本文主要是介绍【腾讯云 Finops Crane 开发者集训营】浅谈Crane的核心概念和原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、Crane是什么?
FinOps(Financial Operations)是一种管理云计算成本的方法,它强调将云计算资源的成本与使用情况及业务需求相匹配,从而提高企业的效率和效益。在当前云计算环境下,FinOps已经成为了越来越多企业的管理方法。
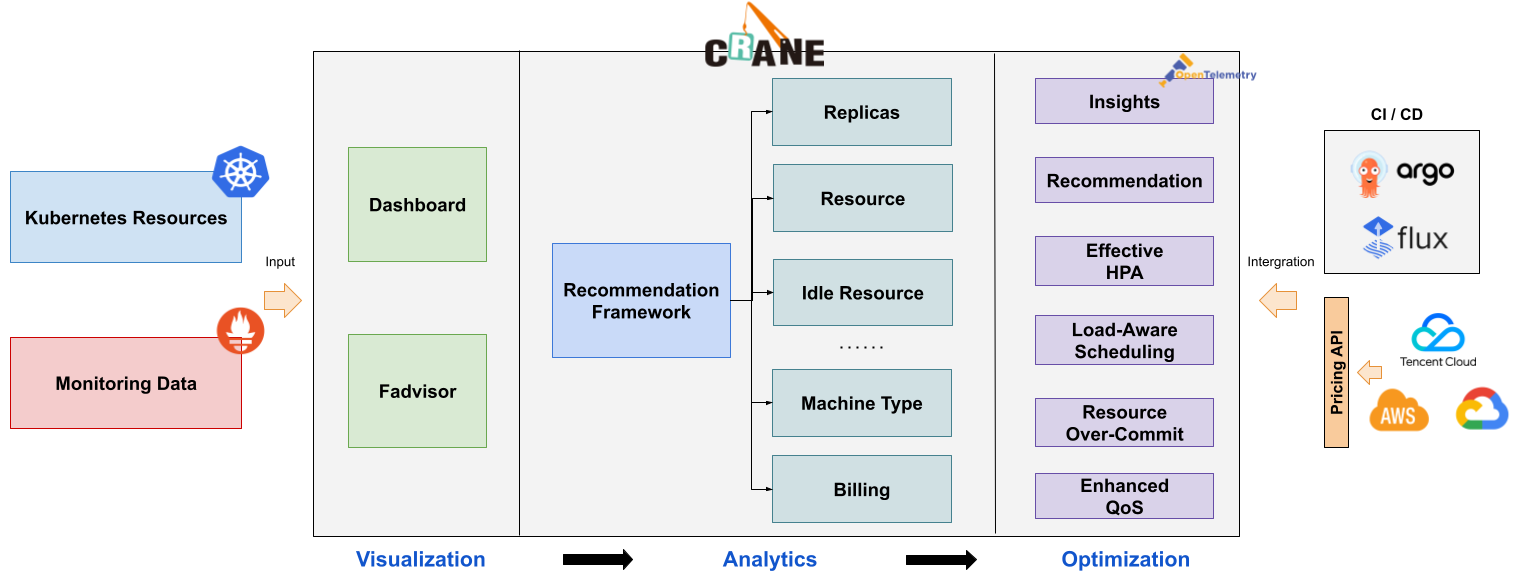
Crane 是一个基于 FinOps 的云资源分析与成本优化平台。它的愿景是在保证客户应用运行质量的前提下实现极致的降本。它可以为用户提供:
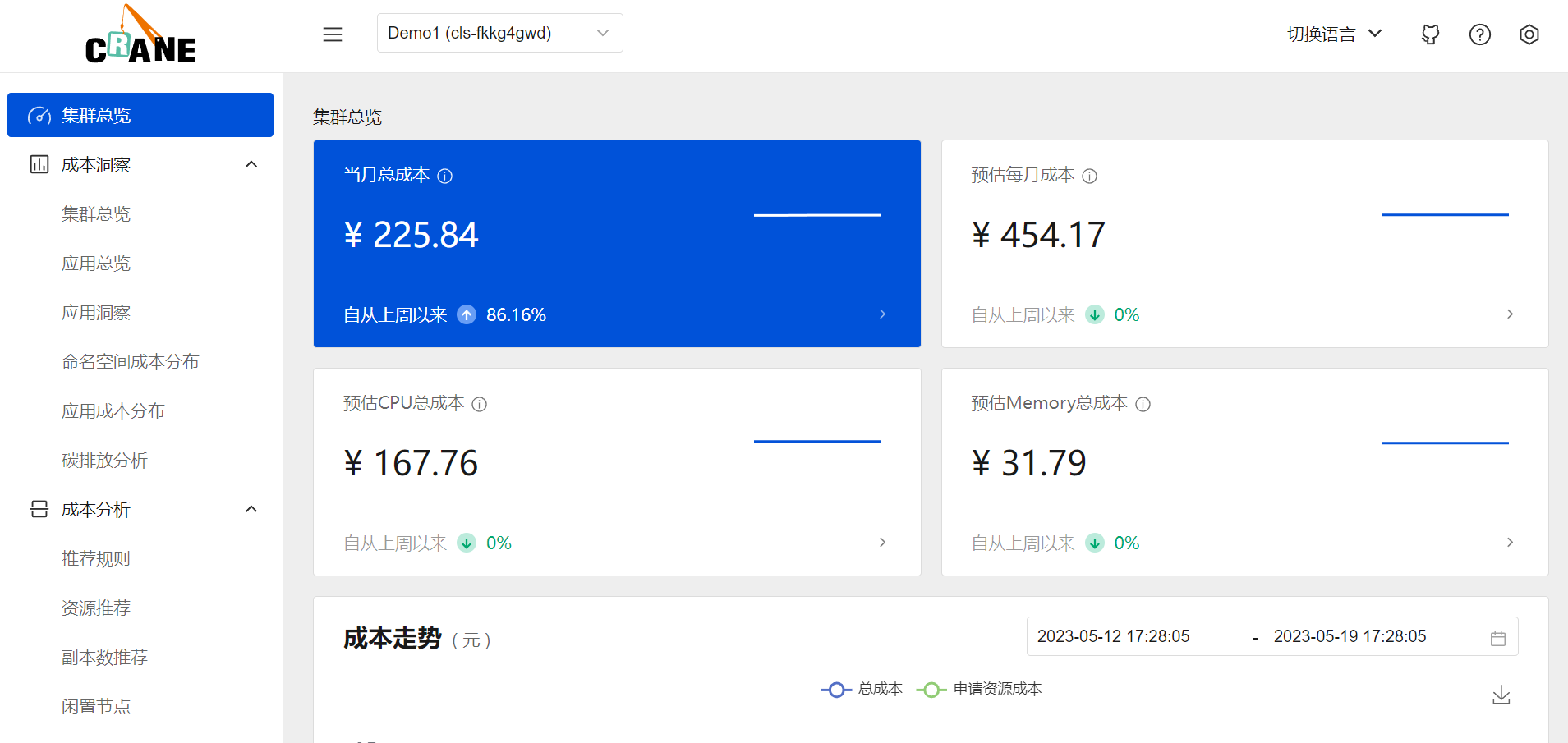
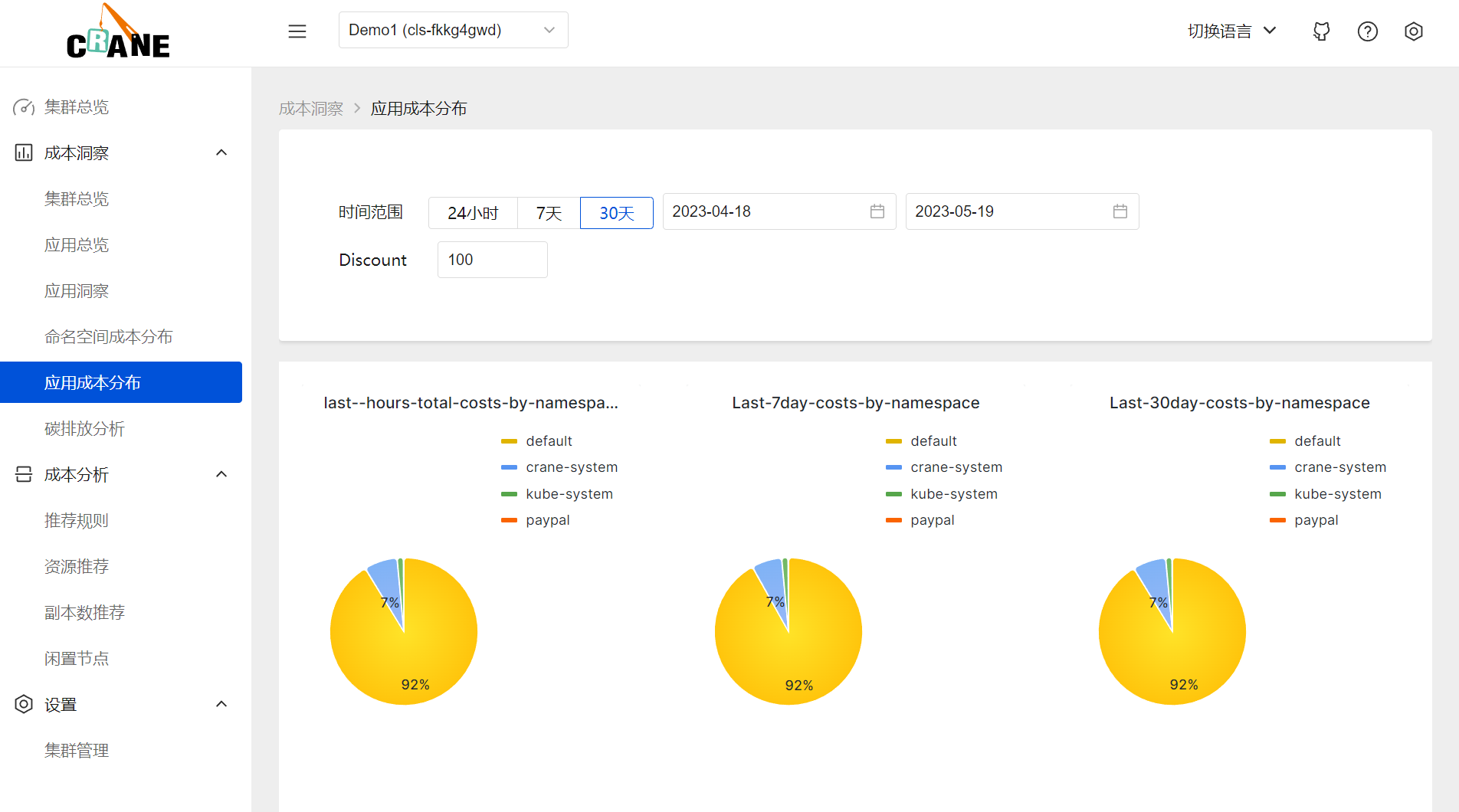
- 成本展示:
Kubernetes资源(Deployments,StatefulSets)的多维度聚合与展示。 - 成本分析: 周期性的分析集群资源的状态并提供优化建议。
- 成本优化: 通过丰富的优化工具更新配置达成降本的目标。
官方地址:https://github.com/gocrane/crane
官方文档:https://github.com/gocrane/crane/blob/main/README_zh.md
本篇博文旨在从核心概念和原理方面解读Crane的系统架构、模型方案和底层算法。
二、系统架构
Crane 的整体架构如下:
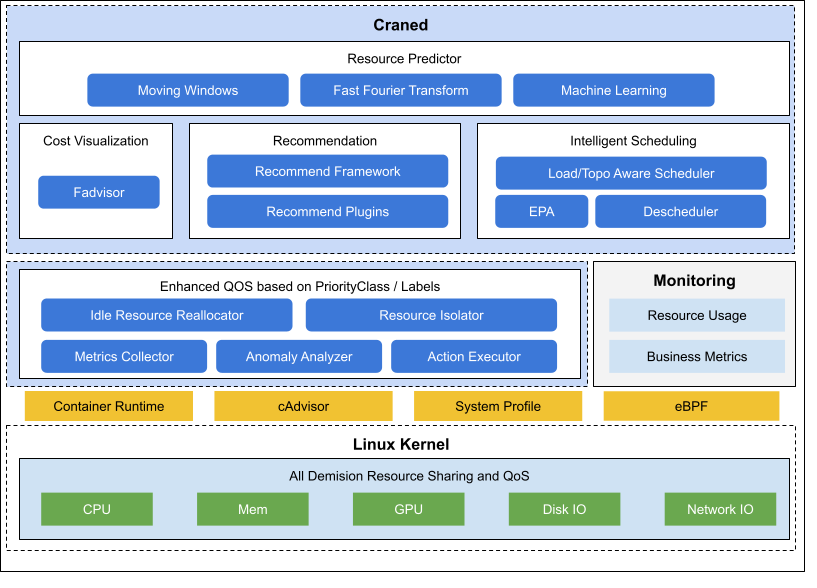
2.1、Craned
Craned是Crane的核心组件之一,主要负责管理CRD(Custom Resource Definition)的生命周期和API,是Kubernetes中的一种自定义资源类型。CRD允许用户定义自己的API对象,这些对象可以像Kubernetes原生对象一样进行管理和操作。通过CRD,用户可以通过kubectl apply命令将自己的应用程序或服务与Kubernetes集成,从而更好地利用Kubernetes的强大功能。Craned 通过 Deployment 方式部署且由Craned、Dashboard两个容器组成:
Craned容器运行了Operators用于管理CRD。Operators是一种Kubernetes控制器,可以自动化管理CRD的生命周期,包括创建、更新和删除CRD对象。通过Operators,用户可以定义自己的业务逻辑,实现自动化的资源管理和操作。Dashboard提供了WebApi和Predictors提供的TimeSeries API。Dashboard是基于TDesign’s Starter脚手架开发的前端项目,提供了易于上手的产品功能,可以通过Web界面对CRD进行管理和操作。WebApi是Craned提供的Web接口,可以通过HTTP请求访问,实现对CRD的管理和操作。Predictors提供了TimeSeries API,可以用于对时间序列数据进行预测和分析,为用户提供更加智能化的资源管理和操作。
2.2、Fadvisor
- Fadvisor是一种开源的容器资源监控工具,可以用于监控和收集容器的资源使用情况,并将数据导出到监控系统中,如Prometheus。Fadvisor提供了一组Exporter,用于计算集群云资源的计费和账单数据,并将其存储到监控系统中。通过Fadvisor,用户可以更好地了解容器的资源使用情况,从而更好地进行容器资源管理和优化。
- Fadvisor还通过Cloud Provider支持了多云计费的API,可以根据不同的云服务提供商的计费规则,计算出相应的费用,并将其导出到监控系统中。这使得用户可以更加方便地进行多云资源管理和计费,帮助更好地管理和优化容器资源。
2.3、Metric Adapter
- Metric Adapter**是Kubernetes中的一个组件,它实现了一个Custom Metric Apiserver,用于提供基于
Custom/External Metric API的HPA Metric数据。Metric Adapter通过读取CRDs(Custom Resource Definitions)信息,将其转换为Custom Metrics API的格式,并将其提供给HPA(Horizontal Pod Autoscaler)进行使用。 - 具体来说,Metric Adapter可以读取CRDs中定义的自定义指标数据,并将其转换为
Custom Metrics API的格式,然后将其提供给HPA进行使用。这样,用户就可以使用自定义指标来进行水平自动扩展,从而更好地满足应用程序的需求。
2.4、Crane Agent
- Crane Agent是一个部署在Kubernetes集群节点上的代理程序,它通过DaemonSet方式进行部署。Crane Agent的主要作用是收集节点的资源使用情况和性能指标,并将这些数据发送到Crane Server进行分析和处理。核心代码如下:
func Run(ctx context.Context, opts *options.Options) error {hostname := getHostName(opts.HostnameOverride)healthCheck := metrics.NewHealthCheck(opts.MaxInactivity)metrics.RegisterCraneAgent()kubeClient, craneClient, err := buildClient()if err != nil {return err}podInformerFactory := informers.NewSharedInformerFactoryWithOptions(kubeClient, informerSyncPeriod,informers.WithTweakListOptions(func(options *metav1.ListOptions) {options.FieldSelector = fields.OneTermEqualSelector(specNodeNameField, hostname).String()}),)nodeInformerFactory := informers.NewSharedInformerFactoryWithOptions(kubeClient, informerSyncPeriod,informers.WithTweakListOptions(func(options *metav1.ListOptions) {options.FieldSelector = fields.OneTermEqualSelector(metav1.ObjectNameField, hostname).String()}),)podInformer := podInformerFactory.Core().V1().Pods()nodeInformer := nodeInformerFactory.Core().V1().Nodes()craneInformerFactory := craneinformers.NewSharedInformerFactory(craneClient, informerSyncPeriod)nodeQOSInformer := craneInformerFactory.Ensurance().V1alpha1().NodeQOSs()podQOSInformer := craneInformerFactory.Ensurance().V1alpha1().PodQOSs()actionInformer := craneInformerFactory.Ensurance().V1alpha1().AvoidanceActions()tspInformer := craneInformerFactory.Prediction().V1alpha1().TimeSeriesPredictions()nrtInformerFactory := craneinformers.NewSharedInformerFactoryWithOptions(craneClient, informerSyncPeriod,craneinformers.WithTweakListOptions(func(options *metav1.ListOptions) {options.FieldSelector = fields.OneTermEqualSelector(metav1.ObjectNameField, hostname).String()}),)nrtInformer := nrtInformerFactory.Topology().V1alpha1().NodeResourceTopologies()newAgent, err := agent.NewAgent(ctx, hostname, opts.RuntimeEndpoint, opts.CgroupDriver, opts.SysPath,opts.KubeletRootPath, kubeClient, craneClient, podInformer, nodeInformer, nodeQOSInformer, podQOSInformer,actionInformer, tspInformer, nrtInformer, opts.NodeResourceReserved, opts.Ifaces, healthCheck,opts.CollectInterval, opts.ExecuteExcess, opts.CPUManagerReconcilePeriod, opts.DefaultCPUPolicy)if err != nil {return err}podInformerFactory.Start(ctx.Done())nodeInformerFactory.Start(ctx.Done())craneInformerFactory.Start(ctx.Done())nrtInformerFactory.Start(ctx.Done())podInformerFactory.WaitForCacheSync(ctx.Done())nodeInformerFactory.WaitForCacheSync(ctx.Done())craneInformerFactory.WaitForCacheSync(ctx.Done())nrtInformerFactory.WaitForCacheSync(ctx.Done())newAgent.Run(healthCheck, opts.EnableProfiling, opts.BindAddr)return nil
}函数主要功能是监控集群中的节点和 Pod,根据资源使用情况进行调度和管理。代码中首先获取了一些配置信息,如节点名、最大不活动时间等。然后通过 Kubernetes 的 API 构建了一个客户端,用于与 Kubernetes 集群进行交互。接着使用 informer 来监听 Kubernetes 集群中的资源变化,包括 Pod、Node、NodeQOS、PodQOS、AvoidanceActions、TimeSeriesPredictions 和 NodeResourceTopologies 等。最后创建了一个 Agent 对象,用于管理节点和 Pod,启动 informer 并等待缓存同步完成后开始运行。在运行过程中,会根据资源使用情况进行调度和管理,并提供了一些额外的功能,如性能分析和绑定地址等。
三、时间序列预测算法-DSP
时间序列预测是指使用过去的时间序列数据来预测未来的值。时间序列数据通常包括时间和相应的数值,例如资源用量、股票价格或气温。时间序列预测算法 DSP(Digital Signal Processing)是一种数字信号处理技术,可以用于分析和处理时间序列数据。
时间序列预测的方法有很多,其中比较常用的方法包括移动平均法、指数平滑法、ARIMA模型、神经网络模型等。这些方法都是基于历史数据的变化趋势,通过对历史数据的分析和建模,来预测未来数据的变化趋势。
在进行时间序列预测时,需要注意以下几点:
- 数据的平稳性:时间序列预测的前提是数据的平稳性,即数据的均值和方差不随时间变化而变化。如果数据不平稳,需要进行差分或者其他方法来使数据平稳。
- 模型的选择:不同的时间序列预测方法适用于不同的数据类型和数据特征。在选择模型时,需要根据数据的特点和预测的目的来选择合适的模型。
- 参数的确定:时间序列预测模型中有很多参数需要确定,比如移动平均法中的窗口大小、指数平滑法中的平滑系数、ARIMA模型中的阶数等。这些参数的确定需要根据数据的特点和模型的性能来进行调整。
- 预测结果的评估:预测结果的好坏需要通过一些指标来进行评估,比如均方误差、平均绝对误差、平均绝对百分比误差等。通过对预测结果的评估,可以对模型进行改进和优化。
Crane使用了离散傅里叶变换、自相关函数等手段,识别、预测周期性的时间序列,其时序预测算法流程如下图,这里详细介绍Crane使用的离散傅里叶变换方法。

3.1、离散傅里叶变换
离散傅里叶变换(DFT),是傅里叶变换在时域和频域上都呈现离散的形式,将时域信号的采样变换为在离散时间傅里叶变换(DTFT)频域的采样。在形式上,变换两端(时域和频域上)的序列是有限长的,而实际上这两组序列都应当被认为是离散周期信号的主值序列。即使对有限长的离散信号作DFT,也应当将其看作经过周期延拓成为周期信号再作变换。在实际应用中通常采用快速傅里叶变换以高效计算DFT。
对监控的时间序列(设长度为 N N N)做快速离散傅里叶变换(FFT),得到信号的频谱图(spectrogram),频谱图直观地表现为在各个离散点 k k k处的「冲击」。 冲击的高度为 k k k对应周期分量的「幅度」, k k k的取值范围 ( 0 , 1 , 2 , … N − 1 ) (0,1,2, … N-1) (0,1,2,…N−1)。
k = 0 k = 0 k=0对应信号的「直流分量」,对于周期没有影响,因此忽略。
由于离散傅里叶变换后的频谱序列前一半和后一半是共轭对称的,反映到频谱图上就是关于轴对称,因此只看前一半 N / 2 N/2 N/2即可。
k k k所对应的周期 T = N k ∙ S a m p l e I n t e r v a l T = {N \over k} \bullet SampleInterval T=kN∙SampleInterval
要观察一个信号是不是以 T T T为周期,至少需要观察两倍的 T T T的长度,因此通过长度为 N N N的序列能够识别出的最长周期为 N / 2 N/2 N/2。所以可以忽略 k = 1 k = 1 k=1。
至此, k k k的取值范围为 ( 2 , 3 , … , N / 2 ) (2, 3, … , N/2) (2,3,…,N/2),对应的周期为 N / 2 , N / 3 , … N/2, N/3, … N/2,N/3,…,这也就是FFT能够提供的周期信息的「分辨率」。如果一个信号的周期没有落到 N / k N/k N/k上,它会散布到整个频域,导致「频率泄漏」。
3.2、Crane中的「候选周期」
Crane没有尝试发现任意长度的周期,而是指定几个固定的周期长度( 1 d 、 7 d 1d、7d 1d、7d)去判断。并通过截取、填充的方式,保证序列的长度 N N N为待检测周期 T T T的整倍数,例如: T = 1 d , N = 3 d ; T = 7 d , N = 14 d T=1d,N=3d;T=7d,N=14d T=1d,N=3d;T=7d,N=14d。
我们从生产环境中抓取了一些应用的监控指标,保存为csv格式,放到pkg/prediction/dsp/test_data目录下。 例如,input0.csv文件包括了一个应用连续8天的CPU监控数据,对应的时间序列如下图:
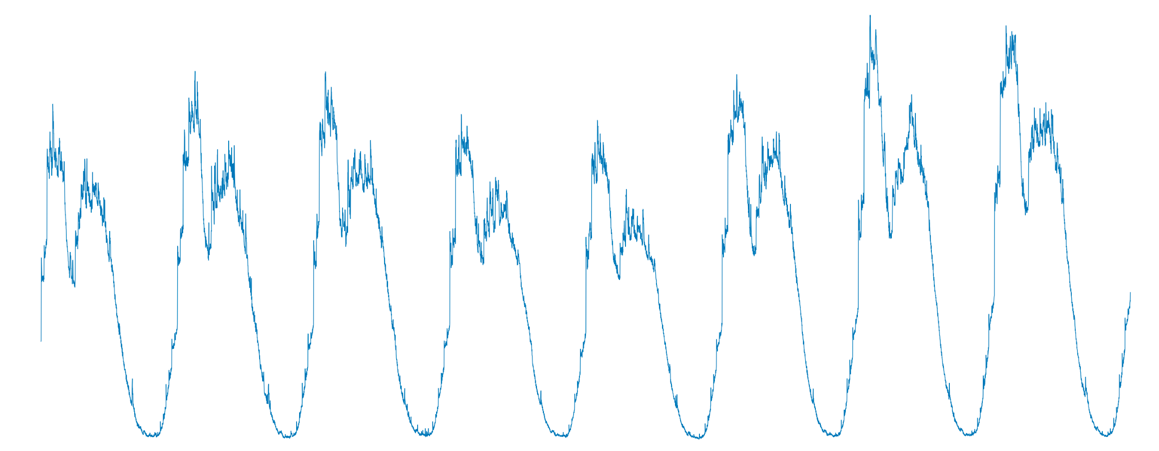
我们看到,尽管每天的数据不尽相同,但大体「模式」还是基本一致的。
对它做FFT,会得到下面的频谱图:
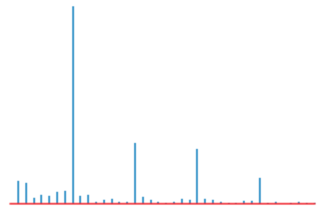
我们发现在几个点上的「幅值」明显高于其它点,这些点便可以作为我们的「候选周期」,待进一步的验证。
上面是我们通过直觉判断的,Crane是如何挑选「候选周期」的呢?
- 对原始序列 x ⃗ ( n ) \vec x(n) x(n)进行一个随机排列后得到序列 x ⃗ ’ ( n ) \vec x’(n) x’(n),再对 x ⃗ ’ ( n ) \vec x’(n) x’(n)做FFT得到 X ⃗ ’ ( k ) \vec X’(k) X’(k),令 P m a x = a r g m a x ∣ X ⃗ ’ ( k ) ∣ P_{max} = argmax|\vec X’(k)| Pmax=argmax∣X’(k)∣。
- 重复100次上述操作,得到100个 P m a x P_{max} Pmax,取 P 99 P99 P99作为阈值 P t h r e s h o l d P_{threshold} Pthreshold。
- 对原始序列 x ⃗ ( n ) \vec x(n) x(n)做FFT得到 X ⃗ ( f ) \vec X(f) X(f),遍历 k = 2 , 3 , … k = 2, 3, … k=2,3,…,如果 P k = ∣ X ( k ) ∣ > P t h r e s h o l d P_k = |X(k)| > P_{threshold} Pk=∣X(k)∣>Pthreshold,则将 k k k加入候选周期。
3.3、应用
Crane提供了TimeSeriesPrediction,通过这个CRD,用户可以对各种时间序列进行预测,例如工作负责的CPU利用率、应用的QPS等等。Kubernetes 的 YAML 配置文件如下:
apiVersion: prediction.crane.io/v1alpha1
kind: TimeSeriesPrediction
metadata:name: tsp-workload-dspnamespace: default
spec:targetRef:apiVersion: apps/v1kind: Deploymentname: testnamespace: defaultpredictionWindowSeconds: 7200 # 提供未来7200秒(2小时)的预测数据。Crane会把预测数据写到status中。predictionMetrics:- resourceIdentifier: workload-cputype: ExpressionQueryexpressionQuery:expression: 'sum (irate (container_cpu_usage_seconds_total{container!="",image!="",container!="POD",pod=~"^test-.*$"}[1m]))' # 获取历史监控数据的查询语句algorithm:algorithmType: "dsp" # 指定dsp为预测算法dsp:sampleInterval: "60s" # 监控数据的采样间隔为1分钟historyLength: "15d" # 拉取过去15天的监控指标作为预测的依据estimators: # 指定预测方式,包括'maxValue'和'fft',每一类可以指定多个estimator,配置不同的参数,crane会选取一个拟合度最高的去产生预测结果。如果不指定的话,默认使用'fft'。
# maxValue:
# - marginFraction: "0.1"fft:- marginFraction: "0.2"lowAmplitudeThreshold: "1.0"highFrequencyThreshold: "0.05"minNumOfSpectrumItems: 10maxNumOfSpectrumItems: 20
该配置文件中:
- apiVersion 指定了使用的 API 版本;
- kind 指定了资源对象的类型;
- maxValue中marginFraction: 拟合出下一个周期的序列后,将每一个预测值乘以1 + marginFraction,例如marginFraction = 0.1,就是乘以1.1。marginFraction的作用是将预测数据进行一定比例的放大(或缩小)。
- metadata 中的 name 和 namespace 分别指定了资源对象的名称和所属的命名空间;
- spec 中的 targetRef 指定了要进行预测的目标对象,包括其 API 版本、类型、名称和所属的命名空间;
- predictionWindowSeconds 指定了提供未来预测数据的时间窗口大小;
- predictionMetrics 中的 resourceIdentifier 指定了要预测的监控指标,type 指定了获取历史监控数据的方式,expressionQuery 中的 expression 指定了获取历史监控数据的查询语句;
- algorithm 中的 algorithmType 指定了使用的预测算法类型,dsp 表示使用数字信号处理算法;
- dsp 中的 sampleInterval 指定了历史监控数据的采样间隔,historyLength 指定了拉取历史监控数据的时间范围;
- dsp 中的 estimators 指定了预测方式和参数,包括使用的算法类型、预测精度等。在该配置文件中,使用了 fft 算法,并指定了一些参数,如 marginFraction、lowAmplitudeThreshold、highFrequencyThreshold 等。
四、腾讯云 Finops Crane 集训营
Finops Crane集训营主要面向广大开发者,旨在提升开发者在容器部署、K8s层面的动手实践能力,同时吸纳Crane开源项目贡献者,鼓励开发者提交issue、bug反馈等,并搭载线上直播、动手实验组队、有奖征文等系列技术活动。既能让开发者通过活动对 Finops Crane 开源项目有深入了解,同时也能帮助广大开发者在云原生技能上有实质性收获。
为奖励开发者,我们特别设立了积分获取任务和对应的积分兑换礼品。
活动介绍送门:https://marketing.csdn.net/p/038ae30af2357473fc5431b63e4e1a78
开源项目: https://github.com/gocrane/crane
这篇关于【腾讯云 Finops Crane 开发者集训营】浅谈Crane的核心概念和原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






