本文主要是介绍使用Python+OpenCV统计每日用电量(附代码演练),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

Hexing 预付费电表归PLN所有。这个工具可以用来代替必须由操作人员手动记录的模拟仪表。现在用预付的电表,我可以从KWH,安培,电压和我的信用卡中看到更准确的测量。
本文将是一个使用OpenCV库读取预付表测量值的示例。目前,我使用raspberry pi 4来运行我的代码,使用尺寸为4 x 3.1 x 2.5cm的相机。如果你想要扩展USB线,我建议设置USB线的最大长度为3米。超过3米会失去USB信号,导致摄像头无法连接。
将相机面对预付费电表脉冲LED灯:

设置好相机后,如上图所示,就可以开始测量了。
让我们编码!
kwh_pln_sensor.py
我用这个代码实时监控脉冲LED灯
首先,导入所需的库
from sqlalchemy import create_engine
import cv2
import numpy as np
import pandas as pd
import datetime
import timesqlalchemy是连接数据库(对象关系映射器)的助手,在本例中为PostgreSQL
cv2(开源的计算机视觉库,或称为OpenCV):这个python库可以帮助从相机中过滤出像素颜色,用于过滤红色
pandas使创建矩阵列和行以将数据保存到数据库变得更容易
datetime和time,管理日期和时间格式的库
如果发现ModuleNotFoundError错误,则应该首先安装库
pip install opencv-python
pip install sqlalchemy
pip install pandas创建连接数据库的引擎
conn =
create_engine("postgresql+psycopg2://root:12345678@localhost:5432/plnstats").connect()我用root用户名和密码12345678在本地主机服务器端口5432上创建了名为plnstats的数据库
初始化相机并捕获它。
cap = cv2.VideoCapture(0)
(ret, frame) = cap.read()cv2.VideoCapture(0),你可以根据计算机视频设备索引将索引从0更改为1、2,…等。
cap.read()从相机读取正确的状态帧和图像帧
while True:
(ret, frame) = cap.read()
size = frame.size
image = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)将原始帧转换为RGB颜色,image= cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)



为了使用遮罩滤镜,设置RGB的上下限,我尝试确定恒定的RGB并应用代码
lower = np.array([168, 25, 0])
upper = np.array([179, 255, 255])
mask = cv2.inRange(image, lower, upper)计算红色与非红色的百分比
no_red = cv2.countNonZero(mask)
frac_red = np.divide(float(no_red), size)
percent_red = np.multiply((float(frac_red)), 100)设置阈值,这取决于相机,我使用阈值10.0
if (percent_red >= 10.0):保存到pd.DataFrame
data_capture = {
'color_percentage': percent_red,
'created_on': datetime.datetime.now()
}
df = pd.DataFrame(columns=['color_percentage','created_on'],data=data_capture,index=[0])并保存到数据库中
df.to_sql('home_pln_kwh_sensor', schema='public', con=conn, if_exists='append',index=False)这是kwh_pln_sensor.py的完整代码
from sqlalchemy import create_engine
import cv2
import numpy as np
import pandas as pd
import datetime
import timeconn = create_engine("postgresql+psycopg2://root:12345678@localhost:5432/plnstats").connect()cap = cv2.VideoCapture(0)
(ret, frame) = cap.read()capture_status = Truewhile capture_status:(ret, frame) = cap.read()size = frame.sizeimage = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)lower = np.array([168, 25, 0])upper = np.array([179, 255, 255])mask = cv2.inRange(image, lower, upper)no_red = cv2.countNonZero(mask)frac_red = np.divide(float(no_red), size)percent_red = np.multiply((float(frac_red)), 100)print(percent_red) if (percent_red >= 10.0): #estimated from the red colour percentage impulse LED lampdata_capture = {'color_percentage': percent_red,'created_on': datetime.datetime.now()}df = pd.DataFrame(columns=['color_percentage','created_on'],data=data_capture,index=[0])df.to_sql('home_pln_kwh_sensor', schema='public', con=conn, if_exists='append',index=False)cap.release()
cv2.destroyAllWindows()可以删除第31行中的代码。该语句将帮助你检查相机是否成功捕捉到LED闪烁
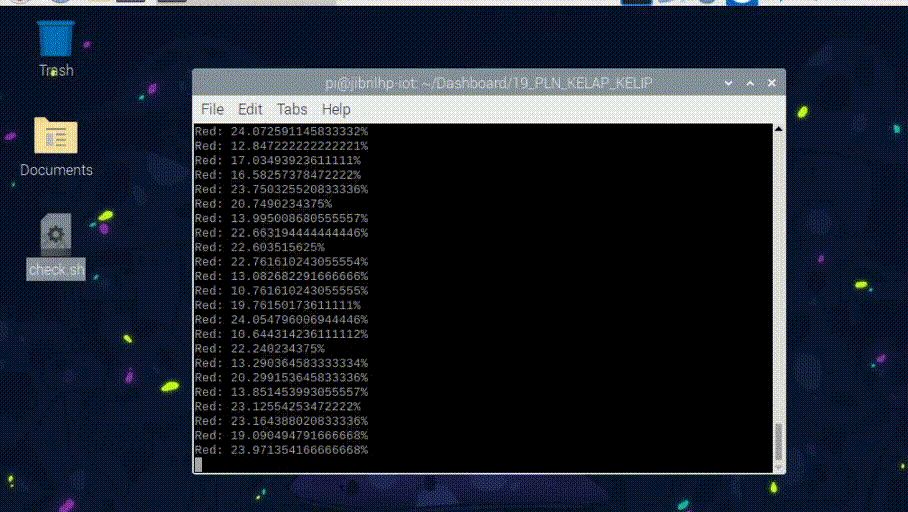
那么如何总结传感器捕获?
我想提取关于小时使用情况和信用卡使用的信息。之后,我就可以估计自己在家的使用情况,并在我的信用卡被清空之前被注意到。
kwh_pln_calculate.py
与前面一样,导入所需的库
import pandas as pd
from datetime import datetime,timedelta
from sqlalchemy import create_engine我用timedelta来得到昨天的日期(你也可以用来计算不同的时间)
创建常量。IMPULSE_KWH = 1000表示每1000个LED闪烁表示1千瓦时,RUPIAH_PER_KWH = 1444.70表示R-1型/TR 1.301-2.200 VA为1444.70卢比
IMPULSE_KWH = 1000
RUPIAH_PER_KWH = 1444.70这一天的值和昨天的值,格式为年-月-日
now_date = datetime.now().strftime('%Y-%m-%d')
yesterday_date = datetime.now() - timedelta(days=1)
yesterday_date = yesterday_date.strftime('%Y-%m-%d')连接PostgreSQL数据库
conn = create_engine("postgresql+psycopg2://root:12345678@localhost:5432/plnstats").connect()我想总结一下昨天kWh的使用情况
df = pd.read_sql(sql='SELECT color_percentage, created_on from public.home_pln_kwh_sensor where created_on >= \'{yesterday} 00:00:00\' and created_on < \'{currdate} 00:00:00\''.format(yesterday=yesterday_date,currdate=now_date),con=conn)将created_on列转换为pandas datetime
df['created_on'] = pd.to_datetime(df.created_on)
df['created_on'] = df['created_on'].dt.strftime('%Y-%m-%d %H:%M:%S')规格化数据,其中一秒只有一个LED闪烁
df = df.drop_duplicates(subset=['created_on'])每小时写一栏,以获取更多说明
df['created_on'] = pd.to_datetime(df.created_on)
df['hour'] = df['created_on'].dt.strftime('%H')
df['day'] = df['created_on'].dt.strftime('%Y-%m-%d')创建一天的清单以检查每天的信用卡使用情况
list_day = list(df['day'].unique())创建一个新的数据帧进行总结
df_summary = pd.DataFrame(columns=['day','hour','sum_impulse','charges_amount'])计算
for dday in list_day:
list_hour = list(df[df['day'] == str(dday)]['hour'].unique())
for y in list_hour:
wSumKWH = df[(df['day'] == str(dday)) & (df['hour'] == str(y))]
df_summary = df_summary.append({'hour':y,'day':dday,'sum_impulse':wSumKWH.groupby('hour').count()['day'][0],'charges_amount':(wSumKWH.groupby('hour').count()['day'][0])*RUPIAH_PER_KWH/IMPULSE_KWH},ignore_index=True)
df_summary.to_sql('home_pln_kwh_hour', schema='public', con=conn, if_exists='append', index=False)
credit_summary = df_summary[df_summary['day'] == yesterday_date].groupby('day').sum()
credit_summary.to_sql('home_pln_kwh_summary', schema='public', con=conn, if_exists='append', index=True)你可以在数据库中查询摘要,也可以像这样从数据帧中提取摘要
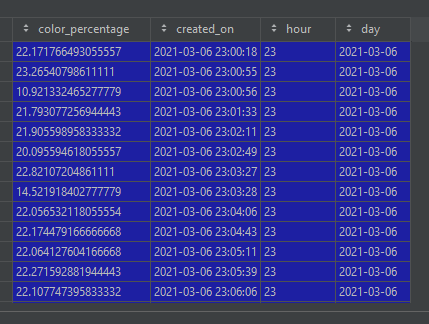
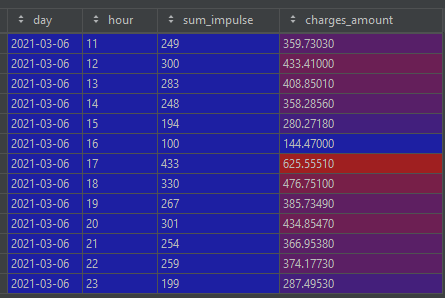
图1为传感器每小时的分组,图2为千瓦时*千瓦时价格计算后的总结
然后,你可以看到每小时的最高价格。
这是kwh_pln_calculate.py的完整代码
import pandas as pd
from datetime import datetime,timedelta
from sqlalchemy import create_engineIMPULSE_KWH = 1000 #depends on prepaid meter
RUPIAH_PER_KWH = 1444.70 # R-1/TR 1.301 – 2.200 VAdef run_cron():now_date = datetime.now().strftime('%Y-%m-%d')yesterday_date = datetime.now() - timedelta(days=1)yesterday_date = yesterday_date.strftime('%Y-%m-%d')conn = create_engine("postgresql+psycopg2://root:12345678@localhost:5432/plnstats").connect()df = pd.read_sql(sql='SELECT color_percentage, created_on from public.home_pln_kwh_sensor where created_on >= \'{yesterday} 00:00:00\' and created_on < \'{currdate} 00:00:00\''.format(yesterday=yesterday_date,currdate=now_date),con=conn)df['created_on'] = pd.to_datetime(df.created_on)df['created_on'] = df['created_on'].dt.strftime('%Y-%m-%d %H:%M:%S')df = df.drop_duplicates(subset=['created_on'])df['created_on'] = pd.to_datetime(df.created_on)df['hour'] = df['created_on'].dt.strftime('%H')df['day'] = df['created_on'].dt.strftime('%Y-%m-%d')list_day = list(df['day'].unique())df_summary = pd.DataFrame(columns=['day','hour','sum_impulse','charges_amount'])#DETAIL PER HOURfor dday in list_day:list_hour = list(df[df['day'] == str(dday)]['hour'].unique())for y in list_hour:wSumKWH = df[(df['day'] == str(dday)) & (df['hour'] == str(y))]df_summary = df_summary.append({'hour':y,'day':dday,'sum_impulse':wSumKWH.groupby('hour').count()['day'][0],'charges_amount':(wSumKWH.groupby('hour').count()['day'][0])*RUPIAH_PER_KWH/IMPULSE_KWH},ignore_index=True)df_summary.to_sql('home_pln_kwh_hour', schema='public', con=conn, if_exists='append', index=False)credit_summary = df_summary[df_summary['day'] == yesterday_date].groupby('day').sum()credit_summary.to_sql('home_pln_kwh_summary', schema='public', con=conn, if_exists='append', index=True)if __name__ == '__main__':run_cron()谢谢你的阅读,希望你可以用它来衡量每个月的用电量
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 mthler」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
这篇关于使用Python+OpenCV统计每日用电量(附代码演练)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





