本文主要是介绍python 功能键ord_Python常忘的进阶知识(下),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0.目录
1.装饰器
1.1 为每个函数都增加一个功能
Unix时间戳(Unix时间戳(英文为Unix time、POSIX time或Unixtimestamp),是一种时间的表示方式): 定义为从1970年01月01日00时00分00秒起至现在的总秒数
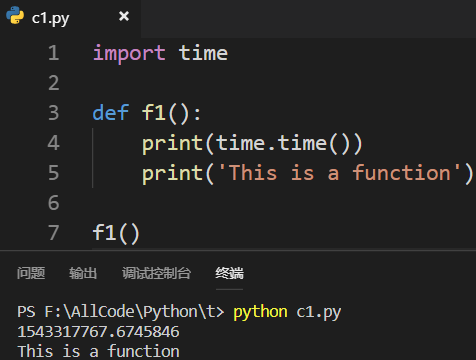
为每一个函数都增加一个打印时间的功能:
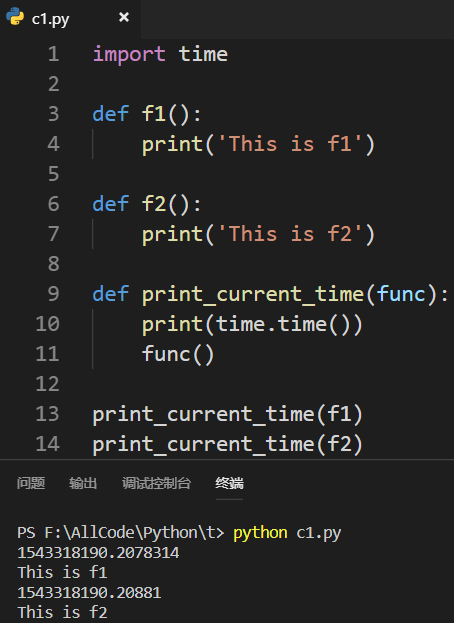 缺点:打印时间这个需求应该属于函数本身,并不是属于新增的函数 这种做法与
缺点:打印时间这个需求应该属于函数本身,并不是属于新增的函数 这种做法与
print(time.time())
f1()
并没有什么区别
1.2 装饰器只是一种模式
这就是装饰器:
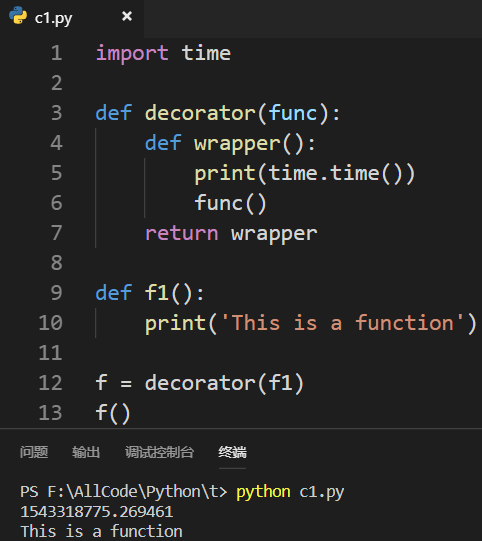 依旧是有缺点的!
依旧是有缺点的!
1.3 语法糖
使用Python给予的语法糖@:(没有改变原来的调用逻辑!)
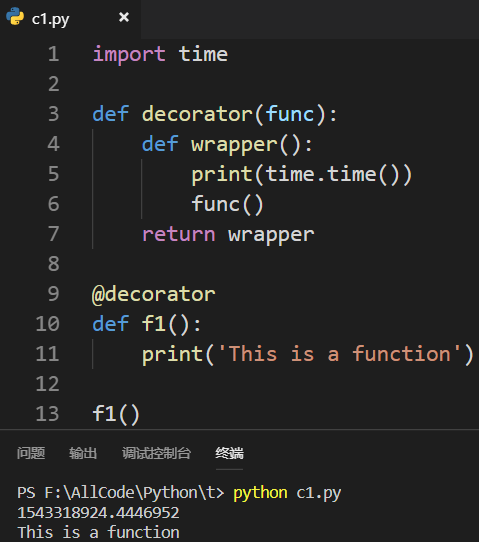
可以接受定义时的复杂,不能接受调用时的复杂! Python中的装饰器体现了AOP的编程思想
1.4 函数需要传递参数,该如何更改装饰器?
使用*args来代表可变参数:
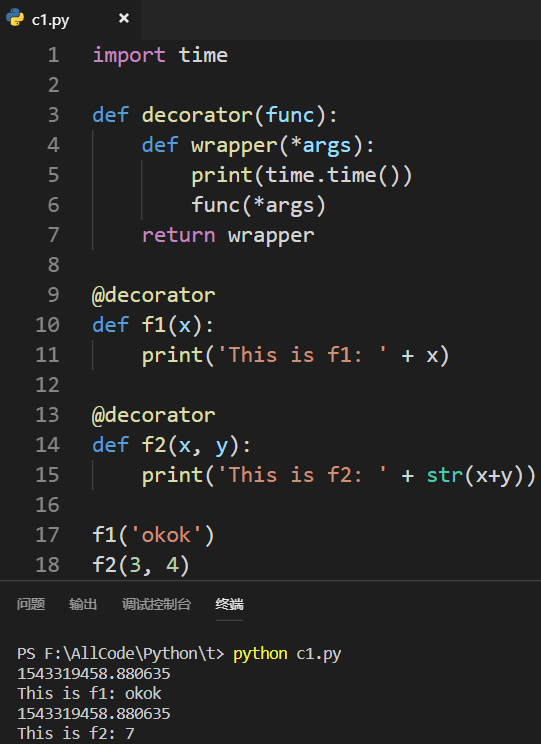
1.5 函数需要传递关键字参数,该如何更改装饰器?
使用**kw来代表可变关键字参数:
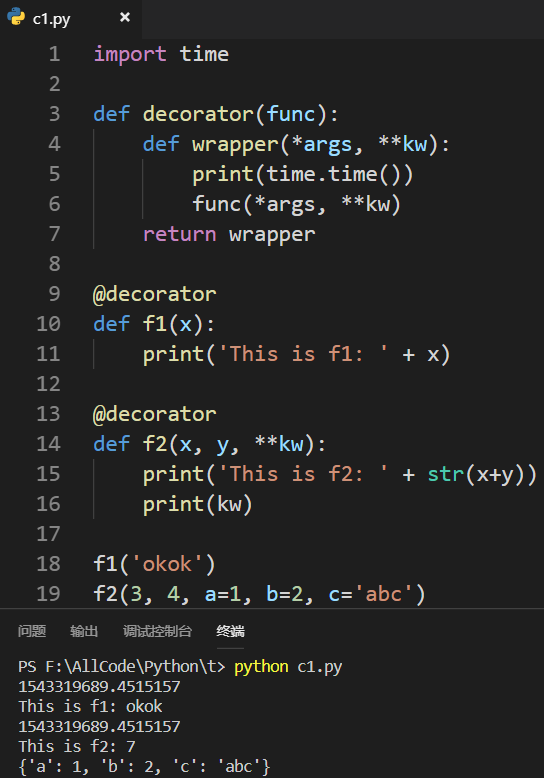
ps:猜测kw的意义可能是key word
2.原生爬虫
2.1 爬虫常规思路
爬虫前奏:
明确目的
找到数据对应的网页
分析网页的结构找到数据所在的标签位置
正式编码:
模拟HTTP请求,向服务器发送这个请求,获取到服务器返回给我们的HTML
用正则表达式提取我们要的数据(名字,人气)
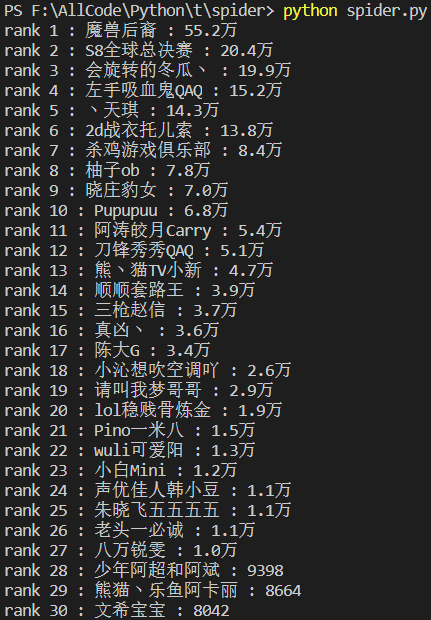
此原生爬虫的目的是爬取熊猫直播https://www.panda.tv/cate/lol这个页面的所有主播名称与人气,然后依据人气进行排序
2.2 HTML结构分析基本原则
三个原则:
尽量选取具有唯一标识性的标签作为定位标签
尽量选取最接近要提取的数据的标签
尽量选取可以闭合的标签
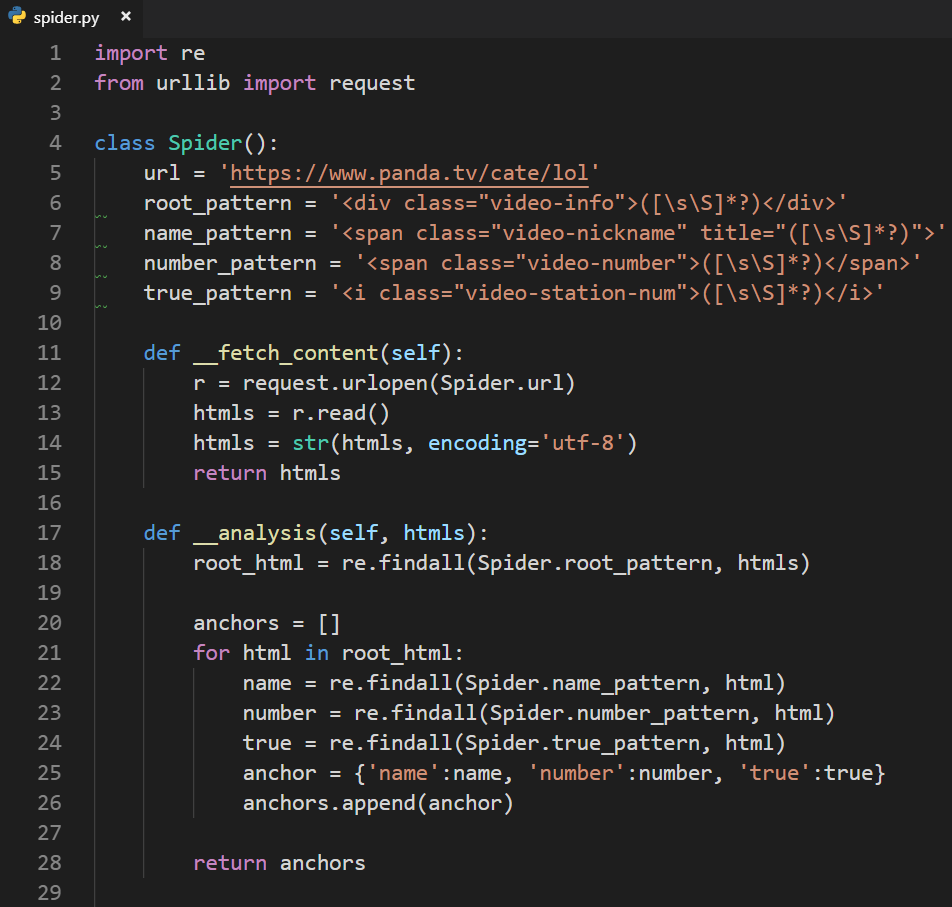
采用面向对象的方式编写爬虫:
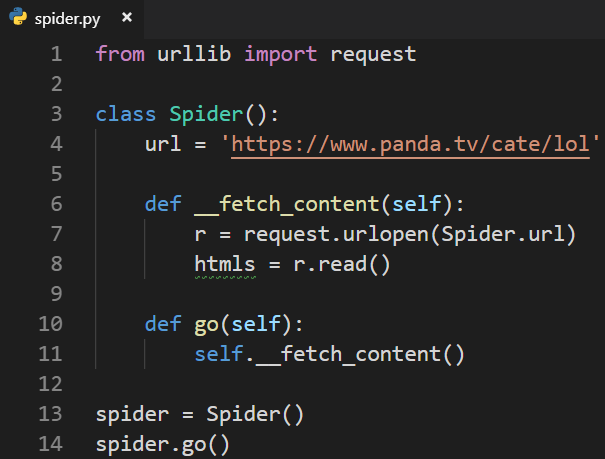
分析页面获得数据结构: htmls(一组数据):
主播姓名
观看人数
真实人数
主播姓名
观看人数
真实人数
主播姓名
观看人数
真实人数
......
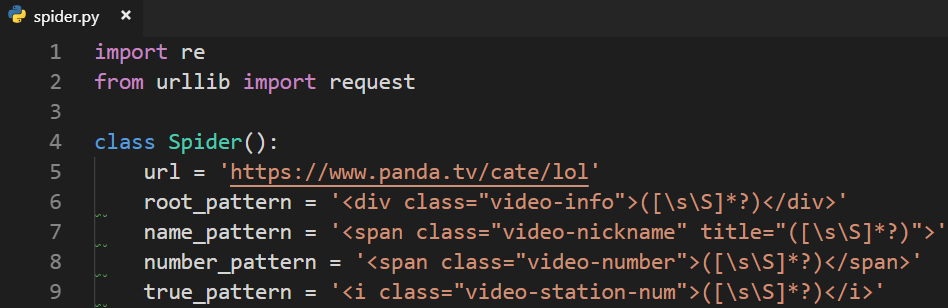
2.3 正则分析HTML
分析每组数据:
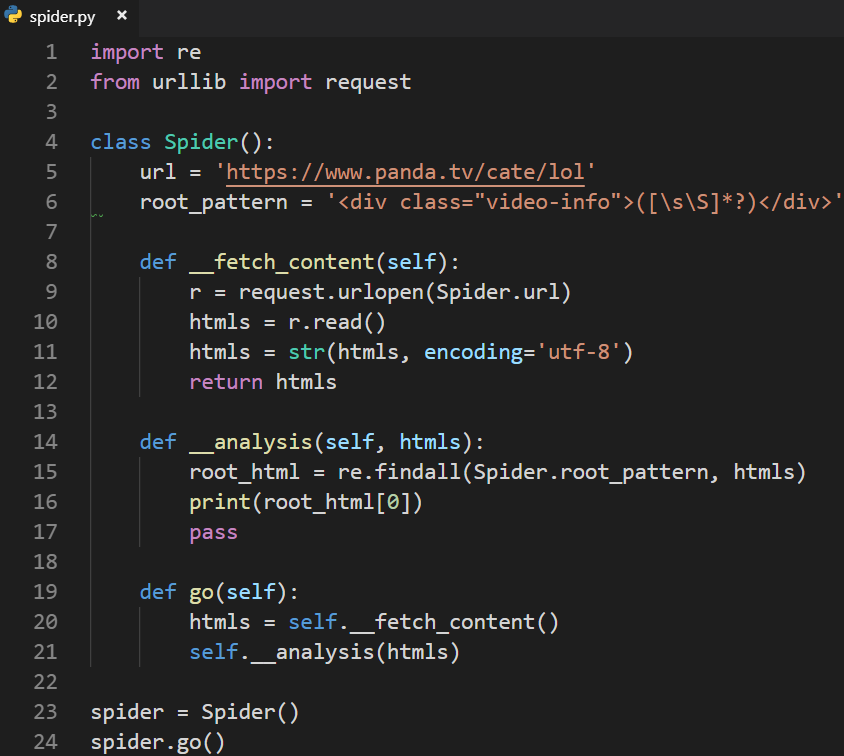
2.4 正则分析获取名字和人数
单项数据匹配规则:
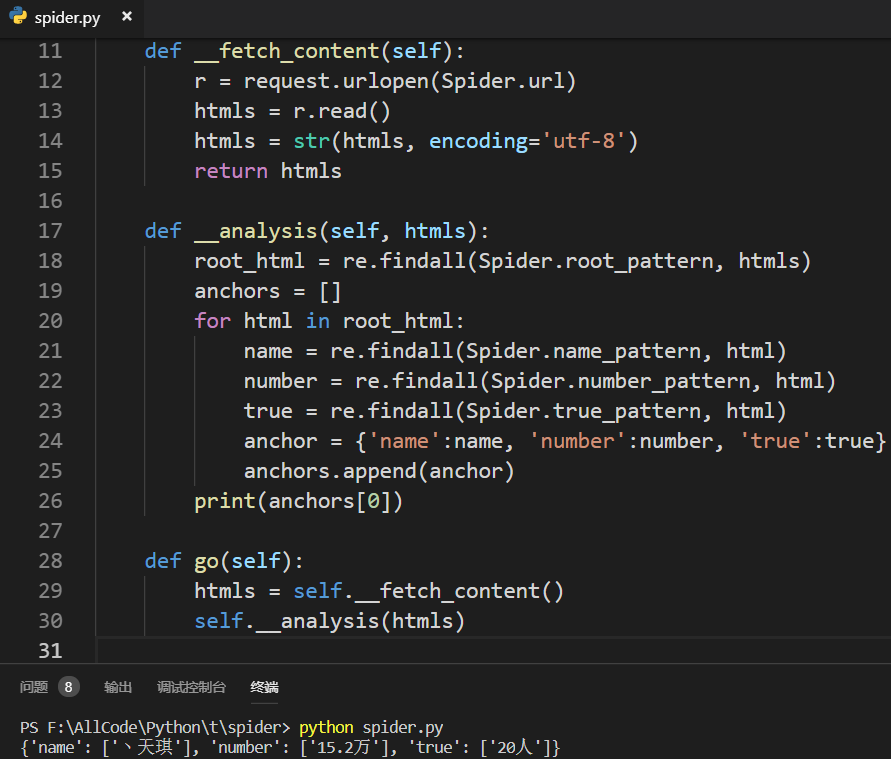
输出第一项提取的数据:
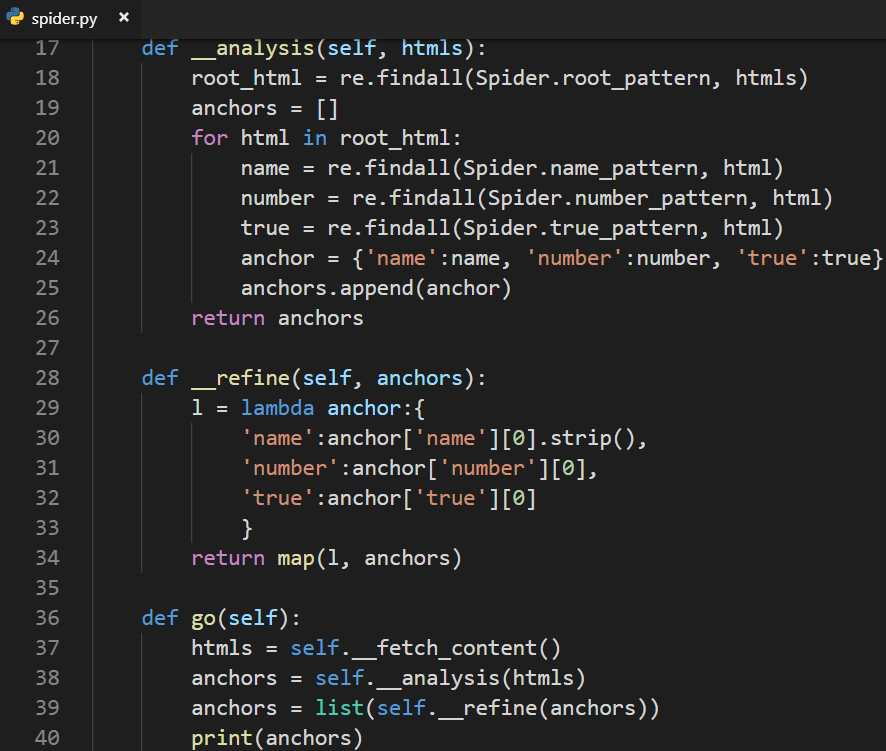
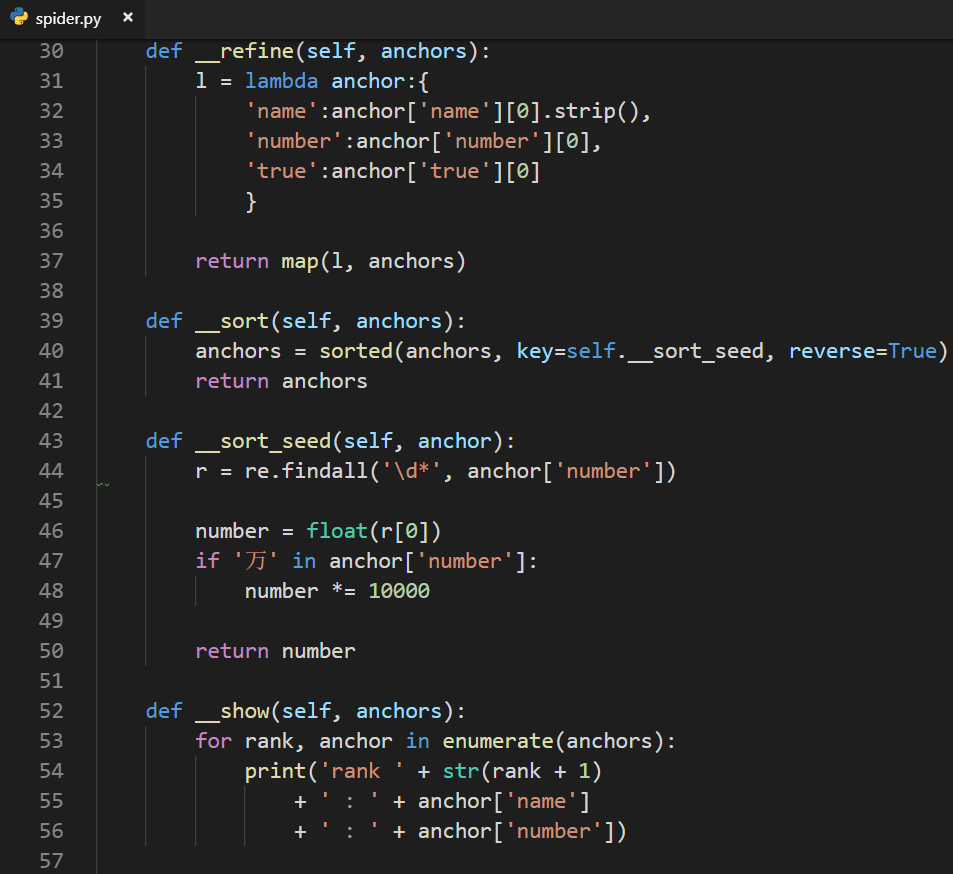
2.5 数据精炼与排序
数据精炼:
去掉主播名称前后的空格和换行符
把列表转化为单一的字符串的值
将数据进行精炼:(使用字符串.strip()去掉字符串首尾的空格和换行符)
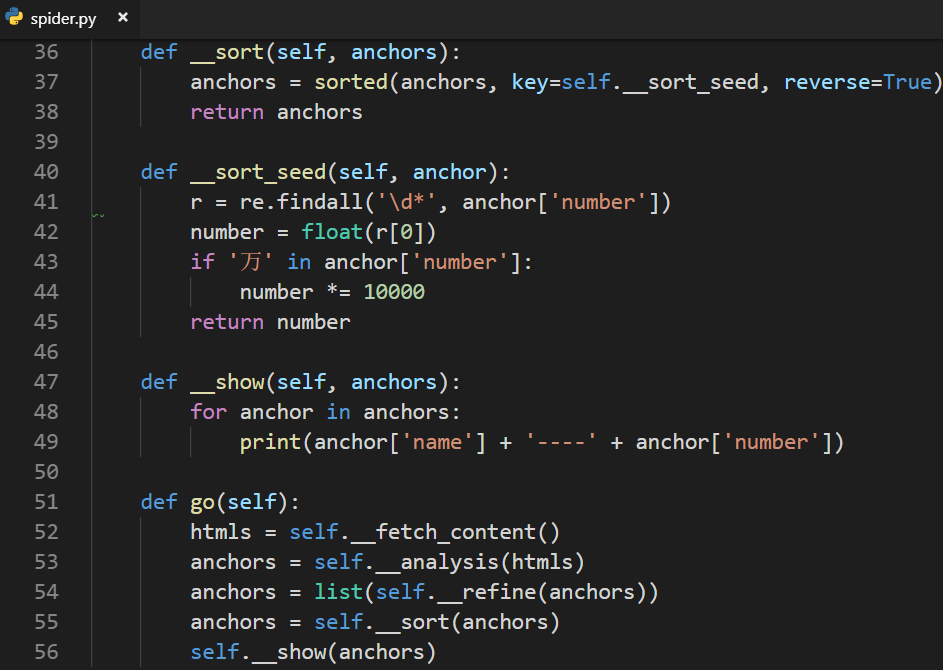
对数据进行排序:
Python内置函数sorted()可以方便排序
reverse=True则为降序排序
设置排序种子__sort_seed()函数
2.6 案例总结
修改一下输出格式:
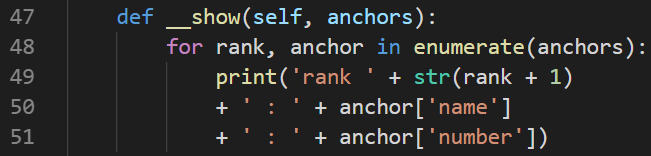
最终不太面向对象的代码:
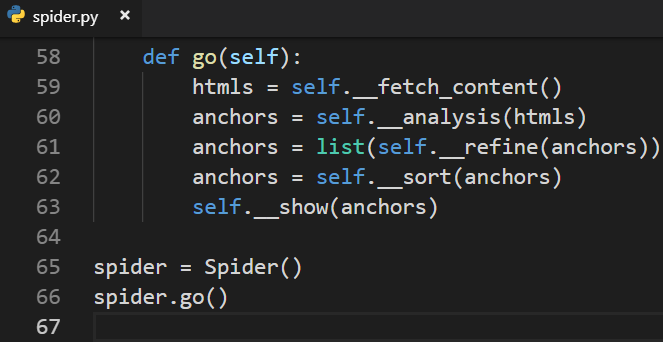
3.补充知识点
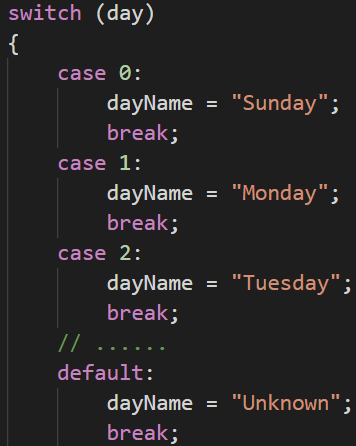
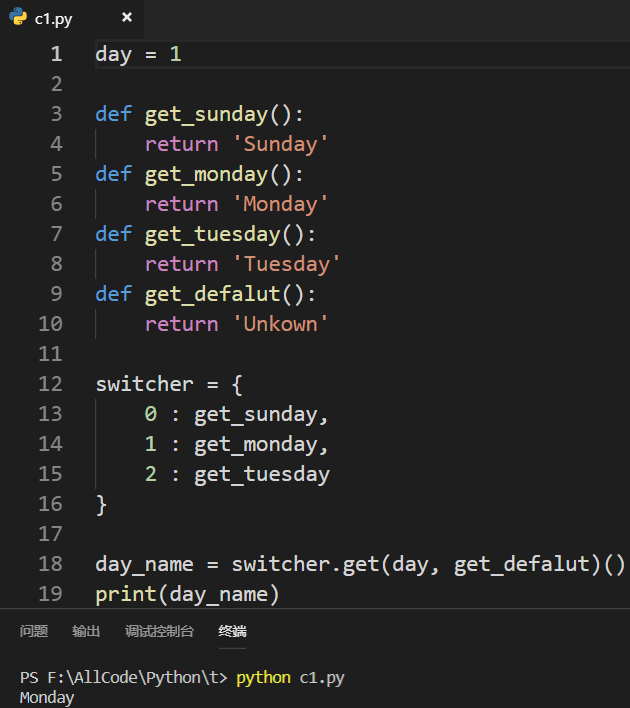
3.1 用字典映射代替switch case语句
C++中的switch case
Python使用字典:
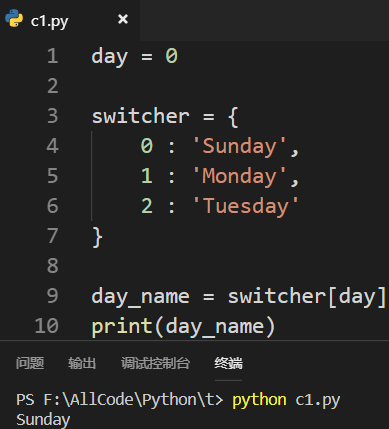 defalut功能没有解决!
defalut功能没有解决!
不使用下标来取值:
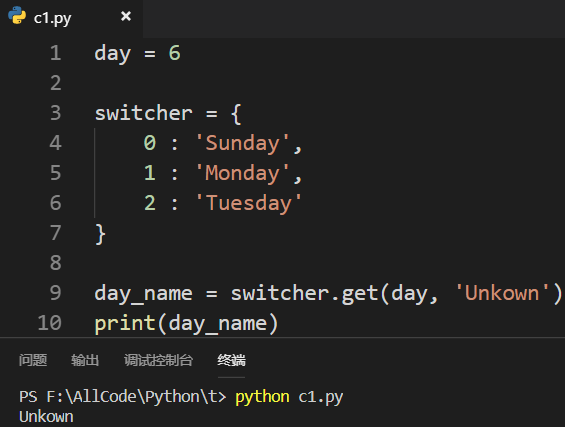 返回值改为返回函数:
返回值改为返回函数:
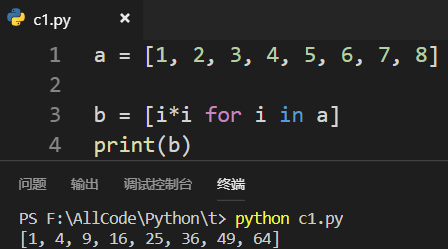
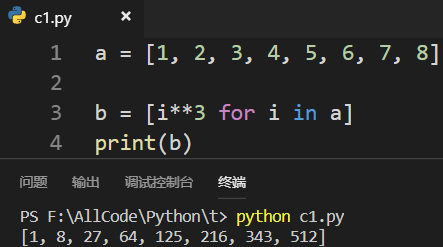
3.2 列表推导式
求平方、求立方:
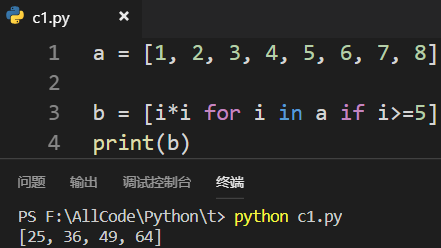
只对列表中部分元素进行操作:
集合(set)也可以被推导:
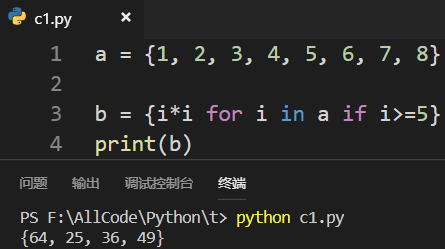 ps:字典(dict)和元组(tuple)也可以被推导
ps:字典(dict)和元组(tuple)也可以被推导
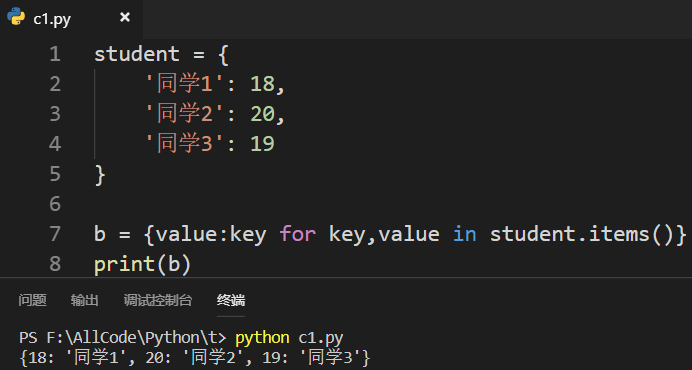
3.3 字典如何编写列表推导式
将key和value颠倒顺序:
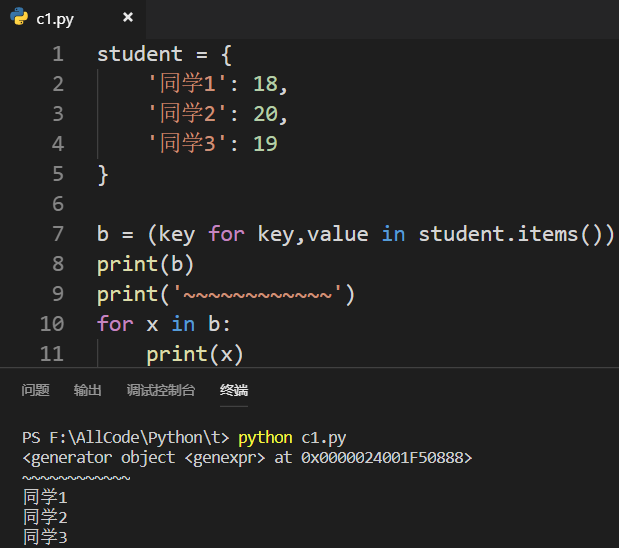
元组是不可变的:
3.4 迭代器(iterator)
可迭代对象(iterable)——凡是可以被for...in...循环遍历的数据结构都是可迭代对象,比如列表、元组、集合
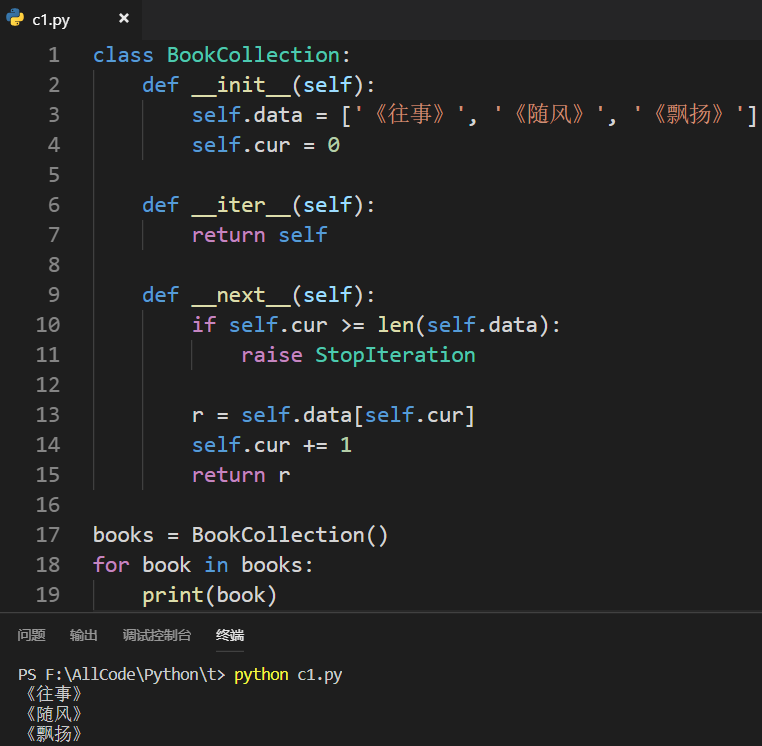
迭代器(iterator)
迭代器是一个对象(class)
迭代器可以被遍历,普通对象不可以被遍历
如何让普通对象变成迭代器? 只需实现两个函数——def __iter__(self): 和 def __next__(self):
for...in...循环的实质在于会不断地去调用迭代器里面的__next__()方法:
也可以不用for...in...循环遍历:
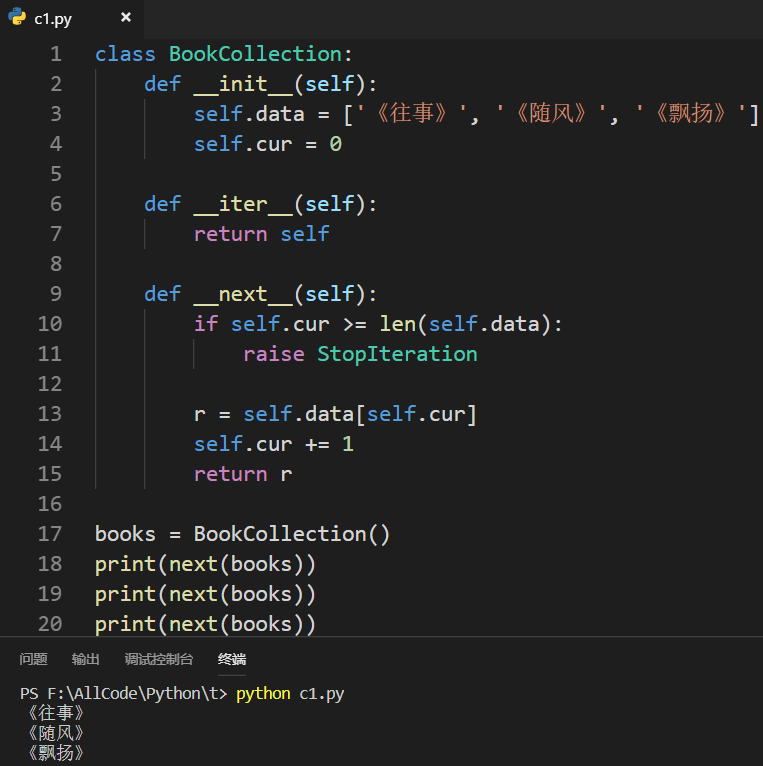
迭代器具有一次性,第一次已经用完了,第二次就不会输出任何值! 列表、元组、集合无论遍历多少次都会输出相同的结果!
如何遍历多次迭代器? 1.再次实例化一个对象
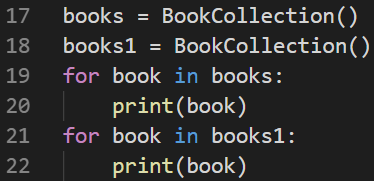 2.拷贝对象
2.拷贝对象
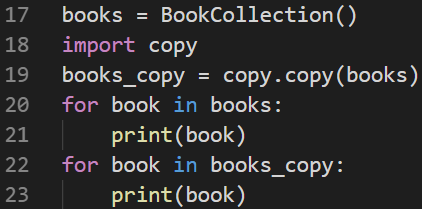 ps:copy.copy()实现的是浅拷贝 pps:copy.deepcopy()实现的是深拷贝
ps:copy.copy()实现的是浅拷贝 pps:copy.deepcopy()实现的是深拷贝
3.5 生成器(generator)
生成器是对于函数来说的 输出0~10000:
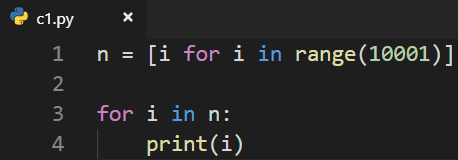 缺点:非常消耗内存,因为n是列表,有10001个数,都存在内存中
缺点:非常消耗内存,因为n是列表,有10001个数,都存在内存中
如何输出0~10000,同时又不需要把0~10000所有的数字都存储在计算机中?
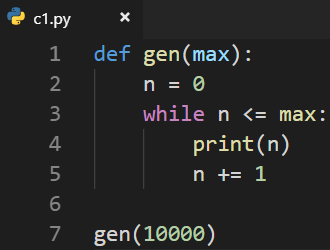 优点:解决了性能问题 只是一个普通的函数,并不是生成器 缺点:实现的目的太过于特殊了,直接在函数内部输出了数字,假如最终目的不是输出数字,而是得到数字用来做别的事情...... 在函数外部调用函数真实的目的应该是函数返回0~10000个数字,但是我怎么用,函数应该不要管,更不应该在函数内部输出数字
优点:解决了性能问题 只是一个普通的函数,并不是生成器 缺点:实现的目的太过于特殊了,直接在函数内部输出了数字,假如最终目的不是输出数字,而是得到数字用来做别的事情...... 在函数外部调用函数真实的目的应该是函数返回0~10000个数字,但是我怎么用,函数应该不要管,更不应该在函数内部输出数字
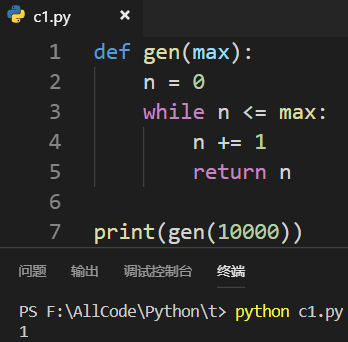
将return改为yield后,就会返回一个生成器:
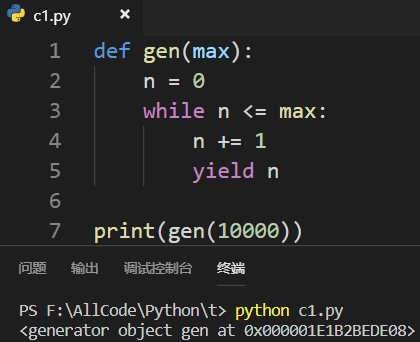
如何使用生成器: 1.使用next()函数
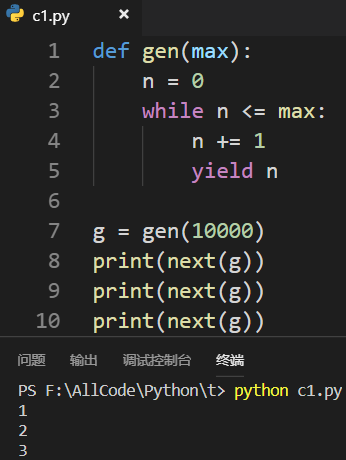 2.使用for...in...循环遍历
2.使用for...in...循环遍历
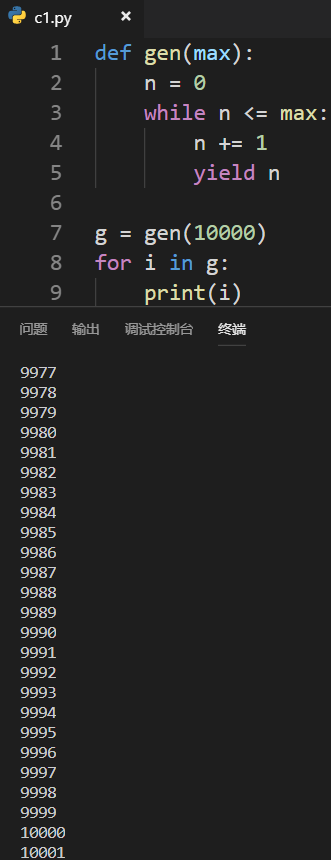
生成器的优势
既保证了函数的通用性,又解决了性能问题
生成器内部根本就没有保存任何的数据,实质是保存了一个算法
通过算法不断地生成新的数字
列表推导式也可以得到生成器(把中括号改成小括号):
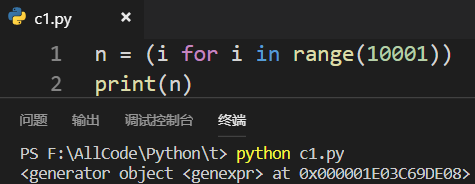
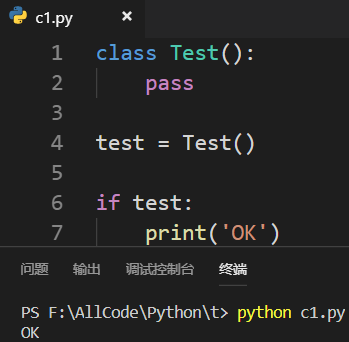
3.6 对象存在并不一定是True
对象存在:
将对象长度置为0:
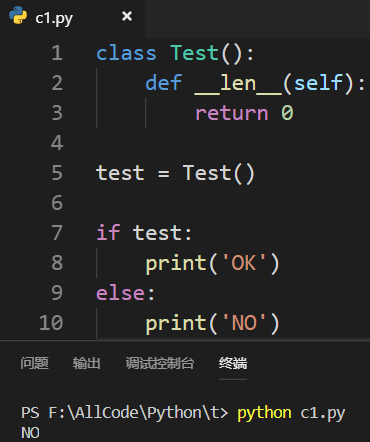
对象的真假由两个内置方法决定——__len__与__bool__内置方法! 1.不定义__len__()方法与__bool__()方法时默认为True
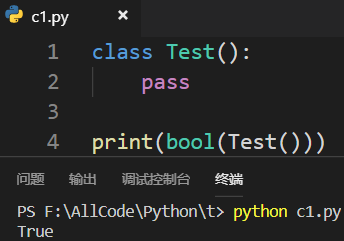 2.定义__len__()方法时——__len__()方法必须返回大于等于0的整数或者True或者False
2.定义__len__()方法时——__len__()方法必须返回大于等于0的整数或者True或者False
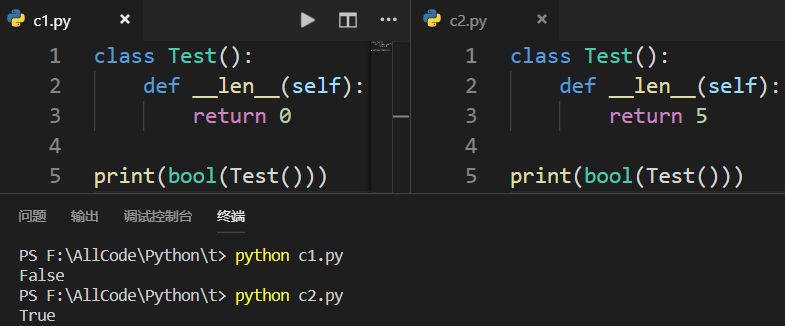 ps:当使用 bool() 方法或者 len() 方法时会调用__len__()方法 3.定义__bool__()方法时——__bool__()方法必须返回True或者False,不能返回0或者1
ps:当使用 bool() 方法或者 len() 方法时会调用__len__()方法 3.定义__bool__()方法时——__bool__()方法必须返回True或者False,不能返回0或者1
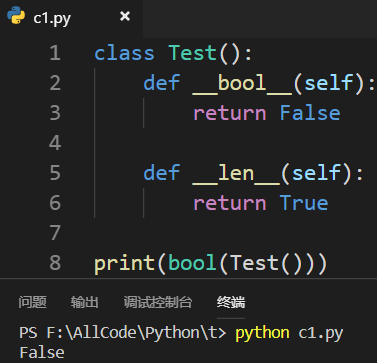 4.定义了__bool__()方法后,取bool(对象)的值不会再调用__len__()方法
4.定义了__bool__()方法后,取bool(对象)的值不会再调用__len__()方法
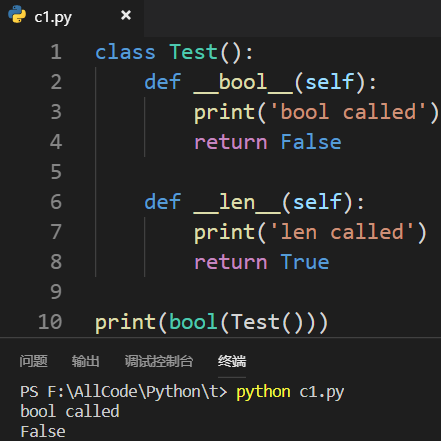
3.7 装饰器的副作用
加了装饰器后,函数f1的名称变为wrapper了:
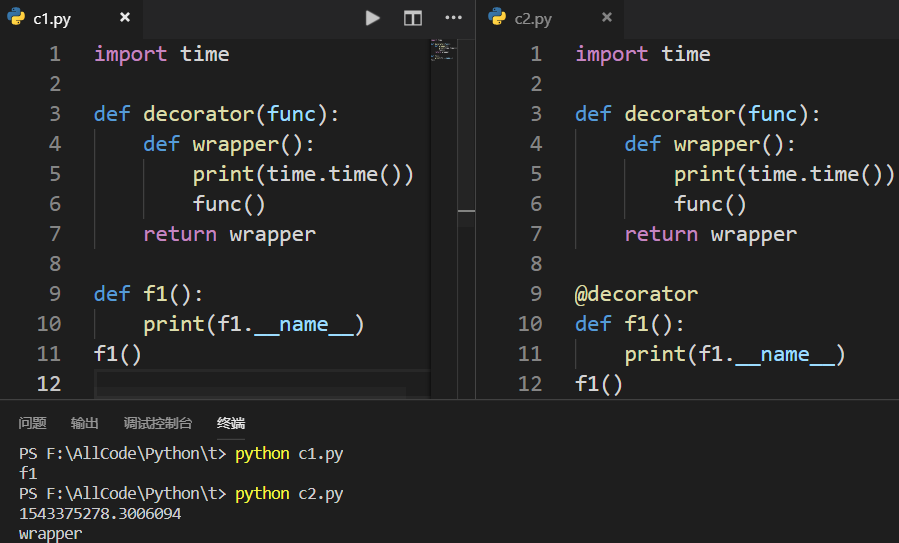
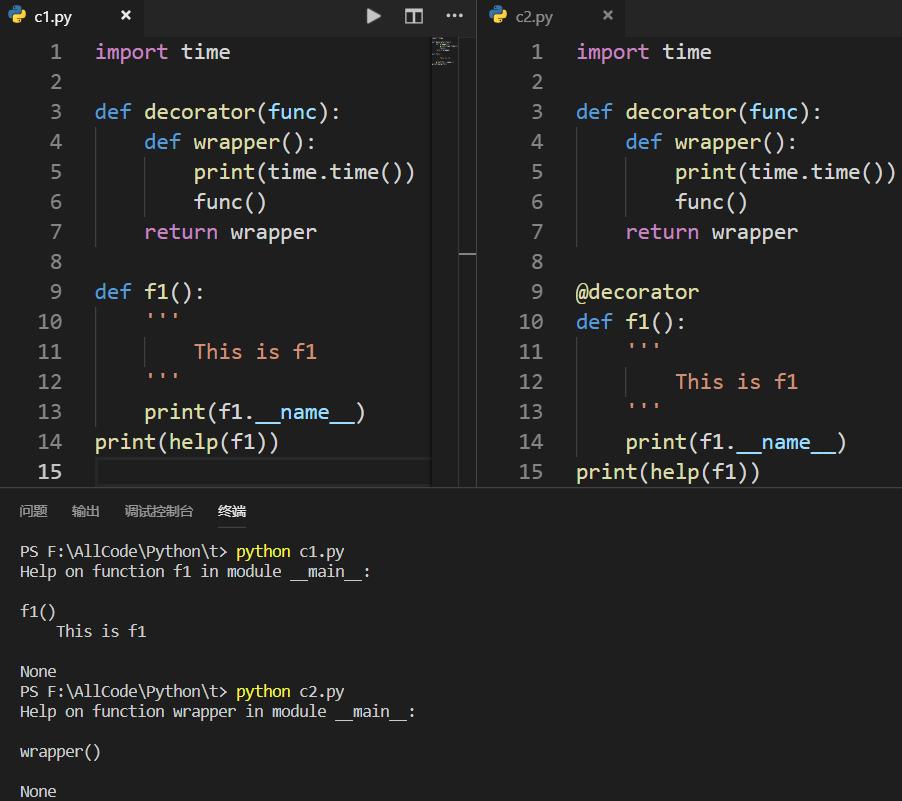
加了装饰器后查找不到帮助文档了:
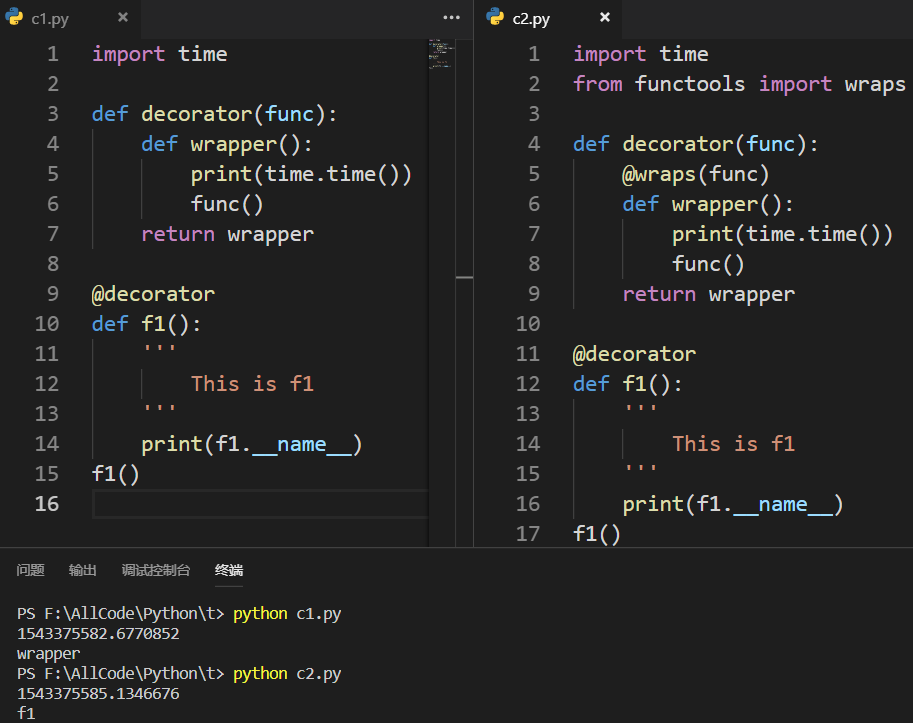
Python提供了另一个装饰器来解决这个函数名称会被改变的问题:
这篇关于python 功能键ord_Python常忘的进阶知识(下)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




