本文主要是介绍WangDeLiangReview2018 - (5.3)去混响去噪,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【WangDeLiangOverview2018】
Supervised Speech Separation Based on Deep Learning: An Overview,DeLiang Wang / Jitong Chen @ Ohio,IEEE/ACM Trans. ASLP2018
【目录】
1. 引入
2. 学习机器(learning machines)
3. 训练目标(training target)
4. 特征
5. 单声道分离
5.1 语音增强(speech separation)
5.2 语音增强的泛化
5.3 语音去混响 & 去噪(speech dereverberation & denoising)
5.4 说话人分离(speaker separation)
6. 多声道分离(阵列分离)
7. 更多内容
【正文】
在真实环境中,语音通常被表面反射的混响(reverberation)所破坏。房间混响相当于直接信号和RIR(Room Impulse Response)的卷积,它会在时间和频率上扭曲语音信号。混响是语音处理中一个公认的挑战,特别是当它与背景噪声相结合时。因此,长期以来人们一直在积极研究去混响(dereverberation)[5][191][131][61]。
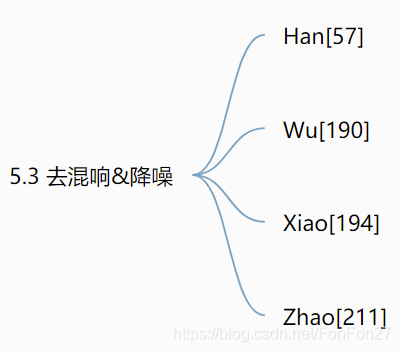
Han等人[57]提出了第一种基于DNN的语音去噪方法。这种方法在耳蜗图(cochleagram)上使用谱映射(spectral mapping)。换句话说,DNN被训练成从混响语音帧窗口映射到无混响语音帧,如图10所示。训练后的DNN能很好地重建无回声语音的耳蜗图。在他们后来的工作[58]中,他们在谱图上应用了谱映射,并扩展了方法来执行去混响和去噪。
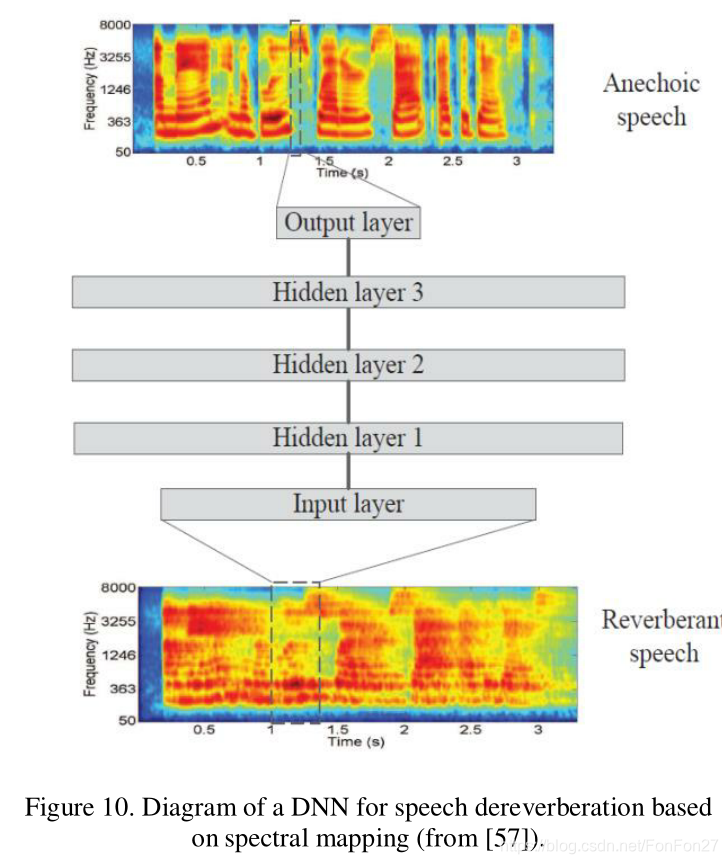
Wu等人最近提出了一种更复杂的系统[190],他们观察到,当帧长和移位根据混响时间(T60)的不同选择时,去混响性能会得到改善。在此基础上,他们的系统包括T60作为特征提取和DNN训练的控制参数。在去混响阶段,估计T60,选择合适的帧长和偏移量进行特征提取。这种所谓的混响时间感知模型如图11所示。他们的比较表明在[58]的DNN的去噪性能上有改进。
为了改进混响语音和噪声语音对消声语音的估计,Xiao等人[194]提出了一种训练的DNN来同时预测静态(static)、增量(delta)和加速度(acceleration)特征。静态特征为干净语音的对数量级,增量和加速度特征由静态特征派生。认为能较好地预测静态特征的DNN也能较好地预测增量和加速度特征。在DNN结构中加入动态特征有助于改进静态特征的估计,以实现减响。
Zhao等人[211]观察到,谱映射(spectral mapping)比T-F掩蔽更有效的去混响,尽管T-F掩蔽去噪效果更好。因此,他们构建了一个两阶段的DNN,其中第一阶段进行比率掩蔽(ratio masking)去噪,第二阶段进行谱映射去混响。此外,为了减轻利用混响噪声语音相位对增强语音波形信号重新合成的不利影响,本研究对[182]中的时域信号重构技术进行了扩展。这里的训练目标是在时域中定义的,但是训练过程中使用干净阶段,而[182]中使用了噪声阶段。这两个阶段先单独训练,然后联合训练。[211]的结果表明,无论是映射还是掩蔽,两阶段DNN模型都明显优于单阶段模型
这篇关于WangDeLiangReview2018 - (5.3)去混响去噪的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[蓝牙核心规范5.3][Vol 2 BR/EDR控制器][Part B 基带规范]2 物理通道](https://i-blog.csdnimg.cn/blog_migrate/eb5a65ce59e9afc6e4ded86fb37f8407.png)

