本文主要是介绍自动根据数据生成降雨量实况Word报告,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:小小明
最近遇到一个有点烧脑的需求,其实也不算烧脑,主要是判断条件过多,对于我这种记忆力差,内存小的人来说容易出现内存溢出导致大脑宕机。也可能是因为我还没有找到能减小大脑内存压力的写法。
若读者有啥更好解决方案,欢迎评论噢!
先看看需求吧:

主要就是要根据左侧的表格自动生成右侧的word统计报告,实际的各种可能性情况远比图中展示的要更加复杂。
好了,直接开始干代码吧:
数据读取
import pandas as pddf = pd.read_csv("11月份数据.csv", encoding='gbk')
# 当前统计月份
month = 11
df = df.query('月份==@month')
df
数据:
| 区域 | 月份 | 降雨量(mm) | 降雨距平(mm) | 观测站 | |
|---|---|---|---|---|---|
| 0 | 6e63e | 11 | 2.9 | -0.70 | A站 |
| 1 | 1b8dd | 11 | 1.0 | -3.40 | A站 |
| 2 | 7c6a0 | 11 | 2.3 | -3.04 | A站 |
| 3 | 548ad | 11 | 8.5 | 0.10 | A站 |
| 4 | 1bafe | 11 | 8.7 | 2.20 | A站 |
| 5 | 51a45 | 11 | 16.0 | 7.41 | A站 |
| 6 | 53f42 | 11 | 6.8 | 1.10 | A站 |
| 7 | 4f644 | 11 | 1.8 | -0.60 | A站 |
| 8 | 60a75 | 11 | 0.0 | -2.60 | A站 |
| 9 | 4319d | 11 | 1.4 | -2.20 | A站 |
| 10 | 62464 | 11 | 2.2 | -1.00 | A站 |
| 11 | 65cb4 | 11 | 2.0 | -1.00 | A站 |
| 12 | e68da | 11 | 1.2 | -1.40 | A站 |
| 13 | 4156e | 11 | 3.1 | -0.40 | A站 |
| 14 | 1cc6d | 11 | 3.3 | -2.00 | A站 |
| 15 | 16d40 | 11 | 0.0 | -0.50 | B站 |
| 16 | 54ac3 | 11 | 3.2 | 0.00 | B站 |
| 17 | 592ac | 11 | 4.1 | -0.20 | B站 |
| 18 | 32046 | 11 | 5.3 | 1.10 | B站 |
| 19 | 4e6f0 | 11 | 1.2 | 0.50 | B站 |
| 20 | 3722c | 11 | 3.5 | 1.40 | C站 |
| 21 | 5379c | 11 | 1.3 | -2.90 | C站 |
| 22 | 51eed | 11 | 3.2 | -0.60 | C站 |
| 23 | 2d91d | 11 | 2.8 | 0.90 | D站 |
| 24 | 78896 | 11 | 5.1 | 1.60 | D站 |
| 25 | 25464 | 11 | 5.5 | 1.50 | D站 |
| 26 | 66955 | 11 | 0.3 | -3.10 | D站 |
| 27 | 7639e | 11 | 0.0 | -1.10 | D站 |
| 28 | 1c5ff | 11 | 0.6 | -0.90 | D站 |
| 29 | ec456 | 11 | 12.2 | NaN | E站 |
| 30 | 29b6b | 11 | 7.3 | 4.00 | E站 |
| 31 | 220de | 11 | 12.2 | 9.10 | E站 |
| 32 | 3b5f0 | 11 | 13.6 | 7.25 | E站 |
异常数据过滤
查看缺失值数量:
pd.isnull(df).sum()
结果:
区域 0
月份 0
降雨量(mm) 0
降雨距平(mm) 1
观测站 0
dtype: int64
仅一个缺失值数据,可直接删除:
df.dropna(inplace=True)
计算所有观测站降雨量相对往年的比较
计算降雨量比往年高,跟往年比无变化,以及比往年低的次数分别是多少:
rainfall_high = df.eval('`降雨距平(mm)` > 0').value_counts().get(True, 0)
rainfall_equal = df.eval('`降雨距平(mm)` == 0').value_counts().get(True, 0)
rainfall_low = df.eval('`降雨距平(mm)` < 0').value_counts().get(True, 0)
print(rainfall_high, rainfall_equal, rainfall_low)
13 1 18
上面的结果中rainfall_high表示降雨量比往年平均水平高的次数,rainfall_equal表示降雨量比往年平均水平持平的次数,rainfall_low表示降雨量比往年平均水平低的次数。
于是分情况讨论生成第一段的报告:
p1 = f"{month}月份"
if rainfall_low == 0 or rainfall_high == 0:if rainfall_equal != 0:p1 += f"除{rainfall_equal}个观测站降雨量较往年无变化外,"if rainfall_high == 0:p1 += f"各气象观测站降雨量较往年均偏低。"elif rainfall_low == 0:p1 += f"各气象观测站降雨量较往年均偏高。"
else:# 10%以内差异认为是持平if rainfall_high > rainfall_low*1.1:p1 += f"大部分气象观测站降雨量较往年偏高。"elif rainfall_low > rainfall_high*1.1:p1 += f"大部分气象观测站降雨量较往年偏低。"else:p1 += f"各气象观测站降雨量较往年整体持平。"
p1
结果:
'11月份大部分气象观测站降雨量较往年偏低。'
计算各区域降雨量的极值
再生成第二段的报告:
p2 = ""
t = df['降雨量(mm)']
p2 += f"各区域降雨量在{t.min()}~{t.max()}mm之间,其中{df.loc[t.argmax(), '区域']}区域的降雨量最大,为{t.max()}mm。"
p2
结果:
'各区域降雨量在0.0~16.0mm之间,其中51a45区域的降雨量最大,为16.0mm。'
分观测站统计
让我脑袋疼的地方就是从这里的代码开始的,后面还有更复杂蛋疼的需求就不公布了。
对每个观测站分别统计哪些区域偏高,哪些区域持平,哪些区域偏低:
p3s = []
for station, tmp in df.groupby('观测站'):t = tmp['降雨量(mm)']p3 = f"各区域降雨量在{t.min()}~{t.max()}mm之间,"rainfall_high_mask = tmp.eval('`降雨距平(mm)` > 0')rainfall_equal_mask = tmp.eval('`降雨距平(mm)` == 0')rainfall_low_mask = tmp.eval('`降雨距平(mm)` < 0')rainfall_high = rainfall_high_mask.value_counts().get(True, 0)rainfall_equal = rainfall_equal_mask.value_counts().get(True, 0)rainfall_low = rainfall_low_mask.value_counts().get(True, 0)
# print(rainfall_high, rainfall_equal, rainfall_low)if rainfall_low == 0 or rainfall_high == 0:if rainfall_equal != 0:p3 += '除'p3 += '、'.join(tmp.loc[rainfall_equal_mask, '区域']+'区域')p3 += "降雨量较往年无变化外,"if rainfall_high == 0:p3 += f"各区域降雨量均较往年偏低"elif rainfall_low == 0:p3 += f"各区域降雨量均较往年偏高"t = tmp['降雨距平(mm)'].abs()p3 += f"{t.min()}~{t.max()}mm;"else:if rainfall_equal != 0:p3 += '除'p3 += '、'.join(tmp.loc[rainfall_equal_mask, '区域']+'区域')p3 += "降雨量较往年无变化,"# 10%以内差异认为是持平if rainfall_high > rainfall_low*1.1:if rainfall_equal == 0:p3 += '除'p3 += '、'.join(tmp.loc[rainfall_low_mask, '区域']+'区域')p3 += "降雨量较往年偏低"t = tmp.loc[rainfall_low_mask, '降雨距平(mm)'].abs()if t.shape[0] > 1:p3 += f"{t.min()}~{t.max()}mm"else:p3 += f"{t.min()}mm"p3 += "外,"t = tmp.loc[rainfall_high_mask, '降雨距平(mm)'].abs()p3 += f"其余各区域降雨量较往年偏高{t.min()}~{t.max()}mm;"elif rainfall_low > rainfall_high*1.1:if rainfall_equal == 0:p3 += '除'p3 += '、'.join(tmp.loc[rainfall_high_mask, '区域']+'区域')p3 += "降雨量较往年偏高"t = tmp.loc[rainfall_high_mask, '降雨距平(mm)'].abs()if t.shape[0] > 1:p3 += f"{t.min()}~{t.max()}mm"else:p3 += f"{t.min()}mm"p3 += "外,"t = tmp.loc[rainfall_low_mask, '降雨距平(mm)'].abs()p3 += f"其余各区域降雨量较往年偏低{t.min()}~{t.max()}mm;"else:if rainfall_equal != 0:p3 = p3[:-1]+'外,'p3 += f"各区域降雨量较往年偏高和偏低的数量持平,其中"p3 += '、'.join(tmp.loc[rainfall_low_mask, '区域']+'区域')p3 += "降雨量较往年偏低"t = tmp.loc[rainfall_low_mask, '降雨距平(mm)'].abs()if t.shape[0] > 1:p3 += f"{t.min()}~{t.max()}mm,"else:p3 += f"{t.min()}mm,"p3 += '、'.join(tmp.loc[rainfall_high_mask, '区域']+'区域')p3 += "降雨量较往年偏高"t = tmp.loc[rainfall_high_mask, '降雨距平(mm)'].abs()if t.shape[0] > 1:p3 += f"{t.min()}~{t.max()}mm;"else:p3 += f"{t.min()}mm;"p3s.append([station, p3])
p3s[-1][-1] = p3s[-1][-1][:-1]+"。"
p3s
结果:
[['A站','各区域降雨量在0.0~16.0mm之间,除548ad区域、1bafe区域、51a45区域、53f42区域降雨量较往年偏高0.1~7.41mm外,其余各区域降雨量较往年偏低0.4~3.4mm;'],['B站','各区域降雨量在0.0~5.3mm之间,除54ac3区域降雨量较往年无变化外,各区域降雨量较往年偏高和偏低的数量持平,其中16d40区域、592ac区域降雨量较往年偏低0.2~0.5mm,32046区域、4e6f0区域降雨量较往年偏高0.5~1.1mm;'],['C站', '各区域降雨量在1.3~3.5mm之间,除3722c区域降雨量较往年偏高1.4mm外,其余各区域降雨量较往年偏低0.6~2.9mm;'],['D站','各区域降雨量在0.0~5.5mm之间,各区域降雨量较往年偏高和偏低的数量持平,其中66955区域、7639e区域、1c5ff区域降雨量较往年偏低0.9~3.1mm,2d91d区域、78896区域、25464区域降雨量较往年偏高0.9~1.6mm;'],['E站', '各区域降雨量在7.3~13.6mm之间,各区域降雨量均较往年偏高4.0~9.1mm。']]
可能是我还没有想出较好的封装方式导致代码变得这么复杂,如果有巧妙解决这个问题方法的朋友,希望能够一起探讨。
将组织好的文本写入到word文档中
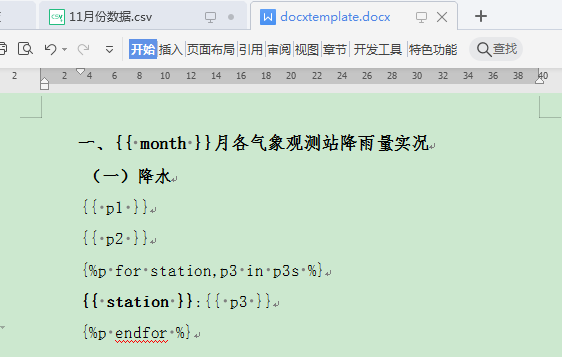
word模板文件docxtemplate.docx的内容:
一、{{ month }}月各气象观测站降雨量实况
(一)降水
{{ p1 }}
{{ p2 }}
{%p for station,p3 in p3s %}
{{ station }}:{{ p3 }}
{%p endfor %}
即:
python渲染代码:
from docxtpl import DocxTemplatetpl = DocxTemplate("docxtemplate.docx")
context = {'month': month,'p1': p1,'p2': p2,'p3s': p3s,
}
tpl.render(context)
tpl.save("11月降雨量报告.docx")
执行完毕,得到word报告:

这篇关于自动根据数据生成降雨量实况Word报告的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







