本文主要是介绍Spark框架深度理解一:开发缘由及优缺点,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
由于Spark框架大多都搭建在Hadoop系统之上,要明白Spark核心运行原理还是得对Hadoop体系有个熟悉的认知。从Hadoop1.0到Hadoop2.0架构的优化和发展探索详解这篇博客大家可以先去温习一下Hadoop整个体系,然后再来了解Spark框架会更有效率。
本来想直接写一篇缘由优缺点以及生态圈和运行架构与原理的,发现篇幅实在是太长了,索性分两篇
一、开发Spark目的
如果要用到Spark那基本上离不开Hadoop,我们了解到为了弥补Hadoop体系的许多不便之处,软件工程师们开发了很多便利工具去弥补Hadoop的不足或者去利用这种分布式处理的体系。例如:Hbase,Hive,等工具。
而开发Spark的主要目的,是其MapReduce计算模型延迟过高,无法胜任实时,快速计算的需求,也太过单调无法在以上做更多的开发。Spark的诞生弥补了MapReduce的缺陷。Spark继承了MapReduce分布式计算的优点并改进了MapReduce明显的缺陷。
Spark的发展历史:

2009年,Spark诞生于伯克利大学的AMPLab实验室。最出Spark只是一个实验性的项目,代码量非常少,属于轻量级的框架。
2010年,伯克利大学正式开源了Spark项目。
2013年,Spark成为了Apache基金会下的项目,进入高速发展期。第三方开发者贡献了大量的代码,活跃度非常高。
2014年,Spark以飞快的速度称为了Apache的顶级项目。
2015年~,Spark在国内IT行业变得愈发火爆,大量的公司开始重点部署或者使用Spark来替代MapReduce、Hive、Storm等传统的大数据计算框架。
二、Spark的优缺点
1.优点
1.快速
Spark基于内存进行计算。
Spark基于内存进行计算。
Spark基于内存进行计算。
内存计算和磁盘运算的差距就不用我多说了吧,学过操作系统的懂得都懂。但是我还是讲一下这两者的区别:
我们知道计算机是利用CPU进行数据的运算的,但CPU只能对内存中的数据进行运算,而对于磁盘中的数据是不能运算的。如果要运算磁盘中的数据,必须先把磁盘中的数据读入内存,CPU才能进行运算。

我们可以用logistic算法Logistic模型原理详解分别用Hadoop MapReduce和Spark跑一边,logistic需要不停的迭代梯度算出最优参数,因此迭代了相当多次。对比:
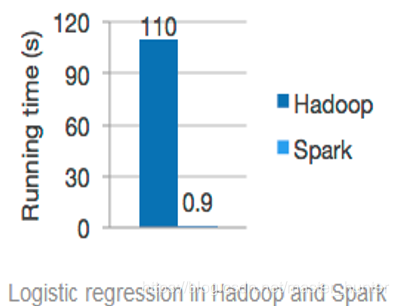
一般情况下,对于迭代次数较多的应用程序,Spark程序在内存中的运行速度是Hadoop MapReduce运行速度的100多倍,在磁盘上的运行速度是Hadoop MapReduce运行速度的10多倍。

Spark的中间数据存放于内存中,有更高的迭代运算效率,而Hadoop每次迭代的中间数据存放HDFS中,设计硬盘的读写,明显降低了运算效率。
2.易用
Spark支持多语言。Spark允许Java、Scala、Python及R(Spark 1.4版最新支持),这允许更多的开发者在自己熟悉的语言环境下进行工作,普及了Spark的应用范围,它自带80多个高等级操作符,允许在shell中进行交互式查询,它多种使用模式的特点让应用更灵活。
3.通用
Spark提供了Spark RDD、Spark SQL、Spark Streaming、Spark MLlib、Spark GraphX等技术组件,可以一站式地完成大数据领域的离线批处理、交互式查询、流式计算、机器学习、图计算等常见的任务。

3.随处运行
用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive、Tachyon和任何分布式文件系统读取数据。
4.支持复杂查询
除了简单的map及reduce操作之外,Spark还支持filter、foreach、reduceByKey、aggregate以及SQL查询、流式查询等复杂查询。Spark更为强大之处是用户可以在同一个工作流中无缝的搭配这些功能,例如Spark可以通过Spark Streaming获取流数据,然后对数据进行实时SQL查询或使用MLlib库进行系统推荐,而且这些复杂业务的集成并不复杂,因为它们都基于RDD这一抽象数据集在不同业务过程中进行转换,转换代价小,体现了统一引擎解决不同类型工作场景的特点。
5.随处运行
Spark不仅可以独立的运行(使用standalone模式),还可以运行在当下的YARN管理集群中。它还可以读取已有的任何Hadoop数据,这是个非常大的优势,它可以运行在任何Hadoop数据源上,比如HBase、HDFS、Hive等。如果合适的话,这个特性让用户可以轻易迁移已有Hadoop应用。
6.代码简洁
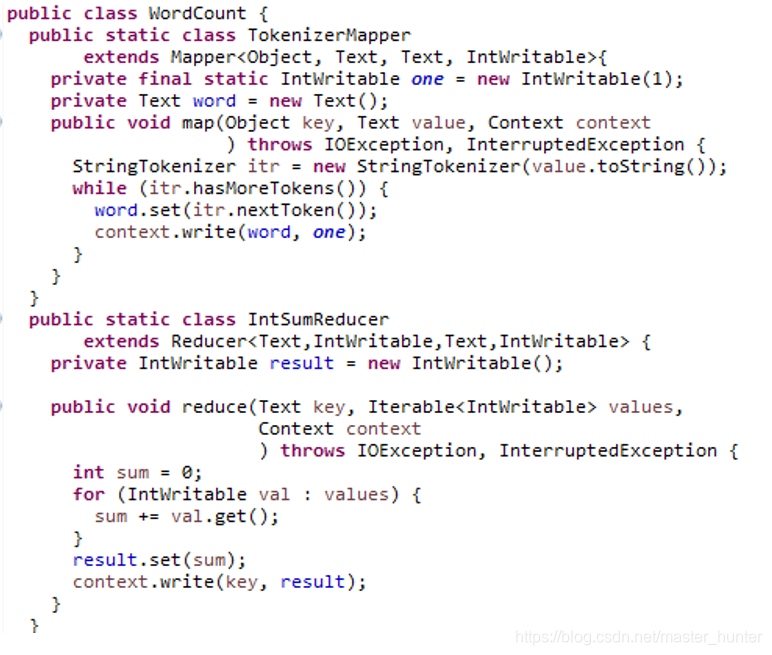
MapReduce十几行的代码用Scala写的程序在Spark上仅需要一行就能解决。
MapReduce:
Scala:
sc.textFile("/user/root/a.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/user/root/output")
二、缺点
1.内存问题
JVM的内存overhead太大,1G的数据通常需要消耗5G的内存。
2.性能问题
由于大量数据抄被缓存在RAM中,Java回收垃圾缓慢的情况严重,导致Spark性能不稳定。
参阅:
计算机内存和磁盘的关系
spark的前世今生
Spark及其生态圈简介
这篇关于Spark框架深度理解一:开发缘由及优缺点的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





