本文主要是介绍12月19号-12月26号:一些css、游览器拦截跳转窗口、HTML文件解析、postMessage,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、CSS
1.基础选择器:
- 标签选择器:选的啥一类标签,无论嵌套有多深
- 类选择器:类名开头不能是数字和中划线,跨域由数字、字幕、下划线、中划线组成,类名可以重复,多个空格空格隔开
- d选择器:不可重复,一个页签只能写一个id属性值,一个id选择器只能选择一个标签
- 通配符选择器:给所有标签设置样式
2.字体:
font-family:左到右查找,电脑没有这个字体久显示下一个字体
3.line-height:行高减除文字高度,均分分上下间距,
常见场景
- 设置单行文本垂直居中,多行文本不能设置垂直居中
- 取消上下间距
4.选择器: - 后代选择器p person,子代和子子子孙孙都选中
- 子代选择器:p>child,只选中子代
- 并集选择器:p,.child,…,多种复合选择器选中多个div
- 交集选择器:选择器之间紧挨着,没有东西分割,如果有标签选择器,标签选择器必须写着前面
- 标签属性选择器:a[title]
- 相邻兄弟选择器:h1~p
5.emmet语法,自动生成节点和样式 - .red生成,
- span.text,
- ul>span,
- ul>li*3,生成三个li,一个ul
6.背景平铺:可以作为背景,铺一个repeat-x
- background-position:原点着左上角
- img标签会有默认宽高,请问移动端会自适应嘛
- 背景图片,不能撑开标签
7.1块级元素:display:block
- 宽度是父元素的宽度,高度上内容的高度
- 独占一行3.可以设置宽高
7.2行内元素:a\span,display:inline - 宽高是内容的宽高、2.一行可以放多个、3.不可设置宽高
7.3行内块元素:display:inlin-block - 一行可以放多个、3.可设置宽高
input、textarea
p标签不能放div、p等块级元素
a标签不能嵌套a标签
8.css三大特性:继承、层叠、优先级
你不知道的position?
继承:color,font,text-indent,text-align、line-height
优先级从低到高:继承、通配符选择器、标签选择器、属性选择器===类选择器、id选择器、行内样式、!important
!important不能提升继承优先级
对于复合选择器,权重叠加计算:
权重一样、比较重叠性,(谁写着下面)
注意:!important权重最高,除了继承
9.标准流、浮动、定位元素之间的层级关系?
float层级比标准的层级高,position层级比浮动的层级高,
不同定位之间的层级关系:
fixed、absolute、relative层级一样,谁的html写着最下面层级更高,会覆盖上面的元素
更改定位的层级:
z-index
10.基线:
游览器文字类型元素排版中存在用于对齐的基线
vertical-align:行内文本对齐方式,top,bottom,baseline
边框合并属性:border-collapse:collapse;
11.background-size:
百分比当前和子自身的宽高百分比、
contain等比例缩放,不会超出盒子的最大、
cover将背景图片等比例缩放,直到刚好填满整个盒子没有空白
background:color image repeat position/size
12.text-shadow:可以设置多个阴影效果
网页html结构
!doctype html文档类型声明
翻译弹框问题,html lang=‘en’
编码方式:meta charset=utf-8,保存和打开的字符编码需要统一。
13.seo三大标签:title、description、keywords
提升seo常见方法:
1.竞价排名
2.将网页制作成html后缀
3.标签语义化
标签语义化标签:header、nav、footer、aside、section、article
设置iconfont
ionfont:<link rel=‘icon shortcut’ href=‘路径’ type=‘image/x-icon’ >
二、游览器拦截跳转窗口
handleJumpInterceptor('openCourse/third/getTempCode', 'post', params,function(res){res = JSON.parse(res);if(res) {_this.appointmentReminder(item)let jumpUrl = `${item.liveUrl}&tempCode=${res.result}&nickName=${_this.userData.nickName}#/home`window.open(jumpUrl)}},)function handleJumpInterceptor(url,methods, data,callBack,header,ext) {url = `${window.location.origin}/` + url // 兼容ie浏览器 使用原生http请求 同步获取跳转链接let xhr = null;if (window.XMLHttpRequest) {xhr = new XMLHttpRequest();} else {xhr = new ActiveXObject('Microsoft.XMLHTTP')}xhr.open(methods, url, false);// setRequestHeader必须在open后if (methods.toLowerCase() == 'post') {xhr.setRequestHeader("Content-Type", "application/json;charset=utf-8");}// 添加更多的请求头if (header) {for (const key in header) {xhr.setRequestHeader(key, header[key]);}}// 携带请求参数xhr.send(data);if (xhr.status === 200) {xhr.responseText && callBack(xhr.responseText)}
}
三、HTML文件解析
浏览器的渲染机制
DOM 和 CSSOM 都是以 Bytes → characters → tokens → nodes → object model. 这样的方式生成最终的数据。如下图所示:
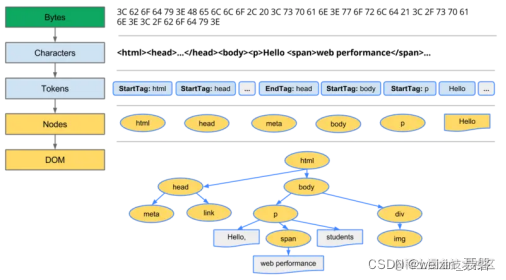
DOM 树的构建过程是一个深度遍历过程:当前节点的所有子节点都构建好后才会去构建当前节点的下一个兄弟节点。
Render Tree[3]:DOM 和 CSSOM 合并后生成 Render Tree,如下图:
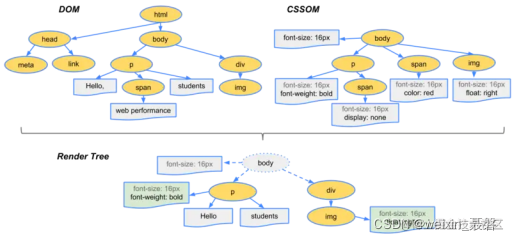
display:none 的节点不会被加入 Render Tree,而 visibility: hidden 则会,所以,如果某个节点最开始是不显示的,设为 display:none 是更优的。
浏览器的渲染过程
1.Create/Update DOM And request css/image/js:浏览器请求到HTML代码后,在生成DOM的最开始阶段(应该是 Bytes → characters 后),并行发起css、图片、js的请求,无论他们是否在HEAD里。
注意:发起 js 文件的下载 request 并不需要 DOM 处理到那个 script 节点,比如:简单的正则匹配就能做到这一点,虽然实际上并不一定是通过正则:)。这是很多人在理解渲染机制的时候存在的误区。
2.Create/Update Render CSSOM:CSS文件下载完成,开始构建CSSOM
3.Create/Update Render Tree:所有CSS文件下载完成,CSSOM构建结束后,和 DOM 一起生成 Render Tree。
4.Layout:有了Render Tree,浏览器已经能知道网页中有哪些节点、各个节点的CSS定义以及他们的从属关系。下一步操作称之为Layout,顾名思义就是计算出每个节点在屏幕中的位置。
Painting:Layout后,浏览器已经知道了哪些节点要显示(which nodes are visible)、每个节点的CSS属性是什么(their computed styles)、每个节点在屏幕中的位置是哪里(geometry)。就进入了最后一步:Painting,按照算出来的规则,通过显卡,把内容画到屏幕上。
以上五个步骤前3个步骤之所有使用 “Create/Update” 是因为DOM、CSSOM、Render Tree都可能在第一次Painting后又被更新多次,比如JS修改了DOM或者CSS属性。
Layout 和 Painting 也会被重复执行,除了DOM、CSSOM更新的原因外,图片下载完成后也需要调用Layout 和 Painting来更新网页。
注意:js的下载和执行会阻塞Dom树的构建(严谨地说是中断了Dom树的更新),所以script标签放在首屏范围内的HTML代码段里会截断首屏的内容。

你会发现,这3个脚本的加载时机竟然都是一样的,都是在HTML获取到之后,马上就开始加载。这里其实涉及到浏览器的一个优化,它会预先找到HTML中的所有script标签,并直接开始加载,并不是在解析到该标签时才开始加载。这样算是浏览器一种优化,等HTML解析到对应标签后,JS已经加载好了,直接执行即可,这样可以节省大量的时间,提升用户体验。
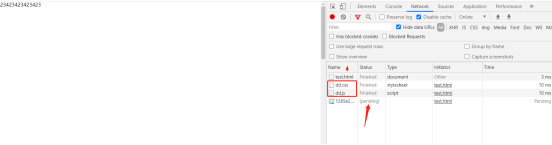

结论:
1.Script的位置会阻塞dom的渲染,
2.HTML加载后,并行请求css,js文件
3.js文件的执行时刻:在没有defer和async情况下,是遇到script标签就执行,所以可能出现dom渲染阻塞问题
4.css放head里面,可以先解析css文件后解析dom,如果css放body后面就会造成页面结构一闪的情况,先出现dom结构。
四、postMessage
一个不错的包:npm i postmate --save # Install via NPM
https://github.com/dollarshaveclub/postmate
postMessage是宏任务,如下:
async sendPost() { // 获取id为otherPage的iframe窗口对象 var iframeWin = document.getElementById("otherPage").contentWindow; console.log(11111111); // 向该窗口发送消息 iframeWin.postMessage(document.getElementById("message").value, 'http://linxiaohui.hqjy.com:3000/user_center'); new Promise((resolve,reject)=>{resolve(1)}).then(() =>{console.log(333333);}) console.log(2222222); },
父页面
Html:
<textarea id="message"></textarea> <input type="button" value="发送" @click="sendPost"> <iframesrc="http://linxiaohui.hqjy.com:3000/user_center" id="otherPage"style="display:none"></iframe>
发送消息:
sendPost() { // 获取id为otherPage的iframe窗口对象 var iframeWin = document.getElementById("otherPage").contentWindow; // 向该窗口发送消息 iframeWin.postMessage(document.getElementById("message").value, 'http://linxiaohui.hqjy.com:3000/user_center'); },
接受消息:
window.addEventListener("message", function( event ) {// 监听父窗口发送过来的数据向服务器发送post请求var data = event.data;console.log('用户中心',data);window.parent.postMessage('hello', "*"); }, false);
子页面:
监听
window.addEventListener("message", function( event ) {// 监听父窗口发送过来的数据向服务器发送post请求var data = event.data;console.log('用户中心',data);window.parent.postMessage('hello', "*"); }, false);
五、一些琐屑日常:
5.1 iframe有什么优缺点
优点:
frame能够原封不动地把嵌入的网页展现出来。
多个地方用到,有利于网页的复用和维护
缺点:
加重http请求负担,
onload事件延迟,
不利seo
5.2 模块化和组件化
模板化是在文件层面上,对代码和资源的拆分。
具体:JS模块化方案很多有AMD/CommonJS/UMD/ES6 Module等,CSS模块化开发大多是在less、sass、stylus等预处理器
组件化是在设计层面上,对于UI的拆分
具体:组件化将页面视为一个容器,页面上各个独立部分例如:头部、导航、焦点图、侧边栏、底部等视为独立组件,不同的页面根据内容的需要,去盛放相关组件即可组成完整的页面。
5.3 1px ≠1像素
比如 IPhone X 的分辨率是 1125×2436,代表屏幕横向和纵向分别有 1125 和 2436 个像素点,这里的像素是设备像素(Device Pixels)。DPR 可以在浏览器中通过 JavaScript 代码获取,
5.4 为什么要用setTimeout来模拟setInterval的行为?
每个setTimeout产生的任务会直接push到任务队列中;而setInterval在每次把任务push到任务队列前,都要进行一下判断(看上次的任务是否仍在队列中)。因而我们一般用setTimeout模拟setInterval,来规避掉上面的缺点。
5.5.垃圾回收
1.引用计数:
如果没有引用指向该对象(零引用),对象将被垃圾回收机制回收。
2.标记清除:
圾回收器将定期从根开始
5.6.axios发送两次请求
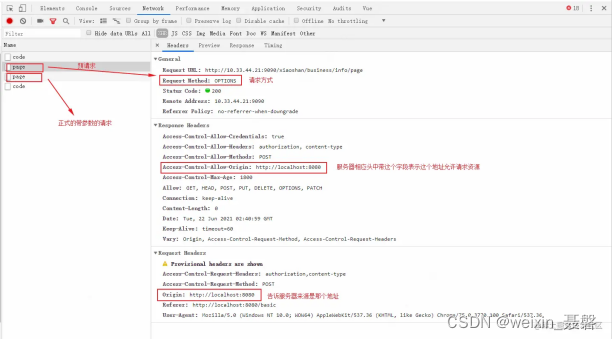
第一次option预检
浏览器通过Origin字段先询问服务器当前网页所在的域名是否在服务器的许可名单内,以及可以使用哪些Http动词和头信息字段
只有通过了预检请求浏览器才会发出正式的携带相关参数的XMLHttpRequest请求,否则就报错
CORS需要浏览器和服务器同时支持
如果服务器允许跨域,则需要在相应头中携带如下信息:
-
Access-Control-Allow-Origin:http: //foo.example(或是 * )
-
Access-Control-Allow-Credentials:true
-
Content-type:text/html; charset=utf-8
Access-Control-Allow-Origin:允许哪个域名进行跨域,是一个具体的域名或者 * ( * 代表任何域名)
Access-Control-Allow-Credentials:是否允许携带cookie,默认情况下CORS不会携带cookie,除非这个值是true
想要操作cookie需要满足3个条件:
服务器响应头中需要携带Access-Control-Allow-Credentials并且值为true
在浏览器发起ajax请求时需要在请求头上指定withCredentials:true
响应头中的Access-Control-Allow-Origin一定不能为*,必须是指定的地址
而对于POST,发送两次tcp包,浏览器先发送header,服务器响应100continue,浏览器再发送data,服务器响应200ok(返回数据)
Head 请求有以下特点:
只请求资源的首部, 检查超链接的有效性 检查网页是否被修改
5.7深拷贝:
function deepClone(obj) {
let newObj = obj instanceof Array ? [] : {};
for (let item in obj) {
let temple = typeof obj[item] == ‘object’ ? deepClone(obj[item]) : obj[item];
newObj[item] = temple;
} return newObj;
}
5.8JavaScript的数据类型
数据类型:共有8种
基本类型的变量是存放在栈区的
引用类型的值是同时保存在栈内存和堆内存中的对象
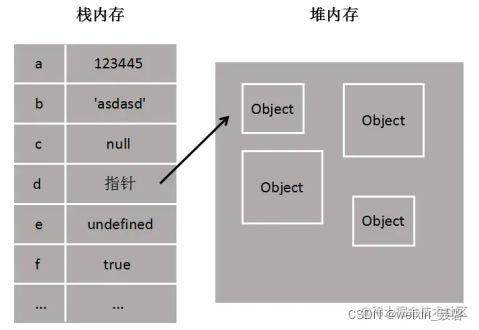
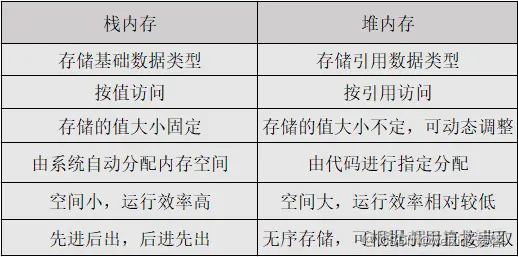
对于简单类型,const保证的是栈内存中所保存的数据不得改动。
对于复合类型,const保证的是栈内存中所保存的指针不得改动。
这篇关于12月19号-12月26号:一些css、游览器拦截跳转窗口、HTML文件解析、postMessage的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







