本文主要是介绍mumps求解器使用心得,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
以mumps中example.c例子为标准,在实践尝试了几乎所有参数设置后,总结了对于普通小白有用的几个重要参数:
1.id.par = 1 // 可选择0,1;该参数在使用mpi并行的时候会考虑,
=1:解释为主进程(rank=0)参与因子分解和求解阶段的并行步骤;
=0:解释为主进程(rank=0)不参与因子分解和求解阶段的并行步骤,因此在等于0的时候务必保证mumps按照的是并行版本以及当前程序的进程数目大于1;这个参数在集群的大规模计算中非常的有用,能保证主进程与其他进程的内存使用相对平衡。
这里测试了mpi=4个进程下两种参数的结果:
par=1:

par=0:

直观的看出par=0的情况下,四个进程的内存使用量相对平衡。
2.id.sym=0 //可选择0:矩阵非对称;1 矩阵对称正定;2 矩阵一般对称与对称复数
example.c中使用的是矩阵非对称例子,因此如果是对称矩阵最好是改成1or2,测试显示大规模矩阵求解的时候使用非对称矩阵接口的内存消耗几乎是使用对称矩阵接口的2倍!
修改方式简单:sym=1or2;输入的稀疏矩阵为上三角或者下三角矩阵;例如:
DMUMPS_STRUC_C id;MUMPS_INT n = 2;MUMPS_INT8 nnz = 3;MUMPS_INT irn[] = {1,1,2};MUMPS_INT jcn[] = {1,2,2};double a[3];double rhs[2];/* Define A and rhs *//*|1 1| |1|A=|1 2| rhs=|4| */rhs[0]=1.0;rhs[1]=4.0;a[0]=1.0;a[1] = 1.0;a[2]=2.0;求解结果:
![]()
3.ICNTL(14) = 20 //默认20表示动态内存增加以20%的增量增加;
这个参数也可以设置大小,设置小一些能过多的分配避免不必要的内存分配;
4.mumps的信息输出,这个对于观察mumps的性能也是非常重要,设置也非常简单:
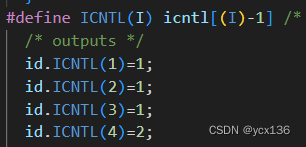
当前文件夹下面会生成fort.1的日志文件;
其他的参数专业性质很强,并且在测试中对于改善mumps的性能并不是太明显(因为本身mumps很多默认参数都具有自动选择最优解决方案的功能),甚至有可能某些参数的使用可能会导致错误。
按照Chat-GPT的回答:
MUMPS求解器的参数设置可以通过调整以下几个方面来进行优化:
-
任务分解策略:MUMPS可以采用多种不同的任务分解策略,包括面向数据的任务划分、面向任务的任务划分和混合型的任务划分。这些策略会影响到并行计算效率和内存利用率,因此需要根据具体问题进行选择。
-
内存管理策略:MUMPS可以采用不同的内存管理策略,包括静态分配和动态分配。静态分配可以减少内存碎片,但是可能导致内存浪费;动态分配可以更灵活地利用内存,但是可能会增加内存碎片和内存管理开销。
-
稀疏性处理策略:MUMPS支持不同的稀疏性处理策略,包括对称性检测、自动重排序、填充度控制等。这些策略可以影响到系数矩阵的稀疏性和分解质量,从而影响到求解器的性能和内存使用量。
-
精度控制策略:MUMPS可以控制因式分解和求解过程中的精度要求,包括矩阵因式分解的阈值、数值稳定性检测的容限等。这些策略可以影响到计算精度和内存使用量。
综上所述,MUMPS求解器的参数设置需要根据具体问题进行选择和优化,以在保证计算精度的前提下,尽可能地减少内存使用量和计算时间。
mumps的说明书的确也是如此,一般情况下mumps默认的管理策略都能很好的自动选择最优方案进行分解与计算。
这篇关于mumps求解器使用心得的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







