本文主要是介绍俄文手写字体-初中教材版,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
初中俄语教材上的手写体也不知道哪个“专家”创造的,想把这种手写体放大打印出来,找不到相应的字体或是高清图片。去了战斗民族的网站上废了好大力气找了几个手写体,也不是我们教材上的样子。我怀疑这是不是编教材的“专家”自创的,字还糊的很,应该是手绘印刷的,不是一款可以机打出来的字体。
看得强迫症都出来了,所以自己造了一个字体,分享给有需要的人。
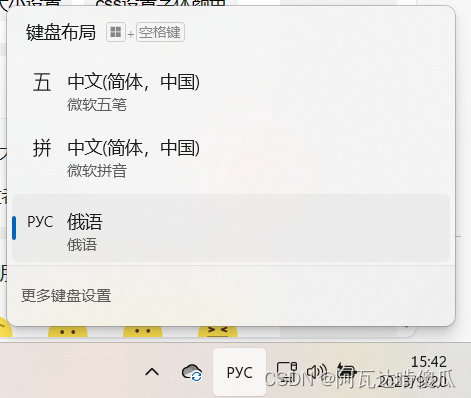
首先,在系统键盘布局里面添加俄语,用Shift+Alt可以切换俄文和中文键盘。
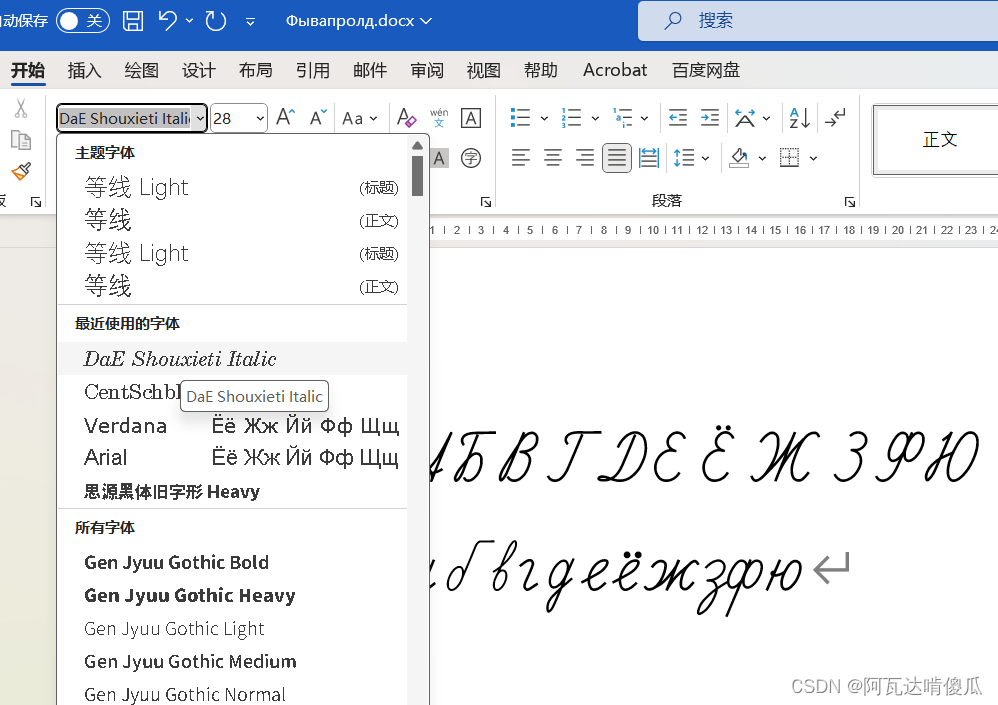
然后,安装我造的字体。字体是从另一个字体改过来的,只改了俄文大小写字母,其他没有更改。安装后在文档里面找“DaE Shouxieti Italic”字体就可以用了:
字体请到下面的链接提取,随便分发使用,发现有错误的话告诉我。
压缩包中附送PDF版的俄语字母表和俄语键盘布局图。


https://www.aliyundrive.com/s/svi1NnrHoeD
提取码: 32do
这篇关于俄文手写字体-初中教材版的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









