本文主要是介绍[Python] 文件操作,你学废了吗,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🔥 信仰:一个人走得远了,就会忘记自己为了什么而出发,希望你可以不忘初心,不要随波逐流,一直走下去
🦋 欢迎关注🖱点赞👍收藏🌟留言🐾
🦄 本文由 程序喵正在路上 原创,CSDN首发!
💖 系列专栏:Python从入门到入坟
🌠 首发时间:2022年5月16日
✅ 如果觉得博主的文章还不错的话,希望小伙伴们三连支持一下哦
目录
- ① 写在前面
- ② 怎么从文件中读取数据
- ③ 怎么写数据到文件中
- ④ 案例:计算文件中关键字出现次数
- ⑤ 浅谈Python处理大数据文件
① 写在前面
文件是计算机中具有特定标识的存储区,它由操作系统管理,用于支持计算机操作系统的使用过程中的各项操作。
对于文件,相信大家都不陌生,但是在接触到计算机的文件之前,我们通常将文件定义成内容的载体,例如以前那些保存在文件包的纸质资料文件。
计算机的文件也一样,它是存储在计算机存储区的信息集合,这些信息有很多用途,有的是用来支撑程序的运行,有的是单纯用于存储等。文件使用文件扩展名指示文件类型,如常用的 PNG 格式的图像文件使用 .png 文件扩展名,还有 .jpg,.gif 等等。
由于我们将大量的待处理信息存储在文件中,当处理这些信息时需要通过 Python 来调用这些信息进程序,然后在程序中对其进行处理。
通过这种方式,我们可以让程序可以处理任何指定位置的文件。
② 怎么从文件中读取数据
我们如果想让 Python 程序去使用计算机存储区的文件,就要遵从 Python 文件操作的规定,依顺序进行读取,若是随便处理就会使文件内容变得很不安全。
简单来说,想要在 Python 程序中读取文件,先要使用 Python 内置的 open 函数通过提供文件路径的方式将文件和程序链接起来,之后便可以通过操作文件对象的方法处理文件。
接下来让我们通过一段代码来看看读文件操作是如何进行的。
首先我们在桌面创建一个 test.txt 文件,并在其中输入几行英文来进行测试
例如这样

file = open("C:/Users/15269/Desktop/test.txt") # 填入你在桌面创建的文件的绝对路径
while True:line = file.readline()if len(line) == 0:breakprint(line,end=" ")
file.close()
程序执行结果如下:
Python is a excellent language
this is a statement
上面的程序十分清晰地展现了文件操作中打开文件,对文件操作,关闭文件的步骤。
程序的第 1 行我们使用了之前提到的 open 函数建立了一个 file 对象,程序的第 3 行使用了 file 对象的 readline 方法一行一行地读取文件,当再次调用 readline 时会自动跳到文件的下一行。程序的第 7 行使用 close 方法将文件关闭,其实这个操作是可选的,因为 Python 中一旦对象不再被引用,则这个对象的内存就会被自动回收。但是从另一方面来说,手动调用没有任何坏处,并且,随着程序越做越大,这是一个很好的习惯。
上面是一个很简单的程序,但是 Python 给我们提供的文件操作并非如此简单。
下面是有关 Python 读取文件中的其他常见操作。
| 操作 | 描述 |
|---|---|
| file.readall() | 读入整个文件内容,返回一个字符串或字节流 |
| file.read(size=-1) | 从文件中读入整个文件内容,如果给出参数,读入前 size 长度的字符串或字节流 |
| file.readline(size=-1) | 从文件中读入一行内容,如果给出参数,读入该行前 size 长度的字符串或字节流 |
| file.readlines(size=-1) | 从文件中读入所有行,以每行为元素形成一个列表,如果给出参数,读入 size 行 |
| file = open(“path”,“r”) | path 指文件目录,“r” 表示读入 |
| string = file.read() | 将这个文件读入一个字符串中 |
| string = file.read(N) | 从文件当前位置读取之后的 N 个字节到字符串中 |
| list = file.readlines() | 将文件按行读到列表中,前面的程序使用这条语句 list 的值为 [‘Python is a excellent language\n’, ‘this is a statement\n’] |
| for line in open(“path”) | 迭代一行一行地读取 |
注意:字符串或字节流取决于文件打开模式,如果是文本方式打开,返回字符串;否则返回字节流。
这里顺便说一下文件的打开模式:
| 文件打开模式 | 描述 |
|---|---|
| ‘r’ | 只读模式,如果文件不存在,返回异常 FileNotFoundError,默认值 |
| ‘w’ | 覆盖写模式,文件不存在则创建,存在则完全覆盖 |
| ‘x’ | 创建写模式,文件不存在则创建,存在则返回异常 FileExistError |
| ’a’ | 追加写模式,文件不存在则创建,存在则在文件最后追加内容 |
| ‘b’ | 二进制文件模式 |
| ‘t’ | 文本文件模式,默认值 |
| ‘+’ | 与 r/w/x/a 一同使用,在原功能的基础上增加同时读写功能 |
③ 怎么写数据到文件中
前面我们说到了怎么从文件中读取内容到程序中,写数据的顺序其实和读文件差不多,具体过程为建立文件链接,写数据和关闭文件。
下面让我们通过一个简单的程序来看看写数据到文件是如何操作的。
poem = '''Hold fast to dreams.
For if dreams die.
Life is a broken-winged bird.
That can never fly.
Hold fast to dreams.
For when dreams go.
Life is a barren field.
Frozen only with snow.
'''file = open("C:/Users/15269/Desktop/poem.txt", "w") # 填入你要创建文件的位置
file.write(poem)
file.close()
程序执行之后,我们就会惊奇地发现,在我们的桌面多出了一个 poem.txt ,打开一看,它的内容如下:

程序的输出是程序的第 11 行中路径指定的 txt 文件内容,本程序其实在 Python 解释器中没有输出。
程序的第 1~9 行使用三引号 ‘’‘…’‘’ 给变量 poem 指定了带有换行的字符串,第 11 行使用带有目录的 open 函数指定具体的文件,同时给本次操作指定操作模式为 w。操作模式 w 表示打开一个文件只用于写入。如果该文件已存在,则将其覆盖。如果该文件不存在,创建新的文件。
第 12 行使用 write 函数将 poem 写入文件,最后将文件关闭。
此时写入文件已经完成,在对应的目录下会出现该文件。
程序中出现的 write 函数是一个很常见的函数。
下面我们来看有关写入文件的另一些常见用法。
注意:文件指针一开始是在第一行的
| 操作 | 解释 |
|---|---|
| file = open(“path”, “a”) | 如果该文件已经存在,文件指针将移动到结尾用于追加。新内容会被写入到已有的内容后面。如果文件不存在,会先创建文件再进行上述操作 |
| file.writelines(list) | 将列表中所有字符串写入文件中 |
| file.seek(N) | 将文件指针设置到当前向后加 N 处用于下一次操作 |
下面让我们通过程序来更直观地理解这些操作。
1、我们在前面创建的文件后再写入一些内容,操作如下:
file = open("C:/Users/15269/Desktop/poem.txt", "a")
word = '''Kindness is a language
which the deaf can hear
and the blind can see.
'''
file.write(word)
file.close()
程序运行后文件内容如下:

2、我们将一个列表中的字符串写入到文件中,操作如下:
file = open("C:/Users/15269/Desktop/poem.txt", "a")
list = ['a', 'b', 'c', '123', '***']
file.writelines(list)
file.close()
程序运行后文件内容如下:

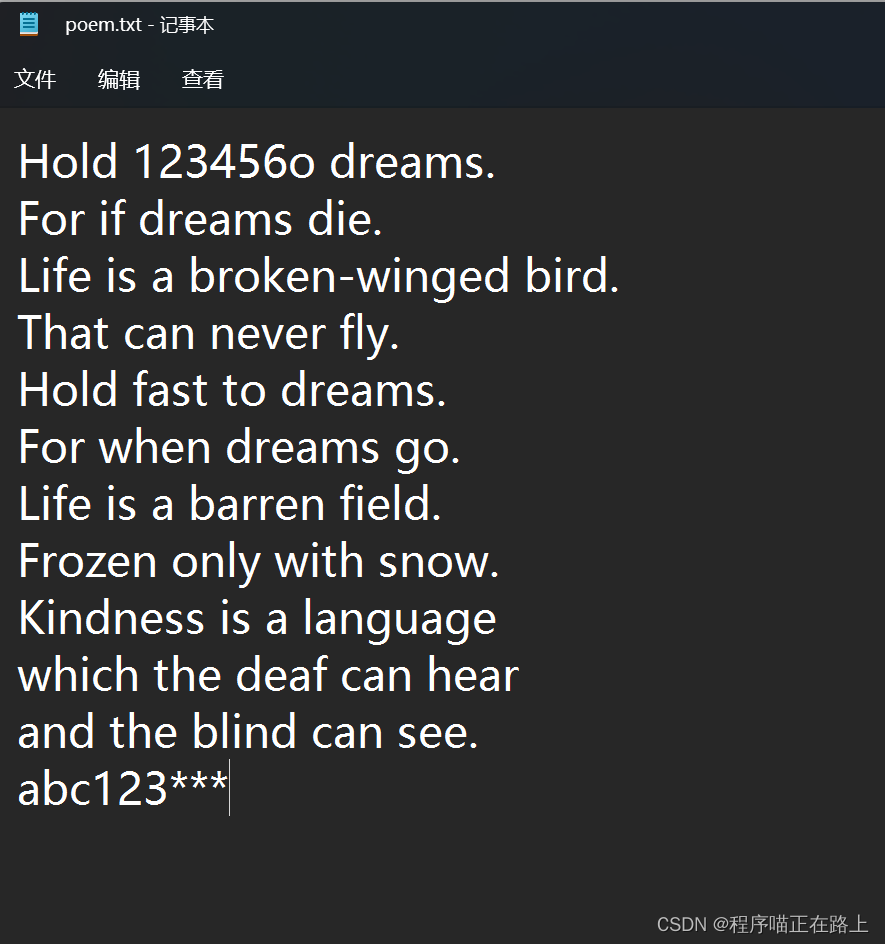
3、偏移后再写入内容,操作如下:
file = open("C:/Users/15269/Desktop/poem.txt", "w")file.seek(5)
word = '''123456'''
file.write(word)file.close()
程序运行后文件内容如下:
④ 案例:计算文件中关键字出现次数
接下来我们将使用 Python 来读取一个文件,统计某个特定字符串出现的次数并将其保存在某个文件中。本次我们使用 collections 模块,若是程序报出没有找到该模块的错误,请使用 pip 自行安装。
collections 模块是在 Python 内置数据类型之上,提供了多个有用的集合类模块。由于要统计特定字符串的出现次数,我们选用模块中的 Counter。
具体实现程序如下:
import collectionsfile = open('C:/Users/15269/Desktop/hamlet.txt')
str = file.read().split(' ')
n = collections.Counter(str)
print(n['the'])s = zip(n.values(), n.keys())output = open('C:/Users/15269/Desktop/hamletTest.txt', 'w')
for item in sorted(s, reverse=True):output.write("{0} {1}\n".format(item[1], item[0]))
程序输出在控制台的内容为:

程序写入到文件中的内容为:
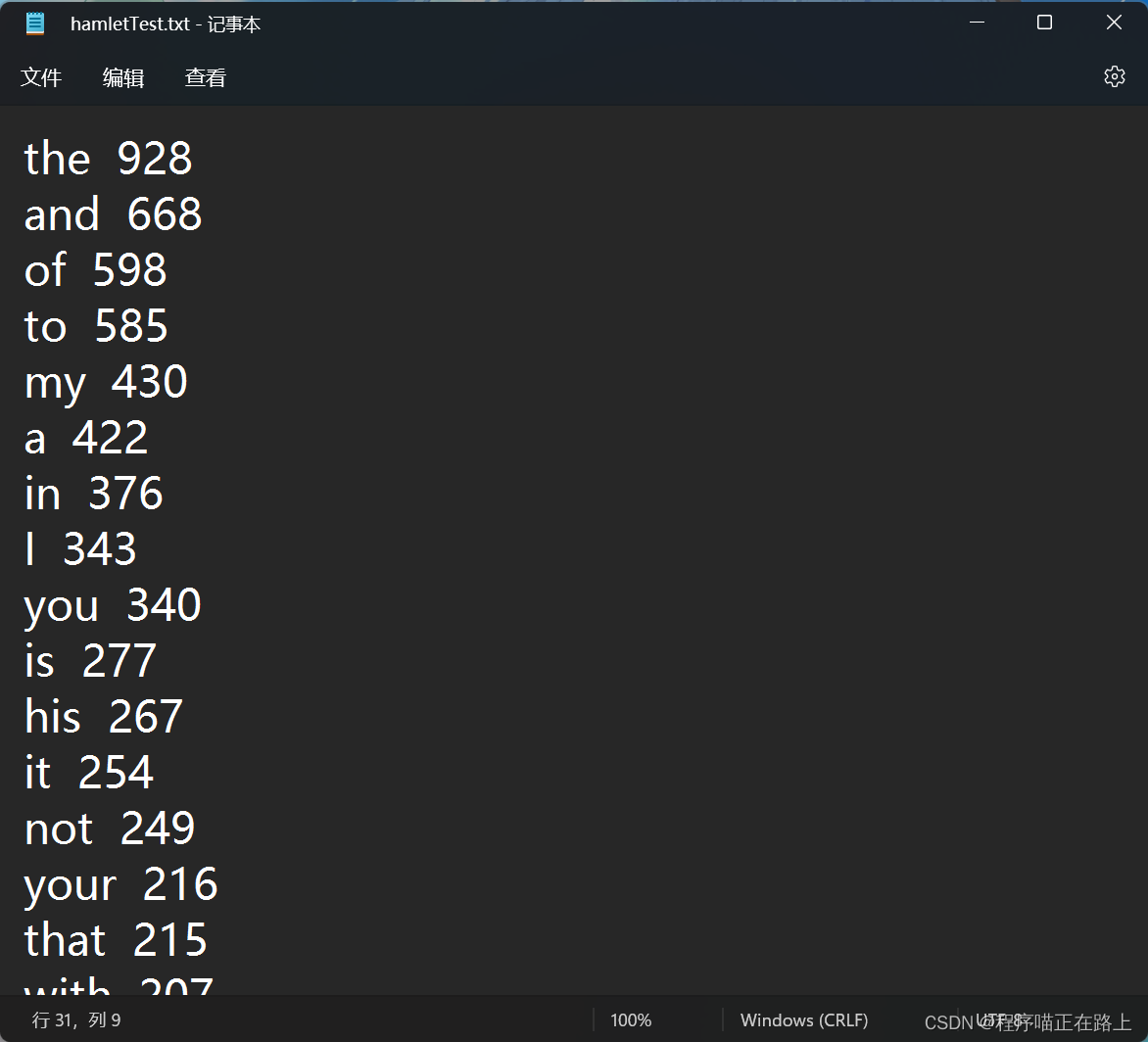
注意:这里只是给出了部分数据
这个程序充分体现了 Python 的开发速度快、代码量少的特点,由于 Counter 的使用,我们只需要提供数据。程序的第 4 行 str = file.read().split(’ ') 将其分解介绍,file.read() 是将文件中内容以一个字符串读出,此时语句相当于 string.split(’ '),而对于 split(’ ') 它是作用在一个字符串上的用于将字符串按指定规则(即它的参数,本次程序中指定为空格)分割,并将分割后内容以一个列表返回。
接下来这条语句 collections.Counter(str) 会返回一个字典,我们使用变量 n 接收。其中键为 str 中的内容,值为每项出现的次数,其中部分具体内容为 {‘the’: 928, ‘and’: 668, ‘of’: 598, ‘to’: 585, ‘my’: 430, ‘a’: 422, ‘in’: 376, ‘I’: 343},关键字及其出现的次数已经统计完成,有没有感受到 Python 的强大!得到字典 n 之后,我们使用 n[‘the’] 取出文中 ‘the’ 出现的次数。
完成这些处理之后我们将字典 n 中的键和键值单独抽出,使用 zip(n.values(), n.keys()) 将这些数据压缩成列表变量 s。
完成数据采集后开始为数据写入文件做准备。在打开文件后,我们使用 sorted(s, reverse=True),以数据中的 n.values() 值为标准对数据进行一个倒序的排列操作,最后使用 “字符加空格再加字符出现的次数” 这种格式将数据写入文件。到这里程序已经结束了。
你可能会有疑问,明明只要将数据写入文件就好了,为什么要先排序,再按照固定格式写入文件?
其实这样处理会为后续操作带来极大的便利。我们先不讨论这个问题,但是在这里要说的是任何程序都是有它的意义的。
⑤ 浅谈Python处理大数据文件
虽然相比于 C++ 等编程语言,使用 Python 处理大数据文件效率不高,但是由于 Python 开发速度快、代码量少、易于维护、成本低,并且有些细节问题使用 Python 处理极为方便。因此,在很多情况下会选用 Python 来处理大数据文件。这里介绍一下使用 Python 处理的两种方法:
(1) 将文件切分为多个小段,同时处理多段,处理完成后将处理结果合并。
(2) 使用 Python 自带的迭代器分行处理文件。
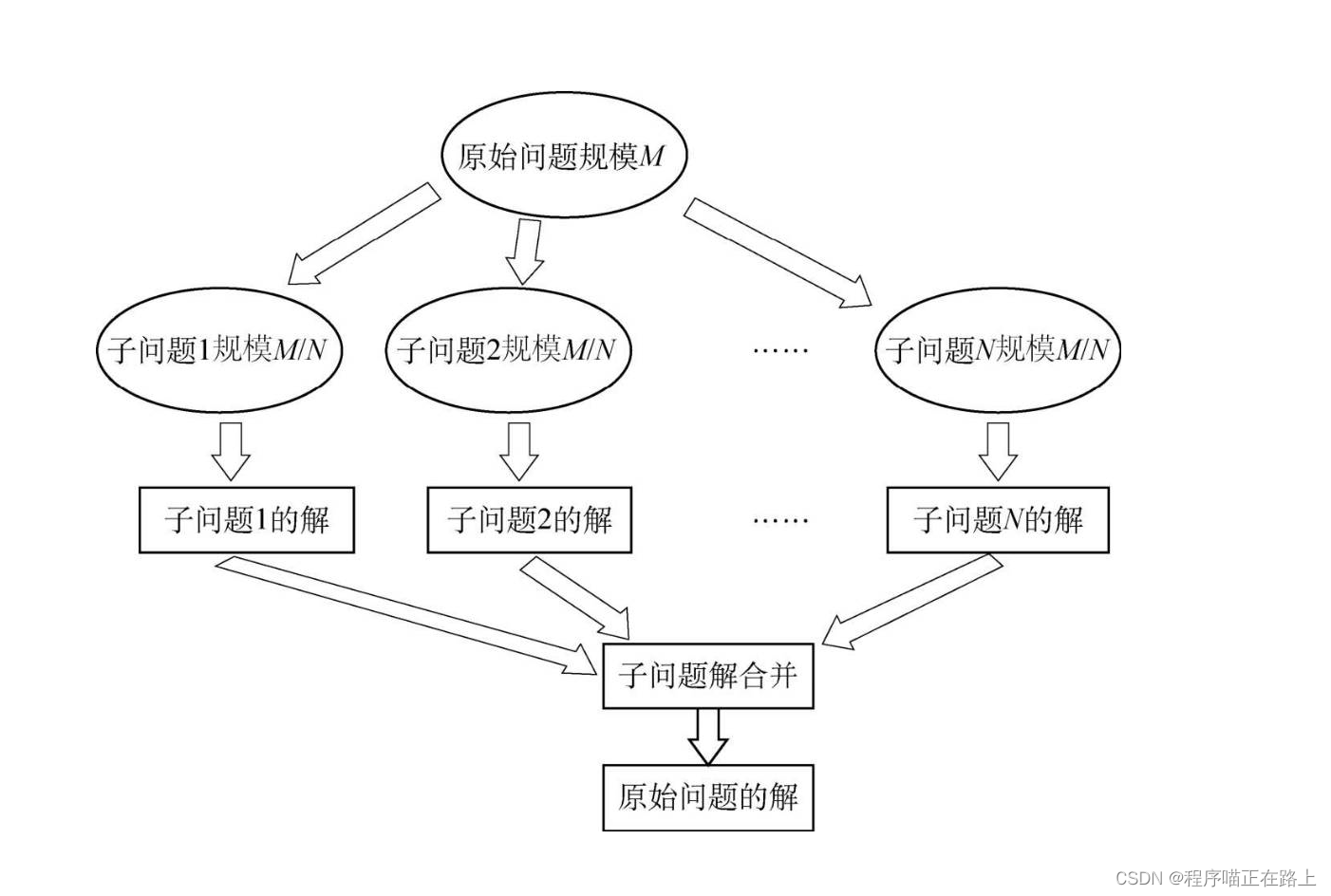
由于这个问题难度较大,这里我们只列出处理思想,不给出具体的程序案例。其实上述两种方法涉及的是一种名为分治法的经典算法,算法的流程图解如下图所示。通过这种处理可以充分利用现有的计算资源,但是同时带来的是对于问题的分解管理。具体来说,分治法就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单地直接求解。最后,原问题的解就变成子问题解的合并。算法思想比较简单,但是真正处理时会有很多细节需要注意。
🧸这次的分享就到这里啦,继续加油哦^^
🍭有出错的地方欢迎在评论区指出来,共同进步,谢谢啦
这篇关于[Python] 文件操作,你学废了吗的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



