本文主要是介绍羊城杯2023misc方向完整wp,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

misc孤狼~
附件链接:https://pan.baidu.com/s/15vAxjMulb39hXfsomMH-pg?pwd=d00b
文章目录
- ai和nia的交响曲
- EZ_misc
- Matryoshka
- 程序猿Quby
- 两只老虎
- Easy_VMDK
- GIFuck
ai和nia的交响曲
flag2.zip
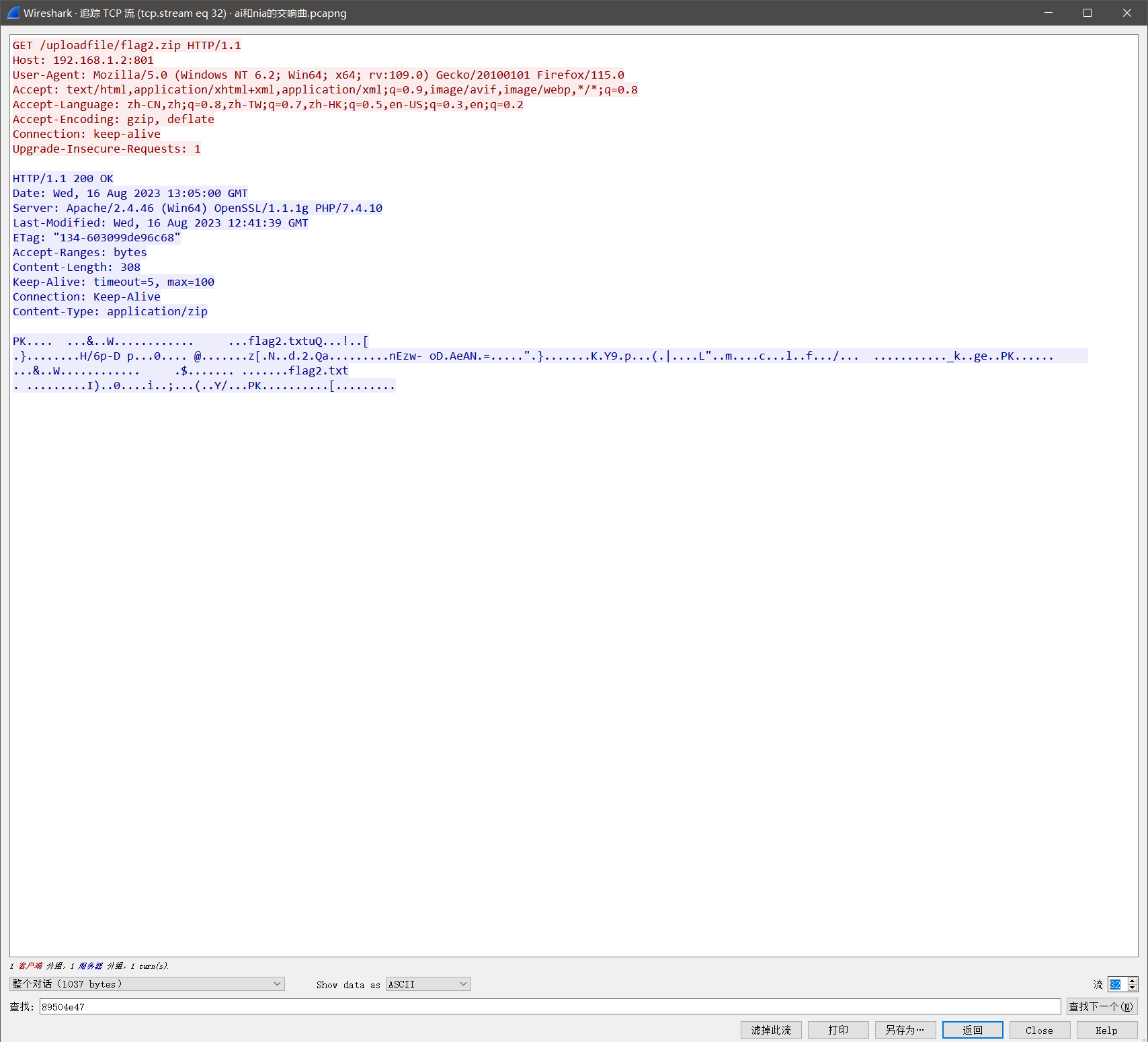
伪加密
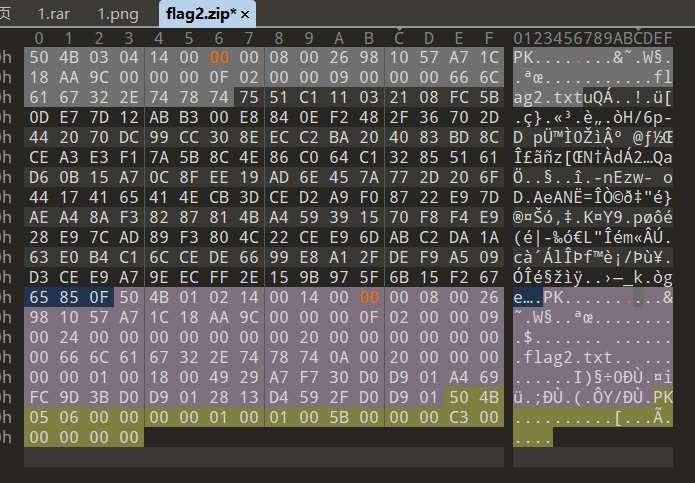
一堆时间不知道干嘛,0宽提示先去看flag1拿到hint

flag1.png

一副鬼样,读一下像素
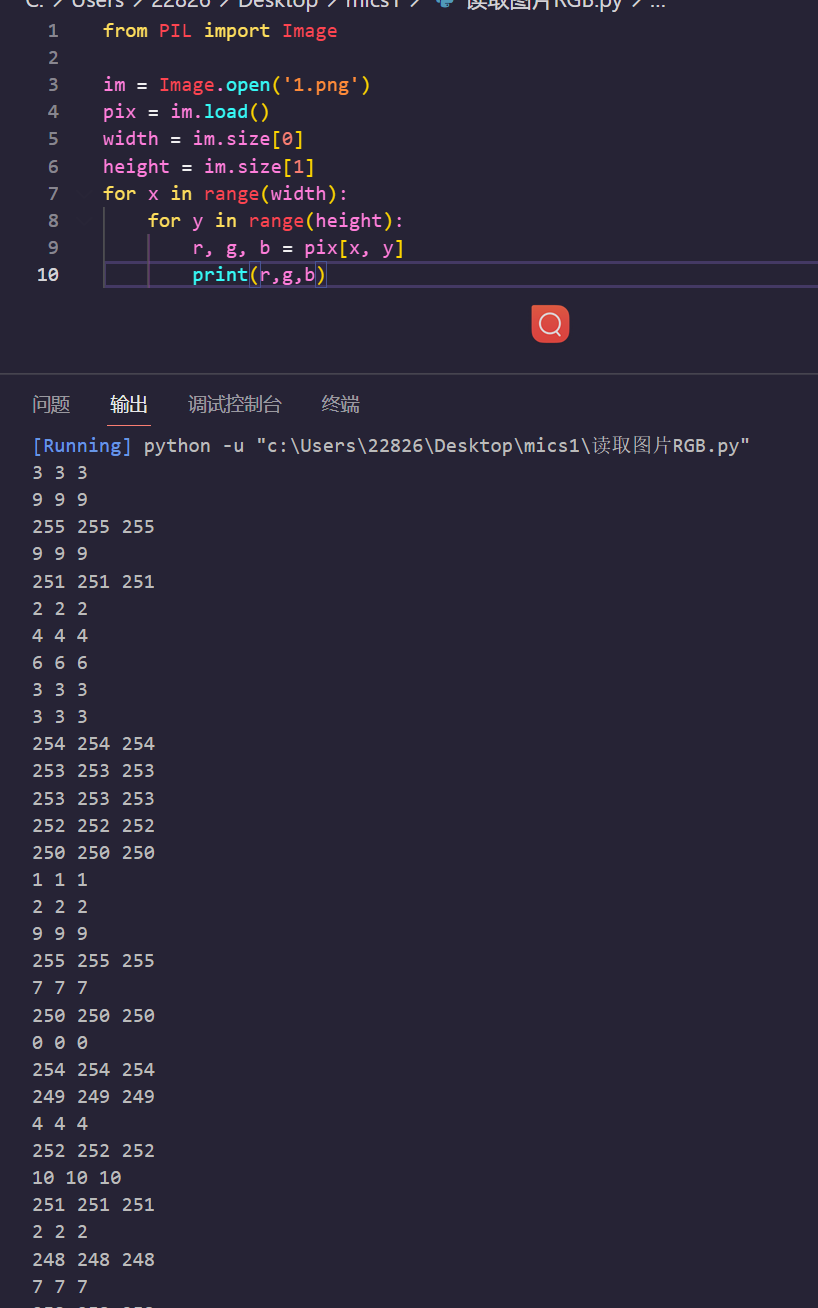
转二进制
from PIL import Imageim = Image.open('1.png')
pix = im.load()
width = im.size[0]
height = im.size[1]
for x in range(width):for y in range(height):r, g, b = pix[x, y]if r>200:print(1,end='')else:print(0,end='')
HINT:BV1wW4y1R7Jv&&FLAG1:@i_n1a_l0v3S_
拿到flag1,hint一眼bv号,https://www.bilibili.com/video/BV1wW4y1R7Jv
结合之前flag2的时间应该对应帧,但是解出来BANBANFAHFAM不对
脑洞一下,往后晚一秒钟解出个CAOCAOGAIFAN比较有含义,曹操盖饭
拼一下flag:
@i_n1a_l0v3S_CAOCAOGAIFAN
好好好做完半天了放个hint出来,差评

EZ_misc
文件尾一个zip,提示5位数字密码
zip文件头0403要改回成0304
根据txt文件名和key是数字猜到是Gronsfeld加密 Gronsfeld Cipher (online tool) | Boxentriq
提示截图工具
结合两文件尾明显特征
考过好几次了,CVE-2023-28303 frankthetank-music/Acropalypse-Multi-Tool: Easily detect and restore Acropalypse vulnerable PNG and GIF files with simple Python GUI. (github.com)
Matryoshka
套娃
一张jpg
一个rar
一个encrypt,长度20.0mb一眼vc
rar文件尾还一个jpg
提取出来一样的小猫图,一眼盲水印,py2版本的

这里有点抽象,读出来是Watermark_is_fun,密码是小写的W,watermark_is_fun
挂载拿到
0宽
base32后维吉尼亚
程序猿Quby
图片尾一个rar
图片是夏多密码,参考犯罪大师本周解密 夏多密码解析_游戏攻略 (bilibili.com)
解得HAVEANICEDAY

cloacked-pixel拿到rar密码
python2 lsb.py extract QUBY.png flag.txt HAVEANICEDAY
excel有隐藏行

透明文字全加上颜色
6.66全部改为1,3.33都改为0

另一张表也同样处理,4.66改为0,5.53改为1
拼一起之后加个突出显示
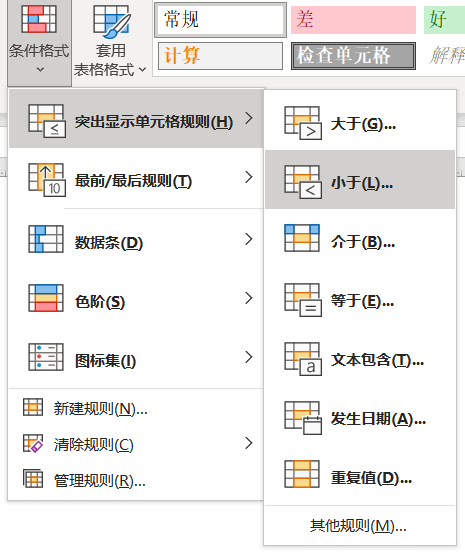
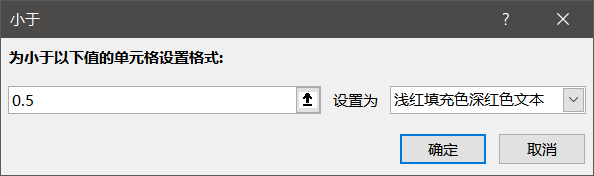
缩放一下,翻转即可

得到w0wyoudo4goodj0b
deepsound
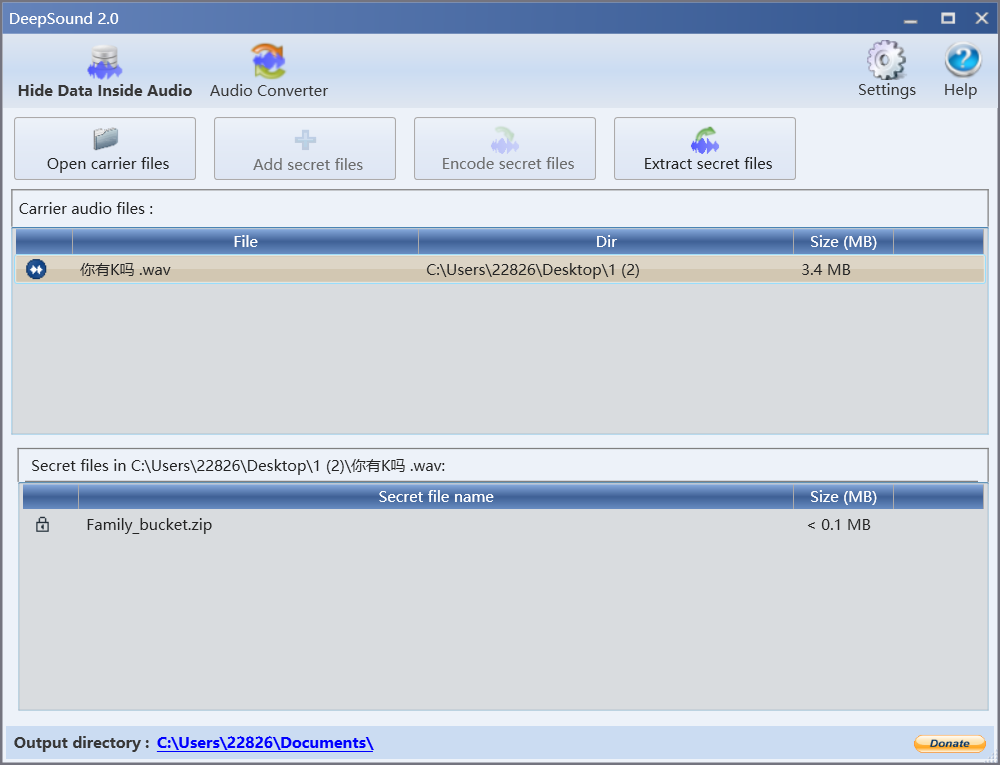
得到
fl4g.txt
:JOJ[=%tJD9gr2Q79*;T:-qZD=]S0c:0'nT7orYd9L_TD=Ys#Z9iY:q;-$Xo:dQs>9ia&M9i3]K5r2G>8Oc'9=%u:f8QIW;;bp(\8Ms%=10QJ$:KBnd<AmK;7p.T97oN8Jflag.txt
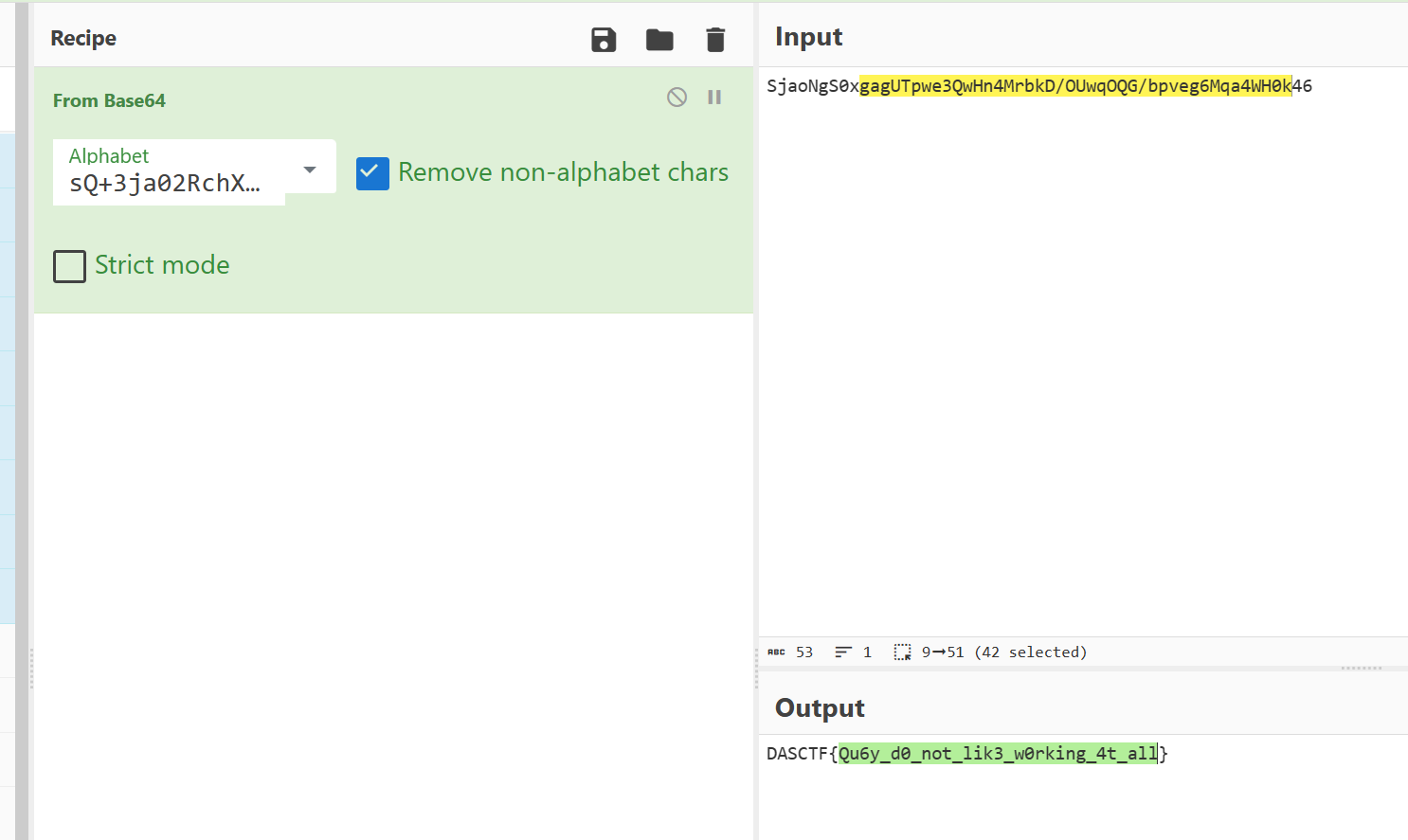
SjaoNgS0xgagUTpwe3QwHn4MrbkD/OUwqOQG/bpveg6Mqa4WH0k46
fl4g.txt解base85(a),base32得到
sQ+3ja02RchXLUFmNSZoYPlr8e/HVqxwfWtd7pnTADK15Evi9kGOMgbuIzyB64CJ
长度64,一眼base64表
两只老虎
肝到凌晨两点的二血)
后面显然有一大堆不合常理的idat块,正常每个idat块应该保持0x10000,即65536不变
后面数据块都提取出来并且在原图里删掉没有对原图产生任何影响,但是要留第一个0x84E2块,是这张图的原来的正常的IDAT结尾块,这个删了发现原图底部会缺一块

得到的第一张png的结构:
前面提取出来的IDAT数据加上个原图的png头和png尾,第二张图的结构:

打开可以发现一个整个像素乱掉的图,有过经验就很明显知道是png的宽被篡改了导致整个像素偏移了

爆破一下第二张图的宽,小溜一下chatgpt
import struct# 输入和输出文件名
input_file = 'laohu.png'def change(new_width,new_height):# 打开输入文件并读取二进制数据with open(input_file, 'rb') as file:png_data = file.read()output_file = f"output/{new_width}_{new_height}.png"# 找到宽度和高度所在的位置(通常在第16到20字节和20到24字节)width_start = 16 height_start = 20# 使用struct模块将新的宽度和高度转换为4字节的大端整数new_width_bytes = struct.pack('>I', new_width)new_height_bytes = struct.pack('>I', new_height)# 替换PNG文件中的宽度和高度数据png_data = png_data[:width_start] + new_width_bytes + png_data[width_start+4:height_start] + new_height_bytes + png_data[height_start+4:]# 将修改后的数据写入新文件with open(output_file, 'wb') as file:file.write(png_data)print(f'已保存为{output_file}')new_height = 720
for new_width in range(0,2000):change(new_width,new_height)
同理也要爆破一下高,这里不再演示,其实就是原图的高
最后爆破出来宽是1144,高是720的时候得到第二张图


很明显宽1144比原图1134多了10像素,就是右边红色部分,直接裁剪掉
这里如果怕工具会压缩图片可以python读像素舍弃掉后10列,但是由于文件头的IHDR的CRC是原来1134*720的,img库读会报错,需要先手动重算一次CRC并覆盖
import binascii
with open('1144_720.png','rb')as f:crc = binascii.crc32(f.read()[12:29])print(hex(crc))
#0x640f50ad
from PIL import Imageoriginal_image = Image.open('1144_720.png')width, height = original_image.size
new_image = Image.new('RGB', (width-10, height))for y in range(height):original_row = original_image.crop((0, y, width - 10, y + 1))new_image.paste(original_row, (0, y))
new_image.save('new_image.png')
两张图对比像素有差异,很明显的水印特征
但是盲水印、像素异或等等都试过了都没出
对比了一下像素差异点
from PIL import Image, ImageChopsdef count_difference_types(image1_path, image2_path):# 打开两张图片img1 = Image.open(image1_path)img2 = Image.open(image2_path)# 确保两张图像具有相同的尺寸if img1.size != img2.size:img1 = img1.resize(img2.size)# 比较图片diff = ImageChops.difference(img1, img2)# 获取不同像素的坐标和像素值diff_data = list(diff.getdata())diff_types = set(pixel_diff for pixel_diff in diff_data if pixel_diff != (0, 0, 0))# 统计每种差异类型的出现次数difference_count = {}for pixel_diff in diff_types:count = diff_data.count(pixel_diff)difference_count[pixel_diff] = count# 打印每种差异类型和其出现次数for pixel_diff, count in difference_count.items():print(f"Difference Type: {pixel_diff}, Count: {count}")if __name__ == "__main__":image1_path = "1.png" # 替换为您的第一个图片路径image2_path = "new_image.png" # 替换为您的第二个图片路径count_difference_types(image1_path, image2_path)# Difference Type: (1, 1, 0), Count: 54
# Difference Type: (1, 1, 1), Count: 2534
总共就只有两种像素差,还都是三通道各差1或者前两个通道差1,明显不是什么水印之类的了,这里卡了很久
各种fuzz后读取每行的不同像素点数量是flag
from PIL import Image
image1_path = "1.png"
image2_path = "new_image.png" img1 = Image.open(image1_path)
img2 = Image.open(image2_path)
width, height = img1.sizefor y in range(height):row1_pixels = list(img1.crop((0, y, width, y + 1)).getdata())row2_pixels = list(img2.crop((0, y, width, y + 1)).getdata())if row1_pixels != row2_pixels:count = 0for p1, p2 in zip(row1_pixels, row2_pixels):if p1 != p2:count += 1print(chr(count),end='')#DASCTF{tWo_t1gers_rUn_f@st}
一些个骚且帅的姿势
from PIL import Image
import numpy as npimg1 = np.array(Image.open('1.png'))
img2 = np.array(Image.open('new_image.png').crop((0, 0, 1134, 720)))
print(bytes([sum(i) for i in img1[:, :, 0] != img2[:, :, 0] if sum(i) != 0]).decode())
Easy_VMDK
[“小明这次使用了32Bytes的随机密码,这次总不会被爆破出来了吧!!。小明压缩了好了题目后,他发现压缩后大小比压缩前还大啊,这不就没有压缩啊,这是为什么啊!”,“小明这次使用了32Bytes的随机密码,这次总不会被爆破出来了吧!!”]
压缩后更大,在提示store
电脑里随便翻几个vmdk的文件头,直接明文打
flag.zip
key.txt
flag.zip后面还有个zip
里面是key.txt的加密脚本,读像素,uu编码再base64
import cv2
import base64
import binasciiimg = cv2.imread("key.png")
r, c = img.shape[:2]
print(r, c)
# 137 2494with open("key.txt", "w") as f:for y in range(r):for x in range(c):uu_byte = binascii.a2b_uu(', '.join(map(lambda x: str(x), img[y, x])) + "\n")f.write(base64.b64encode(uu_byte).decode() + "\n")
逆一下
import base64
import binascii
from PIL import Imageheight = 137
width = 2494
im = Image.new("RGB", (width, height), 'white')
imglists=[]
with open("key.txt", "r") as f:lists=f.readlines()for i in lists:data = (binascii.b2a_uu(base64.b64decode(i))).decode().strip()imglists.append(data)for y in range(height):for x in range(width):pixel = tuple(map(int, imglists[y * width + x].split(', ')))im.putpixel((x, y), pixel)im.show()

HELLO_DASCTF2023_WORLD 解开拿到flag
GIFuck
拆帧
from PIL import Image
import osgif_path = "flag.gif"
gif_image = Image.open(gif_path)# 获取GIF中的帧数
num_frames = gif_image.n_framesoutput_directory = "output_png_frames/"
os.makedirs(output_directory, exist_ok=True)for frame_number in range(num_frames):gif_image.seek(frame_number)frame_image = gif_image.copy()frame_image.save(f"{output_directory}{frame_number}.png")

类型不多,不ocr了,直接根据哈希打印一下字符
import os
import hashlibcurrent_directory = os.getcwd()for root, dirs, files in os.walk(current_directory):for i in range(1,1100):file_name = str(i)+".png"file_path = os.path.join(root, file_name)if os.path.isfile(file_path):with open(file_path, 'rb') as file:md5_hash = hashlib.md5()while True:data = file.read(4096) # 每次读取4KBif not data:breakmd5_hash.update(data)if md5_hash.hexdigest() == "73b98b0ce63e17f9686d8f1c7c2c1ea4":print("+",end='')elif md5_hash.hexdigest() == "0603d47d8bbd5824d76d487a3f313b11":print("[",end='')elif md5_hash.hexdigest() == "abd01d8e57bd41d62a7444aadbb932a5":print("-",end='')elif md5_hash.hexdigest() == "59fe976c8572cdd59996b4e3c088809e":print(">",end='')elif md5_hash.hexdigest() == "af08104d55fae5787b073e974aa8f303":print("<",end='')elif md5_hash.hexdigest() == "e20180170280aeb074384bcbae840cf0":print("]",end='')elif md5_hash.hexdigest() == "fd439e1a7e9058ae4d635755dedf4191":print(".",end='')else:print(f"File: {file_path} MD5: {md5_hash.hexdigest()}")+[->+<]>[->+<]>-[->+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+<]+<+<+[->+<]>[->+<]>[->-<]>[-<+>]+<+<+[->+<]>[->+<]>[->-<]>[-<+>]<+[->+<]>[->-<]>[-<+>]<+<+[->+<]>[->+<]>[->-<]>[-<+>]+<+[->+<]>[->-<]>[-<+>]+<+<+[->+<]>[->+<]>[->-<]>[-<+>]<+<+[->+<]>[->+<]>[->+<]>[-<+>]+<+[->+<]>[->-<]>[-<+>]+<+[->+<]>[->+<]>[-<+>]+<+[->+<]>[->+<]>[-<+>][->+<]>[-<+>]+<+[->+<]>[->-<]>[-<+>]+<+[->+<]>[->+<]>[-<+>]+<+[->+<]>[->+<]>[-<+>]+<+[->+<]>[->+<]>[-<+>]+[->+<]>[-<+>]+<+[->+<]>[->+<]>[->+<]>[-<+>]+<+[->+<]>[->+<]>[->+<]>[-<+>]+<+[->+<]>[->+<]>[-<+>]+<+[->+<]>[->+<]>[-<+>][->+<]>[-<+>]+<+<+[->+<]>[->+<]>[->-<]>[-<+>]+<+[->+<]>[->+<]>[->+<]>[-<+>]+<+[->+<]>[->+<]>[->+<]>[-<+>]+<+[->+<]>[->+<]>[-<+>]+<+[->+<]>[->+<]>[-<+>][->+<]>[-<+>]+<+[->+<]>[->-<]>[-<+>]+<+[->+<]>[->+<]>[-<+>]+<+[->+<]>[->+<]>[-<+>]+<+<+[->+<]>[->+<]>[->+<]>[-<+>]<+[->+<]>+.<+[->+<]>+.+.+.<+[->-<]>-.<+[->+<]>+.<+[->+<]>+.-.<+[->-<]>-.<+[->+<]>+.<+[->-<]>-.+.-.<+[->-<]>-.<+[->+<]>+.+.<+[->-<]>-.+.<+[->-<]>-.<+[->+<]>+.<+[->+<]>+.<+[->-<]>-.<+[->+<]>+.+.+.<+[->-<]>-.<+[->+<]>+.-.<+[->+<]>+.<+[->-<]>-.<+[->-<]>-.[-]<
很明显brainfuck,但解出来不对
脑洞一下,读一下帧长度,小溜一下chatgpt
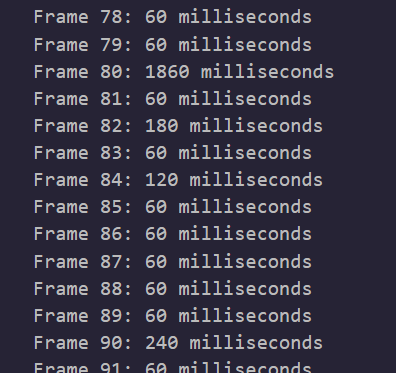
很明显全60的倍数,按倍数次去导,稍微改改文件名格式方便后面按顺序读
from PIL import Image
import os
# 打开GIF文件
gif_path = "flag.gif"
gif_image = Image.open(gif_path)# 获取GIF中的帧数
num_frames = gif_image.n_frames# 创建一个目录来保存PNG图像
output_directory = "output_png_frames_repeat/"
os.makedirs(output_directory, exist_ok=True)# 读取并根据时间帧长度导出帧
for frame_number in range(num_frames):gif_image.seek(frame_number)frame_image = gif_image.copy()duration = gif_image.info['duration'] # 获取当前帧的时间帧长度(以毫秒为单位)export_count = duration // 60for i in range(export_count):frame_image.save(f"{output_directory}{frame_number:d}{(i+1):02d}.png")
再打印一波字符 这次形式就很对
++++[->++++<]>[->++++++<]>-[->+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+>+<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<]+++<++<+[->++++<]>[->++++<]>[->-<]>[-<<<+>>>]++<+++<+[->++++<]>[->++++<]>[->-<]>[-<<<+>>>]<+++[->++++<]>[->-<]>[-<<<+>>>]<+++<+[->++++<]>[->++++<]>[->-<]>[-<<<+>>>]+++<++[->++++<]>[->-<]>[-<<<+>>>]+<++<+[->++++<]>[->++++<]>[->-<]>[-<<<+>>>]<+++<+[->++++<]>[->++++<]>[->+<]>[-<<<+>>>]+++<+++[->++++<]>[->-<]>[-<<<+>>>]++<+[->++++<]>[->+<]>[-<<<+>>>]+++<+++[->++++<]>[->+<]>[-<<<+>>>][->+<]>[-<<<+>>>]+++<+++[->++++<]>[->-<]>[-<<<+>>>]++<++[->++++<]>[->+<]>[-<<<+>>>]+++<+++[->++++<]>[->+<]>[-<<<+>>>]++<+[->++++<]>[->+<]>[-<<<+>>>]++[->+<]>[-<<<+>>>]+<<+[->++++<]>[->++++<]>[->+<]>[-<<<+>>>]+<<+[->++++<]>[->++++<]>[->+<]>[-<<<+>>>]+<+++[->++++<]>[->+<]>[-<<<+>>>]++<+[->++++<]>[->+<]>[-<<<+>>>][->+<]>[-<<<+>>>]++<+++<+[->++++<]>[->++++<]>[->-<]>[-<<<+>>>]+<<+[->++++<]>[->++++<]>[->+<]>[-<<<+>>>]+<<+[->++++<]>[->++++<]>[->+<]>[-<<<+>>>]+<+++[->++++<]>[->+<]>[-<<<+>>>]++<+[->++++<]>[->+<]>[-<<<+>>>][->+<]>[-<<<+>>>]+++<+++[->++++<]>[->-<]>[-<<<+>>>]++<+[->++++<]>[->+<]>[-<<<+>>>]+++<+++[->++++<]>[->+<]>[-<<<+>>>]++<+++<+[->++++<]>[->++++<]>[->+<]>[-<<<+>>>]<<+++++++++[->+++++++++<]>++.<+++++[->+++++<]>+++.+++..+++++++.<+++++++++[->---------<]>--------.<++++++++[->++++++++<]>++.<++++[->++++<]>+++.-.<+++++++++[->---------<]>---.<+++++++++[->+++++++++<]>++++++++.<+++[->---<]>-.++++++.---.<+++++++++[->---------<]>-.<++++++++[->++++++++<]>++++++.++++++.<+++[->---<]>--.++++++.<++++++++[->--------<]>-------.<++++++++[->++++++++<]>+++++++++.<+++[->+++<]>+.<+++++++++[->---------<]>--.<++++++++[->++++++++<]>++++++++++++++.+.+++++.<+++++++++[->---------<]>---.<++++++++[->++++++++<]>++++++++.---.<+++[->+++<]>++++.<+++[->---<]>----.<+++++++[->-------<]>------.[-]
flag在memory
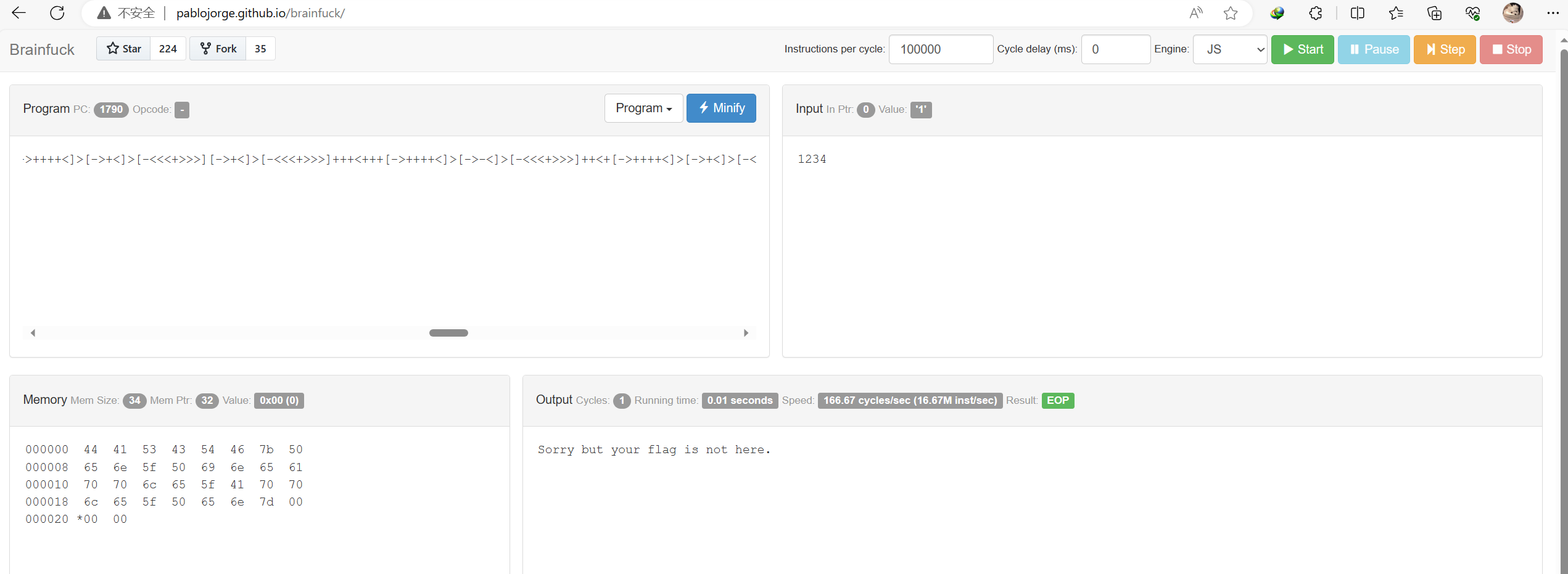
这篇关于羊城杯2023misc方向完整wp的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





