本文主要是介绍3、Calibrated Label Ranking Multilabel classification via calibrated label ranking,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文相关内容
本文中解决多标记问题的方法:
标签排名(序)研究的问题是学习从示例例到预先定义的标签集的排名的映射。迄今为止,标签排名的现有方法隐式地在一个基础(实用)尺度上运行,而这个尺度并没有被校准,因为它没有一个自然的“零点”。我们的扩展提出了一种概念上新颖的技术,用于通过成对比较方法将通常的学习扩展到多标记场景,这种设置以前不适合成对分解技术。这种方法的关键思想是引入一种人工校准标签,在每个示例中,它将相关标签与无关标签分离开来。我们表明,该技术可以被视为成对偏好学习和传统相关性分类技术的组合,其中训练单独的分类器来预测标签是否相关。
标签排序


• 多类分类:一个单独的类标签被分配给每个样例x。这隐式地定义了偏好集。输出空间Sc投影到第一个元素。
• L个多标签分类:每个训练示例与L的可能的标签子集相关。这隐式地定义了偏好集。输出空间Sc投影到前l个组件。
多标签分类与排序
我们将研究的任务multilabel排名,这是学习理解为一个模型,将一个查询输入x一个完整的标签集的排名{λ1,……,λc},一分为二的分区设置成相关和不相关的标签。因此,多标签排名可以看作是多标签分类和排名的泛化。

在常规标签排名,一个训练的样例通常由示例x∈X组成,用固定的特征的集合表示,并且在标签上的成对偏好集被解释为。在多标签分类中,训练信息由相关标签的集合Px和不相关标签的集合Nx = L \ Px组成。请注意,此信息可以自动转换成偏好集*。
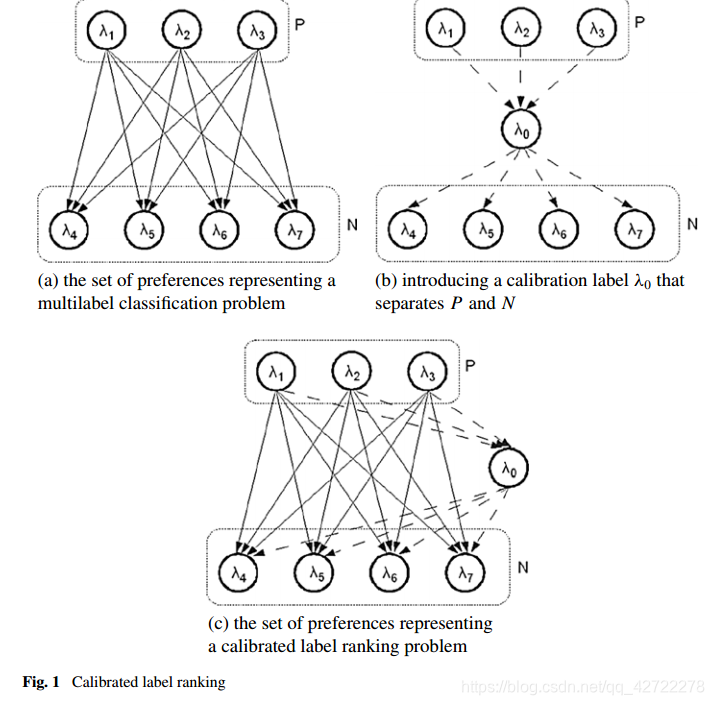
校准的标签排序



总结
1、相关背景:有结构的标签排序形式的输出空间(用标签排序方法解决标签分类)。
2、问题:多标签分类不能形式化为多标签排序。
3、现有解决方案:以我所知除了作者本人的尚不清楚(应该是没有的,要不他写着论文干嘛。)
4、作者的核心思想:克服由于缺乏校准尺度而导致以往标签排名方法的表达能力受到的严重限制。这种方法的关键思想是引入一个标定标签,表示相关标签和不相关标签之间的边界。
5、通过什么样的实验进行验证:在多标签出现较多的3个领域(文本分类、图像分类、生物信息学)的数据集进行了BR\MMP\MLPC\CMLPC等算法在多种度量下的实验,以及固定相关标签和不想关标签边界的实验。
6、对我的启发:没有条件创造条件也要上。
这篇关于3、Calibrated Label Ranking Multilabel classification via calibrated label ranking的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








