本文主要是介绍实验报告——Nachos 进程管理与调度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 实验目的
(1) 掌握进程管理与同步:实现fork、exec、join 系统调用。
(2) 掌握进程调度:实现优先级调度。
2. 实验内容 运用理论课上学习的 fork、exec、waitpid / join 等系统调用的工作原理,在 Nachos 上实现进程的管理、同步与调度。主要包含以下几点: 1. 实现 fork、exec、join系统调用. 2. 实现进程优先级调度. 3. 编写一个简单的 Nachos shell.
3. 具体实现
(1) part1——三种系统调用的实现
i. fork 的实现 function:创建一个子进程
fork 在 exception.cc 的中断中的操作实际上就是调用了 SysFork(),然后写回返回值,更新 pc,这里略去代码,直接通过注释来讲解 SysFork()的关键代码。
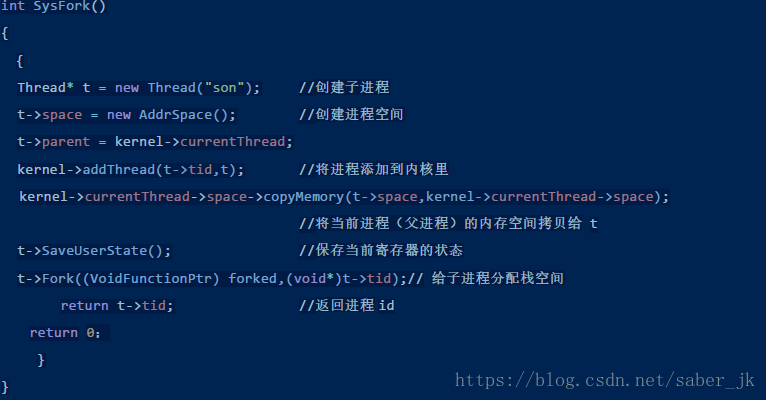
这里调用了 t->fork(),这个函数定义如下:
void Thread::Fork(VoidFunctionPtr func, void *arg)
看其注释:

所以我们这里分配栈空间,直接调用了 forked(),如下
void forked(int arg)
{
{
kernel->currentThread->RestoreUserState(); //寄存器状态恢复
kernel->currentThread->space->RestoreState(); //进程空间恢复
kernel->machine->WriteRegister(2,0); //写返回值
kernel->machine->PCplusPlus(); //PC 指向下一条指令
kernel->machine->Run(); //执行用户空间的代码
}
}
此外,为了使每个被创建的进程有不同的进程 ID,我在 thread.cc 增加了静态变量 idinit 在构造函数里添加代码:
idinit++;
tid = idinit;
ii. Exec的实现function:载入并执行可执行程序 exec 的流程实际比较简单,通过注释讲解:
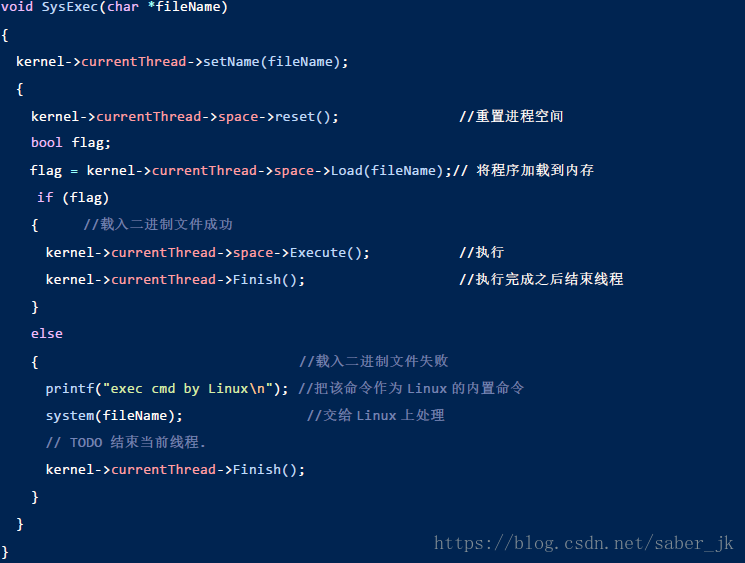
助教提示了执行的部分到 main.cc里学习,我实际上是看到了一个例子,部分代码如下:
if (space->Load(userProgName)) {
// load the program into the space
space->Execute(); // run the program
ASSERTNOTREACHED(); // Execute never returns }
可以看到是执行了 space->Execute();然后我将此借用到了自己代码当中。
iii. Join 的实现
function:令父进程等待子进程执行结束
join 和上面二者不同,基本功能实在 thread.cc 中实现的:
voidThread::join(int tid) { Thread *t; t=kernel->getThreadByID(tid); //获取子进程 if(t) { Semaphore *sem=newSemaphore("debug",0); //新信号量 kernel->currentThread->joinSemMap_insert(tid,sem); //插入joinSemMap sem->P(); //等待信号量 kernel->currentThread->joinSemMap_remove(tid); //移除信号量 } } |

这里有两个操作比较关键:一是对joinSemMap 的操作,这个是通过数据类型map<int,Semaphore>存放线程 ID 和与之对应的信号量信号量,Join 必须通过管理这个 map,才能实现对子进程的信号量的管理。二是 P(),这个函数,实际上主要功能是阻塞当前进程,直到获得信号量。
2) part2——进程优先级调度和 shell 的实现
i.与调度相关的代码理解
本实验中通过对 Scheduler类里的函数 FindNextToRun()进行修改来实现优先级调度的方
法,这个函数的基本功能就是调整优先级,找到下一要运行的进程,并修改相关的进程状态。其具体实现后文结合代码详细介绍。
我们可以发现在 thread.cc中有这样一个函数 Yield(),私以为这个函数相当重要,所以着重讲一下,可以看到,在这个函数中调用了上面说的 FindNextToRun()去找下一个要运行的进程,然后寻找成功,就会对当前进程执行 ReadyToRun(),即把当前进程添加到准备队列中,并且对
nextThread 执行 run(),这个函数里保留了当前进程的上下文,然后 nextThread 的状态被置为 running,读取其上下文开始执行,此不做具体分析。
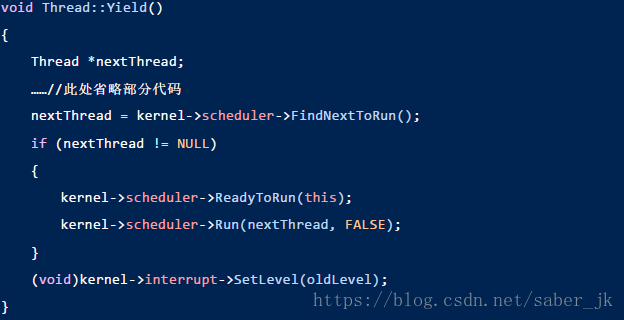
至于调度的时机,显现要找对 Yield()的调用,这个我们在 interrupt.cc中可以找到。
Interrupt::OneTick()
然后看相关注释可以得知,OneTick()执行的时机有两种情况:1.中断被 re-enabled 时 2.每当一条用户指令被执行,所以这也就是调度的时机。
ii.优先级调度的实现
优先级调度是一种允许抢占的进程调度方式,每个进程有一个优先级,通过优先级判断谁先执行,为了避免死锁和饿死,这个优先级是动态变化的,其基本逻辑是,当前进程会随着执行时间变低,而等待队列的进程优先级别会不断增加,这样就确保每个进程都会被执行到。
据此,本实验采用的优先级调整公式为:
#调整当前进程优先级计算公式——priority= priority - (当前系统时间- lastSwitchTick ) /100 #调整所有就绪进程的优先级计算公式—— priority =priority + AdaptPace
下面通过注释的方式去分析优先级调度的代码,理解优先级调度算法的流程:
Thread *Scheduler::FindNextToRun() { 。。。。。。 if (readyList->IsEmpty())//如果没有就绪进程,显然返回NULL { returnNULL; } else { //更新当前线程的优先级 Thread * t; t=kernel->currentThread; t->priority-=(kernel->stats->totalTicks-lastSwitchTick)/100; t->setPriority(t->priority);//依照计算好的优先级进行设置 //刷新所有就绪线程的优先级 flushPriority();//下面会贴出 Print(); //打印当前进程状态 // 计算最近调度与现在的间隔 inttime=kernel->stats->totalTicks-lastSwitchTick; // 间隔太小,返回 NULL (避免过分频繁地调度) if(time<MinSwitchPace) returnNULL; // 就绪队列为空,返回 NULL (没有就绪进程可以调度) if(readyList->IsEmpty()) returnNULL; // 找到优先级最高的就绪态进程t Thread *t1=readyList->Front(); if(threadCompareByPriority(t,t1)==1)//把当前进程和就绪队列的第//一个进程进行比较,决定是否切 //换 { lastSwitchTick = kernel->stats->totalTicks; }//因为将要进行一次进程切换,所以上一次切换时间要用本次切换时间代替 else returnNULL;
return readyList->RemoveFront();//把就绪就列里的第一个进程移除 //并且返回这个进程,即此为下一个 //要调度的进程 }} |
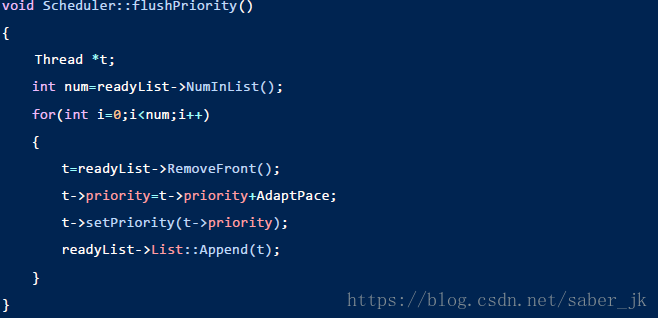
这里是刷新就绪队列进程优先级的代码,原理和公式上面已经讲过,没太多可分析的,作为关键代码贴出:
iii.shell 的简单实现
shell 的逻辑比较简单,首先是从控制台接受指令,通过字符串处理分解命令,得到一个序列,对于这个命令序列,依次创建进行子进程,装载相应的程序代码,这里父进程要等待所有创建的子进程完成之后再继续执行。很显然,只要对子进程调用Exec(),对父进程调用 Join()即可实现相应功能,下面是关键代码,可以看到,十分简单。

iv.测试运行结果

按照上面代码,这里 2进程最先创建,但是最后完成输出,而不是第一个完成,从这里其实就可以看到子进程不是依次执行的,而是有一个调度在里面,至于2 进程最后完成,这是由进程本身的耗时较长导致的(与add 等相比)。
可以看到,刚开始只有 main 进程,然后创建子进程,执行 2,后来又变成 3 个进程,这里没有显示,第三个进程装载了 add 并执行,对应 for 循环里子进程被依次创建。然后我们观察进程的优先级pri,就绪队列里的进程,其优先级以2 的幅度增加,而执行中的进行优先级在不断降低,直到就绪队列优先级最高的进程比当前进程高,进程切换就发生了。
v.part2 中遇到的问题
1.刚开始没有仔细思考完成了 shell 的编写,大致如下:

这样的 shell 是有问题的,可以看到,父进程 main创建了第一个子进程后,就执行 Join(),这样实际上要等第一个进程完成以后才能创建第二个子进程,如此优先级调度完全没有意义了。所以就修改成了上述的代码。
2.关于检查的时候一个问题
问题大致:查看进程切换,为什么执行到中间,main进程消失不见了?
这个问题我之前没有注意到,所以一时间就没有回答上来,而且我注意力在“中间”这个词,理解为还在第一个 for 循环中,没有意识到这个时候进程创建已经完成了,所以回答得很不好。
现在想来实际上比较简单,是因为子进程的创建已经完成了,父进程就执行 Join(),这和时候父进程 main 会阻塞自己,把自己从就绪队列中移出去。
回去之后我又仔细的看了代码,可以发现在join()里调用了 p(),转到 synch.cc 中 p()的定义里,发现
currentThread->Sleep(FALSE);
然后在 sleep()里有:
status = BLOCKED;
这样就很清楚了。只怪自己实验时不够细致,没有意识到考虑到这个问题,然后一问就蒙圈了。
这篇关于实验报告——Nachos 进程管理与调度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


