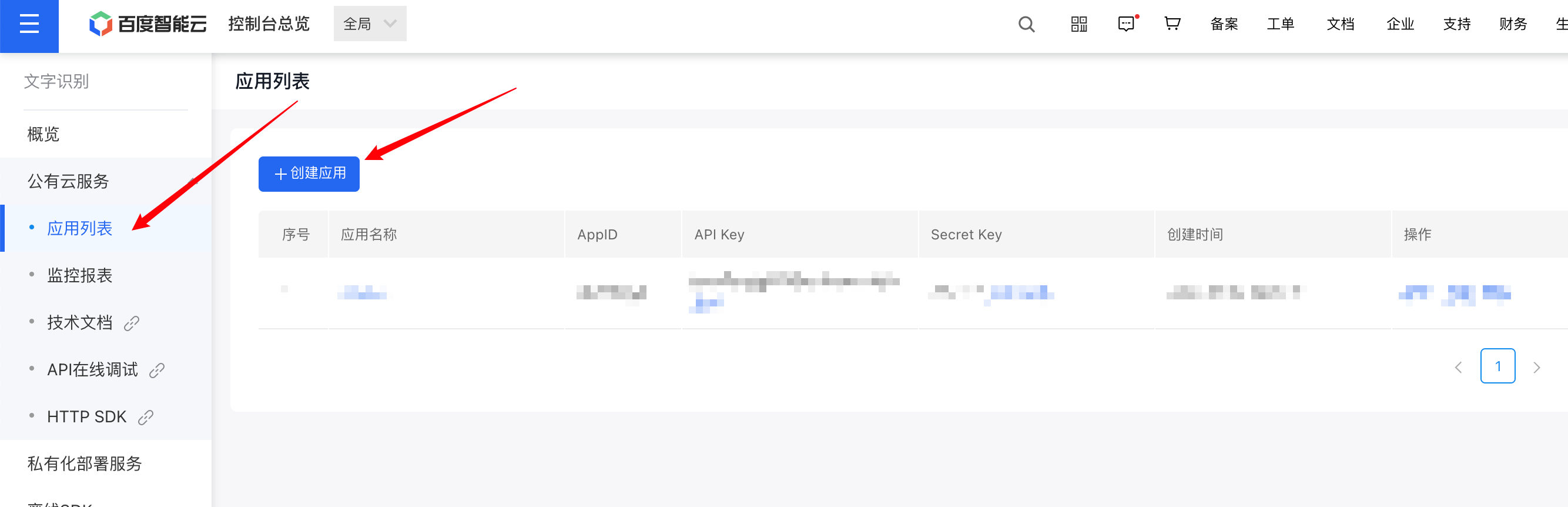
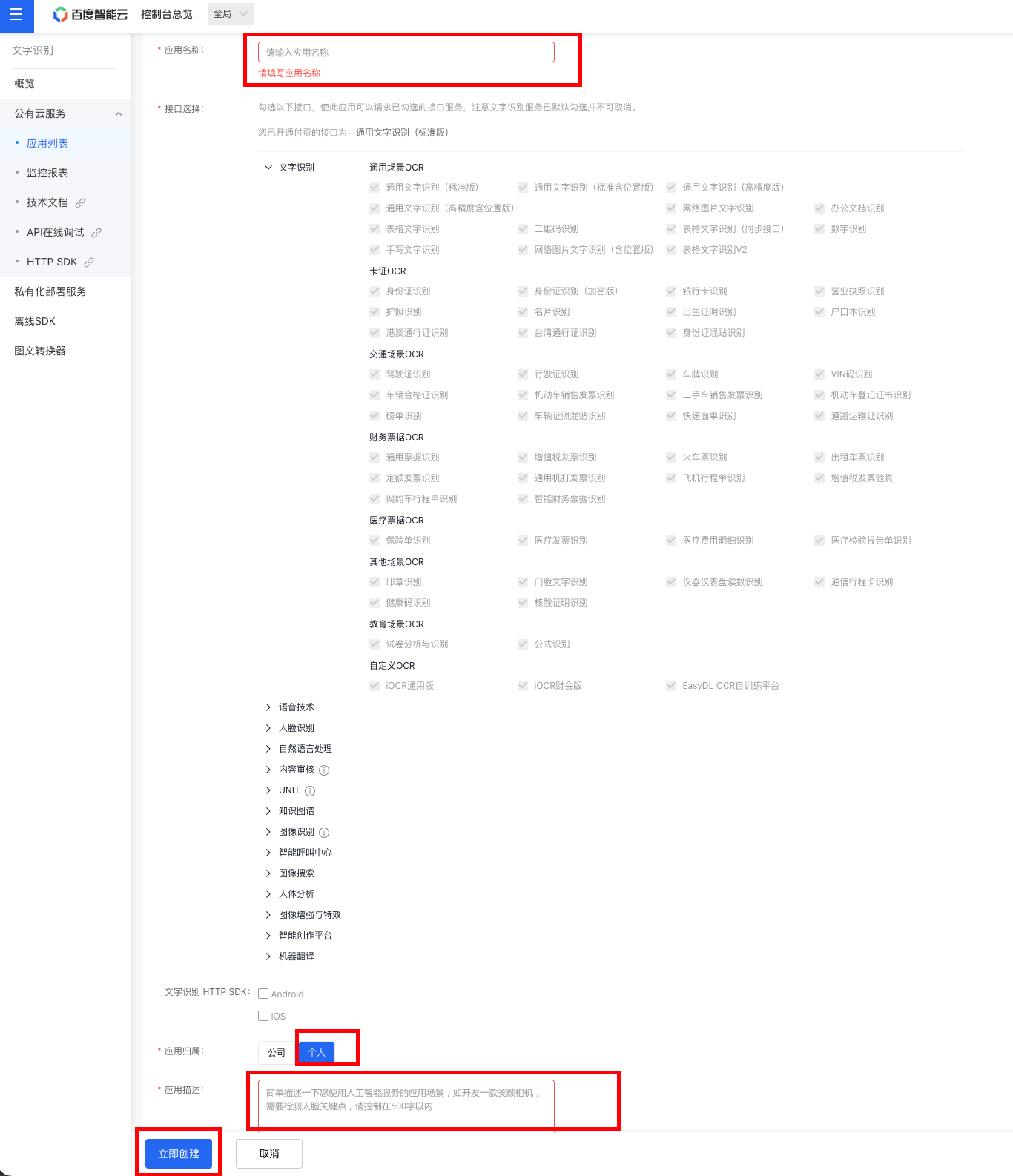
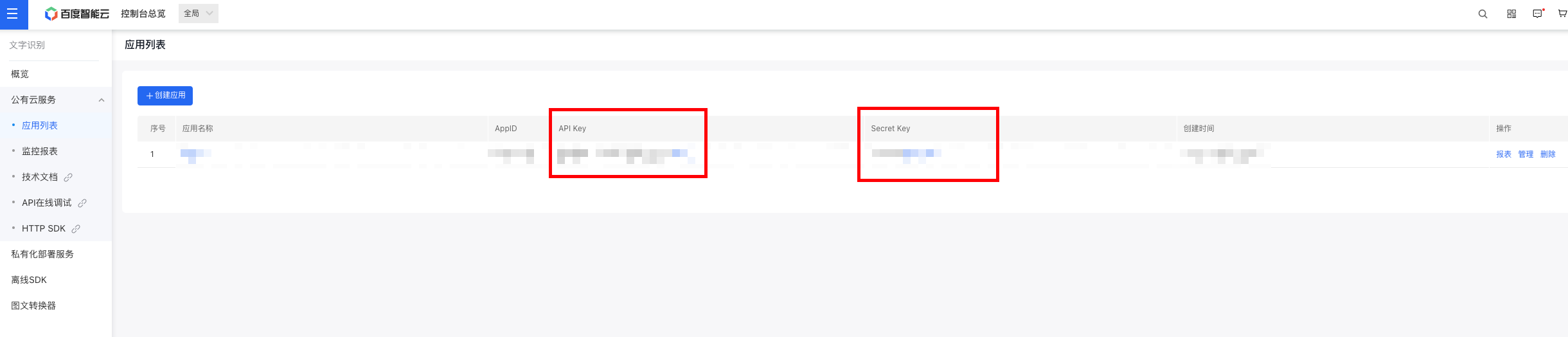
创建成功后就获得了API Key 和 Secret Key
这篇关于阿里云OSS图床和百度OCR获取ak, sk的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





