本文主要是介绍向毕业妥协系列之机器学习笔记:决策树(三),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一.使用多个决策树
二.放回抽样
三.随机森林
四.XGBoost
五.何时使用决策树
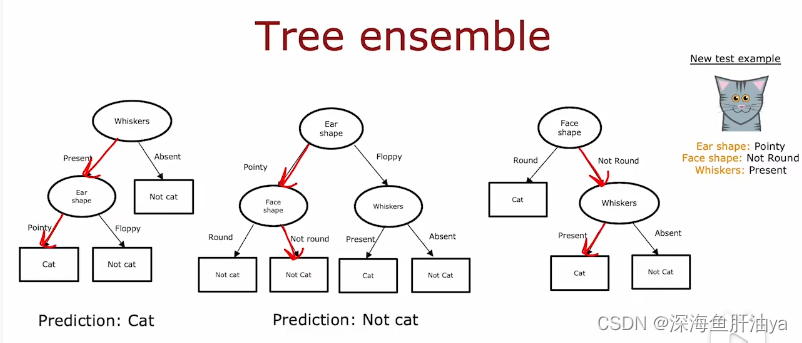
一.使用多个决策树
使用单个决策树的缺点:单个的决策树对于数据的改变非常敏感,比如咱们之前的例子中一直把耳朵形状选择为根节点的特征,但是你可能改变某个猫的某些特征,这样虽然只是改变了十只猫中的一只,但是也会影响决策过程,根节点选择的特征就会改变,这就是一棵新的决策树了。

这就需要多棵树,一个决策树的集合,然后最后让每棵决策树来投票进行对最终结果的判定。
二.放回抽样
放回抽样(Sampling With Replacement): 表示一个项目被选取后,立刻被放回母体合格项目中,因而可能被第二次选取。
举个例子:现在有红绿蓝黄四种颜色的小球各一个,在一个黑色的袋子里,我们从黑袋子里随机去一个,然后放回再取下一个,取四次,不用多说都知道结果是随机的。
我们按照上面那个例子的有放回随机抽样的方式从所有数据集(10个动物)中进行10次有放回随机抽样形成新的数据集。
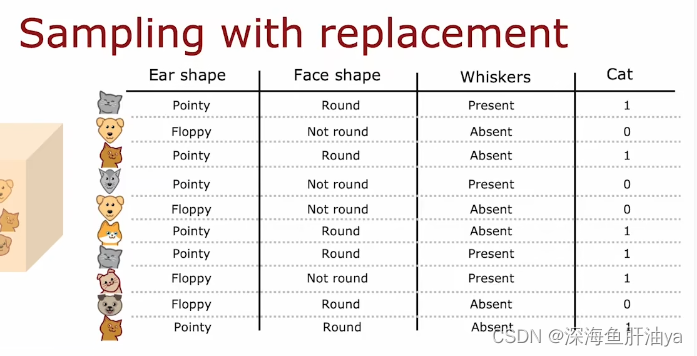
很显然,有放回随机取样生成的训练集可能存在重复的训练示例,或许原来的训练集有的可能在新生成的训练集中不存在,但这都没关系。
三.随机森林
生成一个树的集合:

m是训练集的大小
循环B次,即生成B棵决策树,一般B的取值是大约100,64,228。
当特征非常多时,比如几十个或几百个,我们可以进行随机的特征选择:

关于k的取值,一般有n个特征时,k是取根号下n
随机森林具有更强的健壮性,不会像单棵决策树一样受到某些微小特征的变化的影响。
最后,吴老师讲了个笑话:
机器学习工程师都去哪里露营?随机森林。
哈哈哈哈好冷(手动滑稽)
四.XGBoost
XGBoost可以看做是随机森林的一个改进版。从小到大,上过不知道多少次数学课。也有很多任数学老师,基本上每个数学老师都这么说过,多做好题,多做难题,做100道你会的题不如做一道你不会的题,大致就是这么个意思吧,即学习的时候要抓重难点,改进的随机森林也是这么个道理,请先看下面的英文:

和之前不一样的地方就是当每一轮生成新的训练集时,不是有放回随机选取10个了,即每个训练示例不是等概率选取了,比如在本轮前面的决策树预测时把训练示例A分类错了,那么本轮生成新的训练示例时选取标签A的概率更大一些。
介绍:

实现:
实现起来很复杂,所以一般都是用XGBoost的开源库

五.何时使用决策树
对比决策树和神经网络的优缺点:

tabular:表格的,列成表格的
(比如房价预测的例子数据集就是有结构的,可以表格化的)
transfer learning:迁移学习
(能和迁移学习一起工作是一个优势,可以去看前面的文章,讲过迁移学习)
这篇关于向毕业妥协系列之机器学习笔记:决策树(三)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






