本文主要是介绍Python爬虫遇到法语é变成\u00e9,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
用Python爬虫过程中,尤其是爬取国外网站时候会发现出现一些\u00e9,\u00e8这种
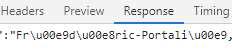
查看原网页发现是一些法文,如é,à,ù等
![]()
其实都是不同编码包含内容不同的问题
一般我们用Python存储数据到文件时候是先编码为其他的编码集,比如gbk,或者常用的utf-8
在这儿我们需要的是它原始信息,所以需要数据原始信息,这儿就要提到unicode-escape编码集
unicode-escape编码集是将unicode通过内存编码值直接存储,这正是我们所需要的
所以只要对网页内容通过unicode-escape直接decode就可以了,不过需要注意的是这时候数据类型是Unicode类型的
![]()
这时候内容就会变成法语音标的信息了
如果还想把法语改为utf-8的网页内容就继续往下看吧~
直接上图:
![]()
记得先引用unicodedata包哦~
normalize()的意思是将其标准化,第一个参数可选的有“NFC”,“NFD”,“NFKC”,“NFKD”
其中,NFC表示字符是一个整体,NFD表示字符是多个字符串合并起来的,所以其标准化后的长度也不一样,NFC的比NFD的要短
同理,NFKC和NFKD也大致是同一个意思,不过这两个新增了兼容性,一般推荐用这两个
而对于后面的decode来说,其函数原型是decode([encoding], [errors='strict'])
第一个参数就是你需要编码的类型
第二个参数控制错误处理的策略,默认的参数就是strict,代表遇到非法字符时抛出异常,它还可以选择为ignore,replace和xmlcharrefreplace 这三个分别代表的意思是忽略非法字符,用?代替非法字符,用XML的字符引用
最后再对相应的字符串改为utf-8就完全从原来的法语改为英语字母啦~~
![]()
PS:新手随笔,有错欢迎指正,转载请指明出处
这篇关于Python爬虫遇到法语é变成\u00e9的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






