本文主要是介绍武汉理工大学2019计算机分数线,武汉理工大学录取分数线2019(在各省市录取数据)...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

武汉理工大学是首批列入国家“211工程”重点建设的教育部直属全国重点大学,首批列入国家“双一流计划”建设高校,教育部和交通运输部、国家国防科技工业局共建高校。
学校现有马房山校区、余家头校区和南湖校区,占地近4000亩,校舍总建筑面积174.59万平方米,4座现代化图书馆藏书309.41万册。设有25个学院(部),4个国家重点实验室(工程中心)。
学校已形成以工学为主,理、工、经、管、艺术、文、法等多学科相互渗透、协调发展的学科专业体系。现有一级学科博士学位授权点19个,一级学科硕士学位授权点46个,博士后科研流动站17个;材料学科、工程学科和化学学科进入了世界ESI学科排名的前5‰。
2020高考,想要报考武汉理工大学的同学注意了,老师给大家整理了该校2019年在各省市的录取分数线。大家可以参照一下,对比自己目前的水平,还有多少差距,还要付出多少努力,做到心中有数。
武汉理工大学2019年在各省市的录取分数线汇总
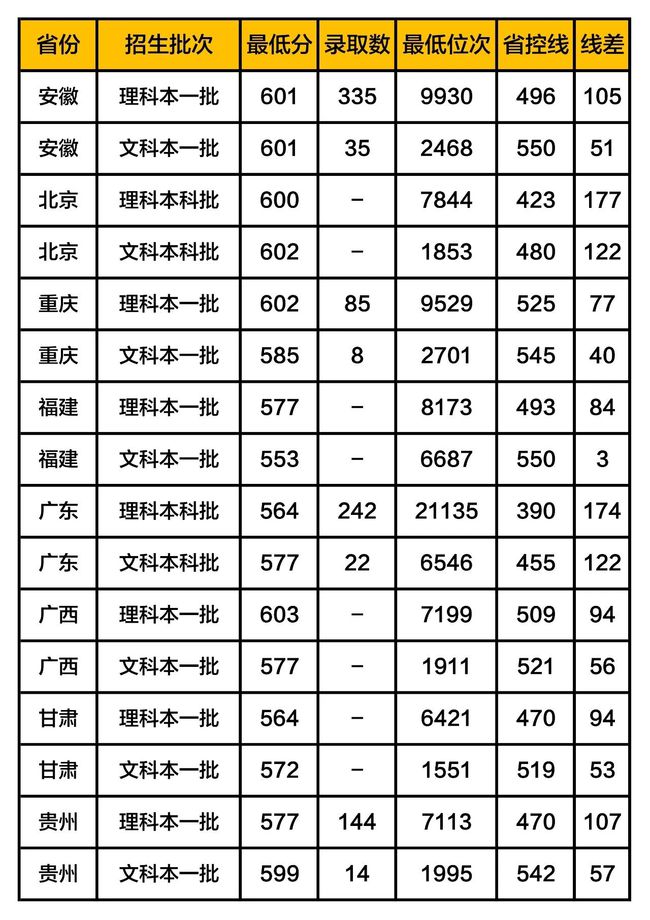
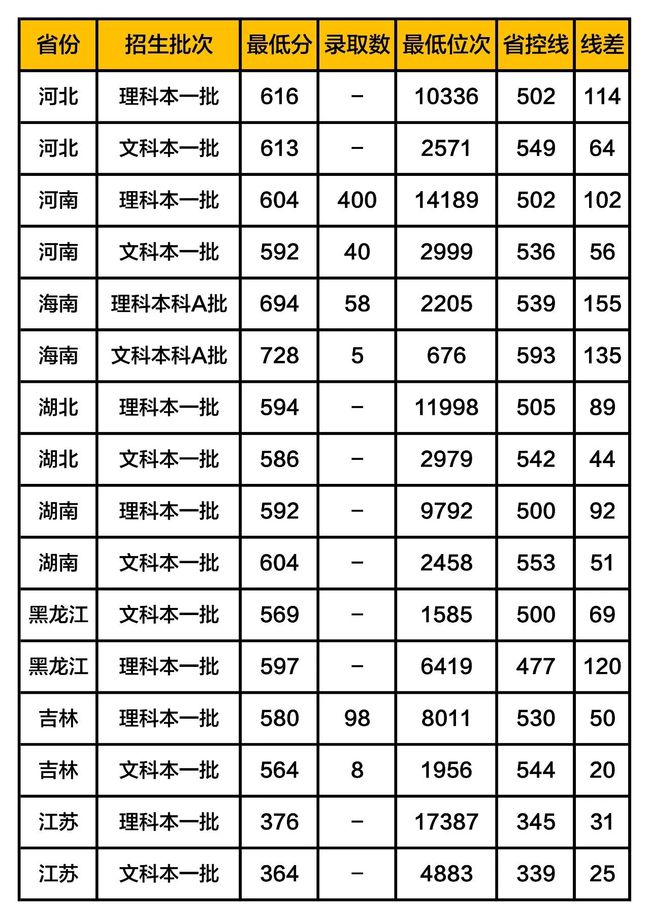
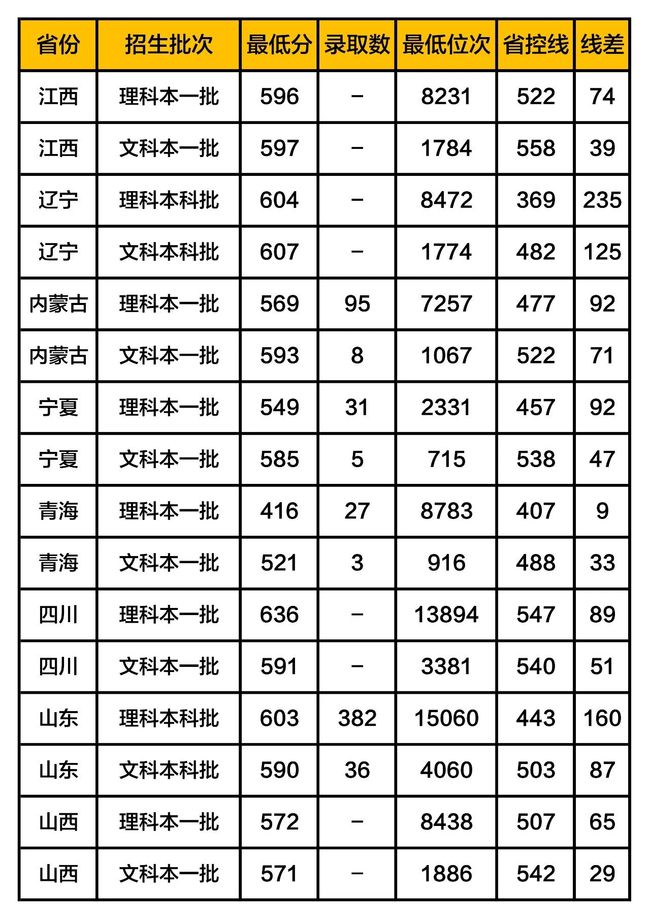
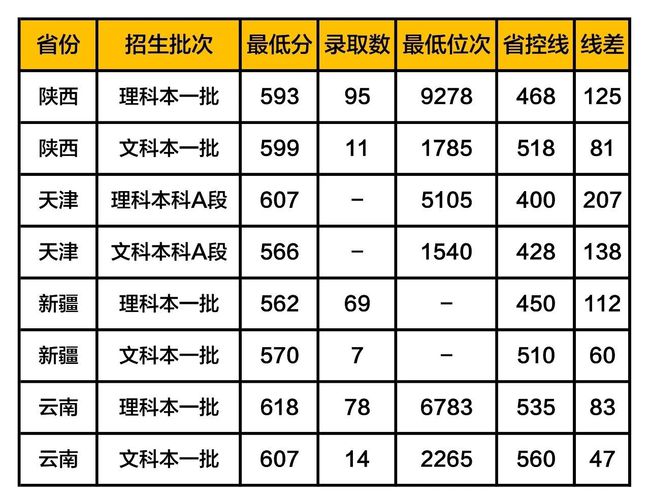
其他高校录取数据,请查看之前发布的文章
知识点补充:
1. 最低分:当年该校在本省对应批次录取的考生中,最后一名考生的分数;
2. 最低位次:当年该校在本省对应批次录取的考生中,最后一名考生在本省的排名;
3. 省控线:本省高考该批次的分数线,比如:一本线;
4. 线差:当年该校在本省对应批次的录取最低分与本省高考该批次分数线的差值。
寒窗苦读数十载,只为金榜题名时。2020高考冲鸭!!!
志愿填报郭老师:每日更新高校历年录取数据,为高中生填报志愿做参考,欢迎关注
这篇关于武汉理工大学2019计算机分数线,武汉理工大学录取分数线2019(在各省市录取数据)...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







