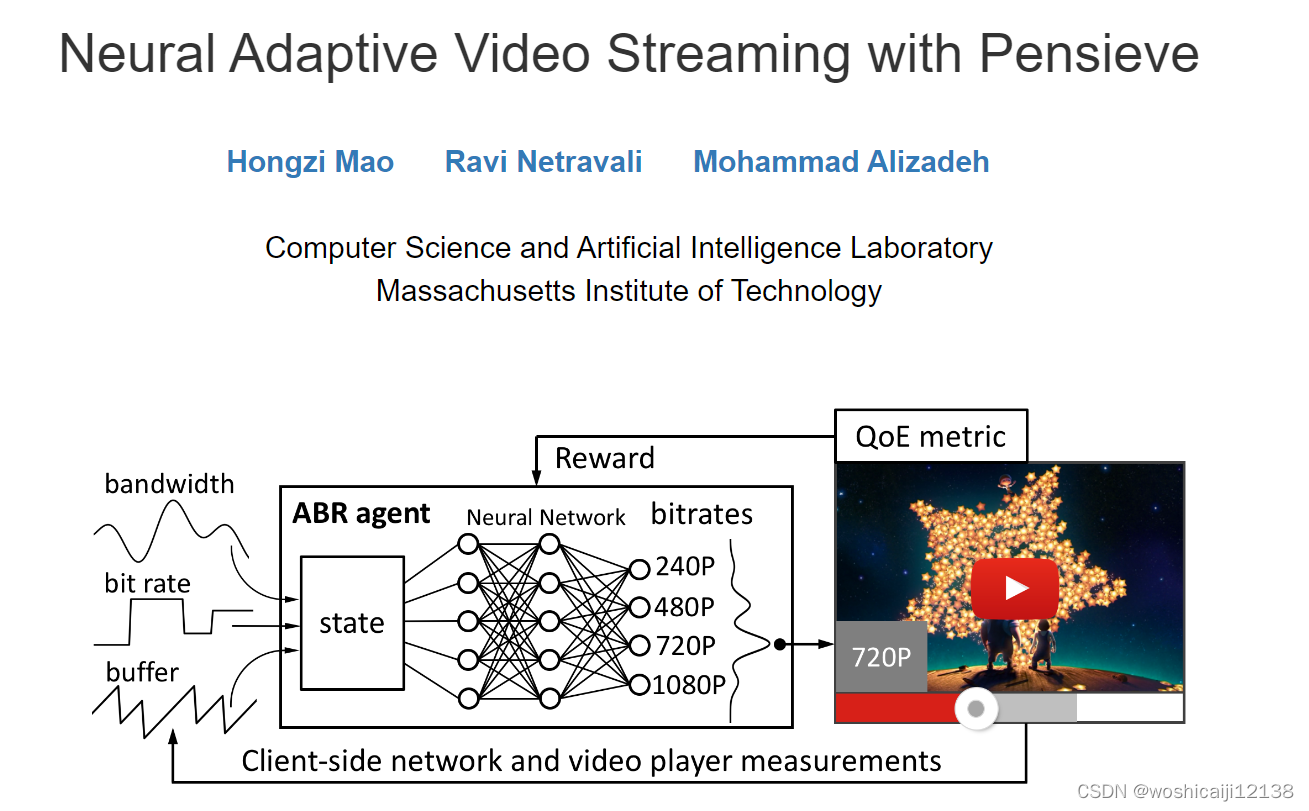
本文主要是介绍pensieve运行的经验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1运行run_videopy时出现如下问题:
cmd: Union[List[str], str], ^ SyntaxError: invalid syntax
原因是EasyProcess版本与python版本不对应,解决办法可见之前这篇博客:SyntaxError: invalid syntax。
2解决完上述问题后,输入命令 python run_video.py RL 2 0结果又出现了新的错误:

出错的原因在chromedriver上,解决办法可见之前这篇博客:Message: ‘chromedriver‘ executable may have wrong permissions.
3之后再运行,如果出现这样的错误:
Message: unknown error: net::ERR_CONNECTION_REFUSED(Session info: chrome=xxx.xxx.xxx.xxx)
解决办法,一是看run_video.py文件中的url设置情况,根据项目中其他文件中的代码设置,一般设置url = 'http://localhost:8333/' + 'myindex_' + abr_algo + '.html'。
若没有上述问题,二是要注意RL方法中使用的模型是否在对应的路径中。
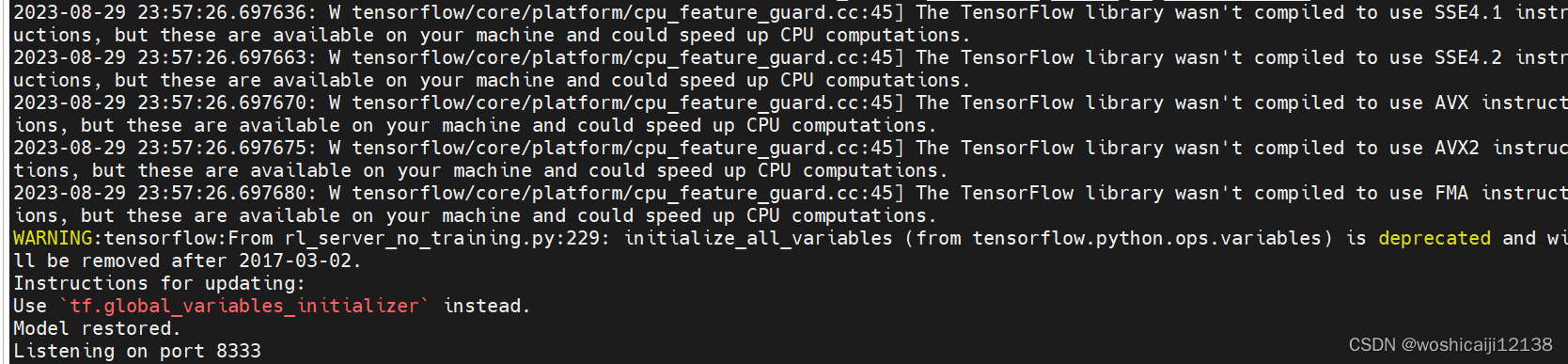
可以单独运行python rl_server_no_training.py 0进行实验,结果发现以下报错:

检查存储模型的目录…/rl_server/results/,发现少了pretrain_linear_reward.ckpt.index文件,立即去github上重新下载一个。
然后再运行 python rl_server_no_training.py 0,结果如下,解决。
4是按照项目Real-world experiments中的说明运行后,发现无法得出结果。
项目内说明:
To run real-world experiments, first setup a server (setup.py automatically installs an apache server and put needed files in /var/www/html). Then, copy over the trained model to rl_server/results and modify the NN_MODEL filed of rl_server/rl_server_no_training.py. Next, modify the url field in real_exp/run_video.py to the server url. Finally, in real_exp/ run
python run_exp.py
The results will be saved to real_exp/results folder. More details can be found in real_exp/README.md.
5 本地测试pensieve代码中rl_server_no_training.py的交互功能
当我在postman中设置好Body

并输入post的内容:‘{“RebufferTime”:1,“lastquality”:1,“lastChunkFinishTime”:1,“lastChunkStartTime”:1,“lastChunkSize”:1,“buffer”:1}’。不过post后postman出现错误:
Error: socket hang up
服务器出现报错:
File "E:\anaconda\envs\pensieve\lib\json\decoder.py", line 382, in raw_decoderaise ValueError("No JSON object could be decoded")
ValueError: No JSON object could be decoded
Postman 错误 “Error: socket hang up”:
这个错误通常是因为服务器在处理请求时遇到了问题并关闭了连接,可能是由于代码中的异常引起的。
服务器端错误 “ValueError: No JSON object could be decoded”:
这个错误是因为服务器尝试解析POST请求中的JSON数据时失败了。POST请求中包含JSON数据,但在服务器端尝试解析它时出现问题。第二个问题似乎是导致第一个问题的原因。
遇到这种情况首先检查Postman中的请求头,确保 Content-Type 设置为 “application/json”,以指示服务器接收JSON数据。此外还要注意postman中传输数据的格式,我传输内容设置为’{“RebufferTime”:1,“lastquality”:1,“lastChunkFinishTime”:1,“lastChunkStartTime”:1,“lastChunkSize”:1,“buffer”:1}',这是导致错误的原因。应该直接以字典传书就可以:{“RebufferTime”:1,“lastquality”:1,“lastChunkFinishTime”:1,“lastChunkStartTime”:1,“lastChunkSize”:1,“buffer”:1}。
Send之后:
问题解决。
当然以上post内容设置适用于postman软件,如果是在python中发送post内容,则要注意了:
import requests
url = 'http://x.x.x.x:x'
# data = {"x":1,"xx":1,"xxx":1,"xxxx":1,"xxxxx":1,"xxxxxx":1} 错误
data = '{"x":1,"xx":1,"xxx":1,"xxxx":1,"xxxxx":1,"xxxxxx":1}'
response = requests.post(url, data=data)
if response.status_code == 200:print('Request successful')print('Response content:', response.text)
else:print('Request failed with status code:', response.status_code)此时data不能为字典,需是字符串,否则服务器也会出现错误:
raise ValueError("No JSON object could be decoded")
ValueError: No JSON object could be decoded
发送端代码会出现错误:
requests.exceptions.ConnectionError: ('Connection aborted.', BadStatusLine("''",))
正确的反馈:

6 向pensieve代码中rl_server_no_training.py发送post
利用python向后台运行中的rl_server_no_training.py发送post,出现报错:
Traceback (most recent call last):File "test.py", line 4, in <module>response = requests.post(url, data=data)File "/home/xxx/anaconda3/envs/pensieve/lib/python2.7/site-packages/requests/api.py", line 117, in postreturn request('post', url, data=data, json=json, **kwargs)File "/home/xxx/anaconda3/envs/pensieve/lib/python2.7/site-packages/requests/api.py", line 61, in requestreturn session.request(method=method, url=url, **kwargs)File "/home/xxx/anaconda3/envs/pensieve/lib/python2.7/site-packages/requests/sessions.py", line 529, in requestresp = self.send(prep, **send_kwargs)File "/home/xxx/anaconda3/envs/pensieve/lib/python2.7/site-packages/requests/sessions.py", line 645, in sendr = adapter.send(request, **kwargs)File "/home/xxx/anaconda3/envs/pensieve/lib/python2.7/site-packages/requests/adapters.py", line 501, in sendraise ConnectionError(err, request=request)
requests.exceptions.ConnectionError: ('Connection aborted.', BadStatusLine("''",))这个问题好办,我们检查rl_server_no_training.py那边的情况:
Traceback (most recent call last):File "rl_server_no_training.py", line 298, in <module>main()File "rl_server_no_training.py", line 293, in mainrun()File "rl_server_no_training.py", line 279, in runhttpd = server_class(server_address, handler_class)File "/home/xxx/lib/python2.7/SocketServer.py", line 417, in __init__self.server_bind()File "/home/xxx/envs/pensieve/lib/python2.7/BaseHTTPServer.py", line 108, in server_bindSocketServer.TCPServer.server_bind(self)File "/home/xxx/anaconda3/envs/pensieve/lib/python2.7/SocketServer.py", line 431, in server_bindself.socket.bind(self.server_address)File "/home/xxx/anaconda3/envs/pensieve/lib/python2.7/socket.py", line 228, in methreturn getattr(self._sock,name)(*args)
socket.error: [Errno 98] Address already in use地址被占用,rl_server_no_training.py压根没运行成功。
这里利用sudo lsof -i :端口号显示使用系统上端口的进程及其相关网络连接的列表;然后利用kill -9 进程号关闭即可。
7 在代码中增加log记录
为了以后方便在服务器代码运行中检测到错误与问题,决定在服务器代码中加入log记录。
以rl_server_no_training.py为例,首先:
import logging
logging.basicConfig(filename='nohup.out', level=logging.DEBUG)
logger = logging.getLogger('server')
def make_request_handler(input_dict):class Request_Handler(BaseHTTPRequestHandler):def __init__(self, *args, **kwargs):self.input_dict = input_dictself.sess = input_dict['sess']self.log_file = input_dict['log_file']self.actor = input_dict['actor']self.critic = input_dict['critic']self.saver = input_dict['saver']self.s_batch = input_dict['s_batch']self.a_batch = input_dict['a_batch']self.r_batch = input_dict['r_batch']BaseHTTPRequestHandler.__init__(self, *args, **kwargs)def do_POST(self):logger.info('Received a POST request')# 省略logger.debug('Received POST data: %s', post_data)
我开始在run中添加log:(错误做法)
def make_request_handler(input_dict):class Request_Handler(BaseHTTPRequestHandler):def __init__(self, *args, **kwargs):self.input_dict = input_dictself.sess = input_dict['sess']self.log_file = input_dict['log_file']self.actor = input_dict['actor']self.critic = input_dict['critic']self.saver = input_dict['saver']self.s_batch = input_dict['s_batch']self.a_batch = input_dict['a_batch']self.r_batch = input_dict['r_batch']BaseHTTPRequestHandler.__init__(self, *args, **kwargs)def do_POST(self):logger.info('Received a POST request')def run(server_class=HTTPServer, port=8334, log_file_path=LOG_FILE):np.random.seed(RANDOM_SEED)logging.basicConfig(filename='nohup.out', level=logging.DEBUG)logger = logging.getLogger('server')# 省略handler_class = make_request_handler(input_dict=input_dict)但是报错:
File "rl_server_no_training.py", line 75, in do_POSTlogger.info('Received a POST request')
NameError: global name 'logger' is not defined
要使记录器变量在两个函数中都可访问,您可以在更高的范围内定义它,如在模块级别。
请确保将此代码放在脚本的开头,放在使用记录器变量的任何函数或类之前。
修改之后,成功显示记录!

8 浏览器向服务器发送POST请求中因CORS(跨域资源共享)问题导致的net::ERR_FAILED错误
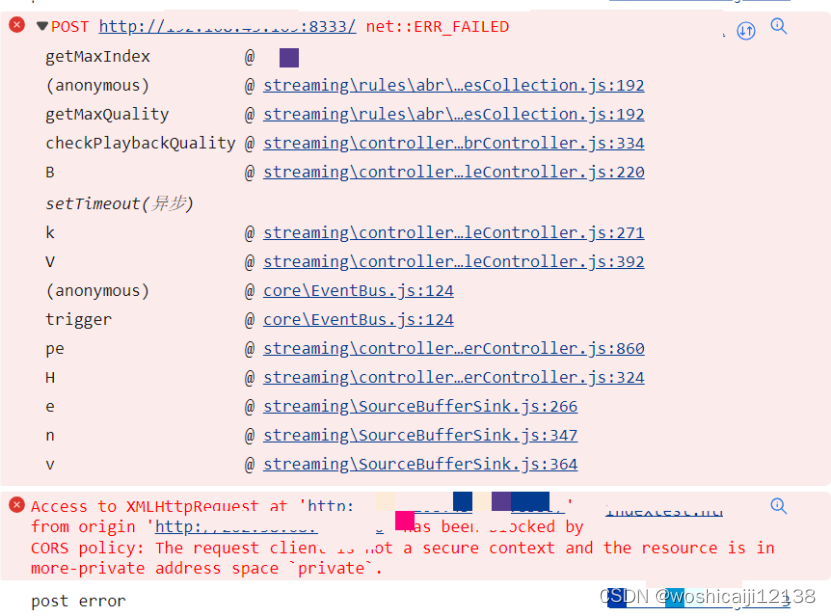
如上图所示,使用浏览器向服务器发送POST请求时出现net::ERR_FAILED错误,经排查是因CORS(跨域资源共享)问题导致。
检查js代码,发现httpRequest.setRequestHeader("Content-type","application/json"),而CORS中的简单请求(Simple Request)要求头只能是text/plain、multipart/form-data、application/x-www-form-urlencoded。
所以我们需要将Content-type设置为application/x-www-form-urlencoded。
原来的代码许多也需要修改,下面是一个示例:
Content-type为application/json时的版本:
const url='http://xxx.xxx.xxx.xxx:8333/';var dict={'RebufferTime':rebuffertime,'lastquality':lastQuality,'lastChunkFinishTime':lastChunkFinishTime,'lastChunkStartTime':lastChunkStartTime,'lastChunkSize':lastChunkSize};console.log(dict)var encodedData = encodeFormData(dict);console.log(encodedData)var httpRequest = new XMLHttpRequest();httpRequest.open('POST',url,true);httpRequest.setRequestHeader("Content-type","application/x-www-form-urlencoded");// httpRequest.setRequestHeader("Content-type","application/json");httpRequest.send(JSON.stringify(encodedData));
Content-type为application/x-www-form-urlencoded时的版本:
function encodeFormData(data) {const formData = new URLSearchParams();for (const key in data) {formData.append(key, data[key]);}return formData.toString();}const url='http://xxx.xxx.xxx.xxx:8333/';var dict={'RebufferTime':rebuffertime,'lastquality':lastQuality,'lastChunkFinishTime':lastChunkFinishTime,'lastChunkStartTime':lastChunkStartTime,'lastChunkSize':lastChunkSize};console.log(dict)var encodedData = encodeFormData(dict);console.log(encodedData)var httpRequest = new XMLHttpRequest();httpRequest.open('POST',url,true);httpRequest.setRequestHeader("Content-type","application/x-www-form-urlencoded");// httpRequest.setRequestHeader("Content-type","application/json");//httpRequest.send(JSON.stringify(encodedData));httpRequest.send(encodedData.toString());
服务器接收端的代码也需要修改,如下是可以正常运行的版本:
content_length = int(self.headers['Content-Length'])
postdata=self.rfile.read(content_length)
parsed_data = parse_qs(postdata)
# 将列表中的字符串转换为浮点数或整数
for key, value_list in parsed_data.items():if key == 'RebufferTime' or key == 'lastChunkFinishTime' or key == 'lastChunkStartTime':parsed_data[key] = float(value_list[0])else:parsed_data[key] = int(value_list[0])
因为接收到的postdata是字符串,例如:“RebufferTime=0.014999866485595703&lastquality=1&lastChunkFinishTime=1696524371.103&lastChunkStartTime=1696524371.088&lastChunkSize=66752”
9 parsed_data = parse_qs(postdata)可能遇到的错误:SyntaxError
parsed_data = parse_qs(postdata)是使用urlparse解析数据字符串,使之转换成字典。
运行parsed_data = parse_qs(postdata)时也有可能出现报错:SyntaxError: Non-ASCII character '\xe7' in file D:/xxx ��Ŀdebug/test3.py on line 3, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
这个错误表明Python脚本文件中包含了非ASCII字符,但是没有指定文件的编码方式。在Python 2.7中,默认的源文件编码是ASCII,如果文件中包含非ASCII字符,就需要在文件的开头声明文件编码。
要解决这个问题,可以在脚本文件的开头添加编码声明,以指定文件的编码方式。例如,如果文件使用UTF-8编码,可以这样声明:
# -*- coding: utf-8 -*-
from urlparse import urlparse, parse_qs
# 示例数据字符串
data_string = "RebufferTime=0.014999866485595703&lastquality=1&lastChunkFinishTime=1696524371.103&lastChunkStartTime=1696524371.088&lastChunkSize=66752"
# 使用urlparse解析数据字符串
parsed_data = parse_qs(data_string)
# 输出转换后的字典
print(parsed_data)10 开启rl_server_no_training.py服务器时的socket.error: [Errno 10049]错误
今天在pycharm运行rl_server_no_training.py欲启动服务器时,却出现如下错误
Traceback (most recent call last):File "xxx/rl_server_no_training.py", line 333, in <module>main()File "xxx/rl_server_no_training.py", line 326, in mainrun(log_file_path=LOG_FILE + '_RL_' + trace_file)File "xxx/rl_server_no_training.py", line 314, in runhttpd = server_class(server_address, handler_class)File "xx\anaconda\envs\pensieve\lib\SocketServer.py", line 420, in __init__self.server_bind()File "xx\anaconda\envs\pensieve\lib\BaseHTTPServer.py", line 108, in server_bindSocketServer.TCPServer.server_bind(self)File "xx\anaconda\envs\pensieve\lib\SocketServer.py", line 434, in server_bindself.socket.bind(self.server_address)File "xx\anaconda\envs\pensieve\lib\socket.py", line 228, in methreturn getattr(self._sock,name)(*args)
socket.error: [Errno 10049] Process finished with exit code 1解决办法可见:socket.error: [Errno 10049]错误解决。
这篇关于pensieve运行的经验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








