本文主要是介绍向毕业妥协系列之机器学习笔记:决策树(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一.决策树构建
二.One-hot编码
三.连续值的特征
四.回归树
一.决策树构建
构建一棵具有多个决策结点的大型决策树的构建过程(直接阅读下面的英文,简答易懂):

注:以上英文的专业术语:information gain信息增益
很明显这个构建的过程是一个递归的过程,构建完根节点,在递归构建左右子树。
其中一些参数的设置也有讲究,比如树的最大深度(a maximum depth)越大,那么这棵决策树就越能拟合复杂的数据(更复杂的多项式),但是也增加了过拟合的风险。
二.One-hot编码
我们之前讲的那个例子每个特征只有两个可能的值,但是如果我们现在如果有的特征有两个以上的输出值呢,这就要用到one-hot编码。
现在我们的新例子中耳朵形状这个特征有三个可能可能的值。
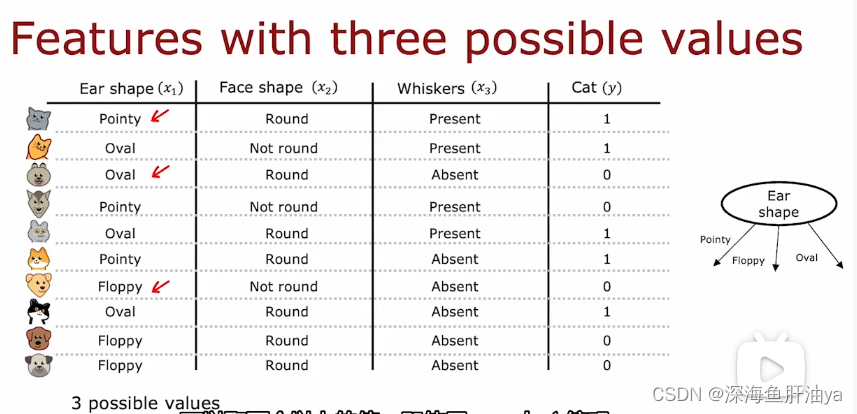
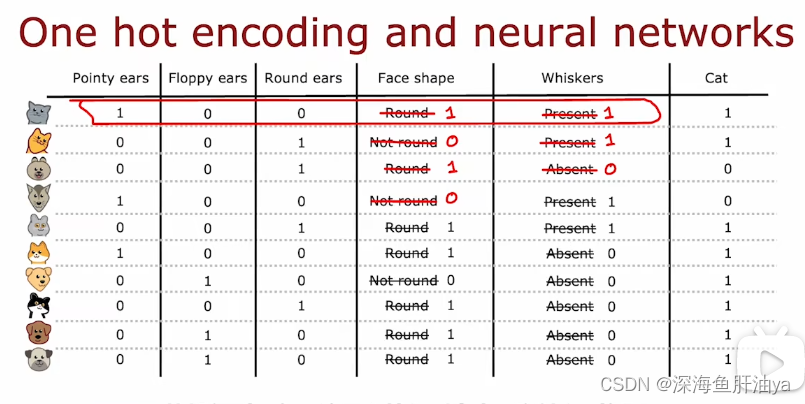
如果某个特征有k(k>2)个可能的值,那么可以把这个特征再分成k个独立的特征,这样又变成是与不是的二进制分类问题了
三.连续值的特征
我们之前举的例子中特征可能的取值都是有两三个(是离散的),但是下面的例子我们添加了一个体重特征(每个猫的体重特征可能都不一样,动物又特别多,如果还是向上面一样有多少个体重值就分出来多少个特征,显然不合适,这个特征可以看作是连续的,所以请看下面的方法)

解决办法:
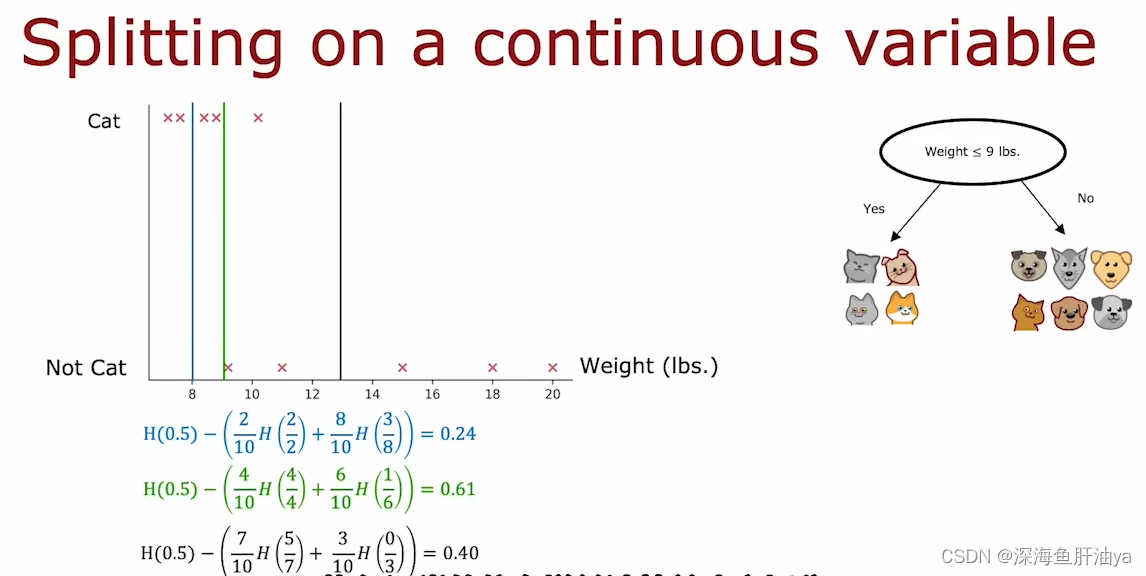
其实就是取阈值,比如我们先取第一个阈值为8(一般是先取所有这个连续特征值的中位数),左上角的函数图像横轴是体重,纵轴是代表是不是猫(即0或1),然后显然图中是猫的点都在上侧,不是猫的点都在下侧,咱们先取了8,看到图中的蓝线,蓝线左侧有两个点(都是猫),蓝线右侧有8个点(3猫5狗),然后咱们按照上篇文章讲的计算熵的方式计算这个阈值分割之后的信息增益(初试状态还是10个动物,5猫5狗)。
然后依次取其他的阈值并分别计算对应的信息增益,最后取最大的那个信息增益对应的阈值,即Weight=9,然后咱们就可以以体重为9当作一个分割线,体重小于等于9的可以看作是猫,体重>9的可以看作是不是猫(因为在我们的常识中,狗一般都比猫重,所以这个思路也比较合理)
四.回归树
我们之前用决策树解决分类问题,如果想用来解决回归问题,那么需要用到决策树的推广,即回归树。
现在的例子如下图,还是最初的那三个特征,这些是输入数据,而最后一列是体重,即我们要根据前面的三个特征来预测这个动物的体重。
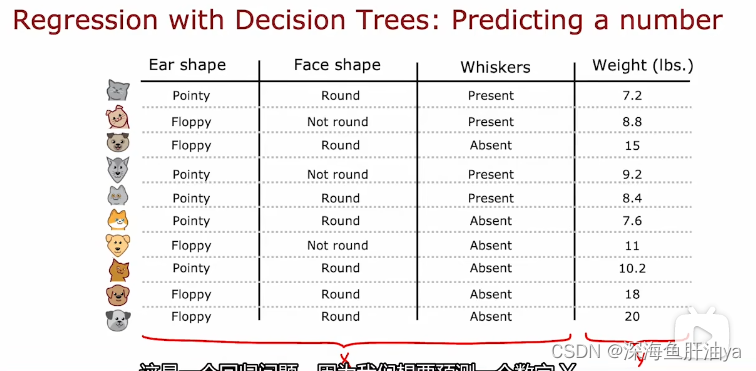
下面是我们构建的一棵决策树,再最终分类结束之后,如何预测体重呢,比如你现在输入的一个动物的其中两个特征是Ear shape是Pointy并且Face shape是Round,那么就会归类到左下角那一类,然后预测的体重就是这一类的平均体重(7.2+8.4+7.6+10.2)/ 4=8.35,其他的类也是这么计算。
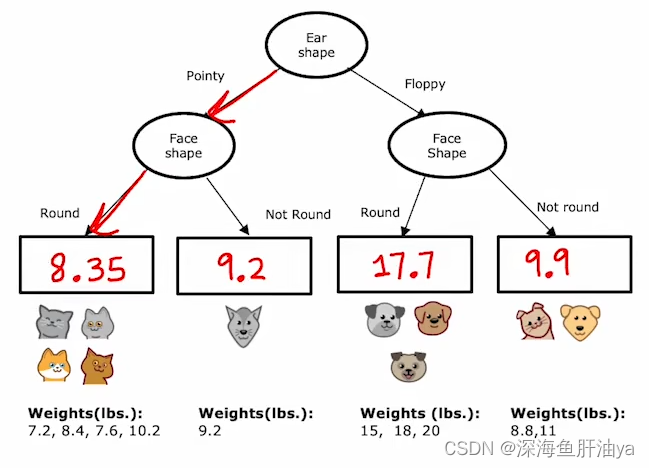
回归树的构建过程:

和之间分类的决策树构建过程有点类似,先创建根节点,决定在根节点上使用哪个特征,分类问题的决策树是需要计算最大的信息增益(即熵减少的最多),而回归的决策树需要计算哪个方差减少的最多,还是要一个一个特征去试,以耳朵形状为例简单讲解一下,用耳朵形状可以分成两类(一边五个,共10个),然后把每边的体重方差计算一下,然后再计算每边的方差和w(即上篇文章提到过的w_lef和w_right),然后看上图中的式子应该就明白了,先计算加权平均方差:
w_left*左边的方差+w_right*右边的方差
然后再计算最初状态的方差(如何计算就不说了吧,小学学过应该),
然后最初状态的方差-(w_left*左边的方差+w_right*右边的方差),其他特征依次计算,最后选取减少的最多的方差对应的那个特征即可。
然后后面的过程就是递归了。
这篇关于向毕业妥协系列之机器学习笔记:决策树(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







