本文主要是介绍Excel 5s内导入20w条简单数据(不使用多线程),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- Excel 5s内导入20w条数据
- 1. 生成20w条数据
- 1.1 使用Excel 宏生成20w条数据
- 1.2 生成成功
- 2. ExecutorType:批量操作执行器类型
- 2.1 ExecutorType.SIMPLE
- 2.2 ExecutorType.BATCH
- 2.3 ExecutorType.REUSE
- 3. 20w条数据直接插入数据库
- 3.1 使用ExecutorType.SIMPLE
- 3.2 使用ExecutorType.BATCH
- 3.3 ExecutorType.REUSE
- 3.半 拓展
- 4. 总结
- 5. 多线程版本
Excel 5s内导入20w条数据
1. 生成20w条数据
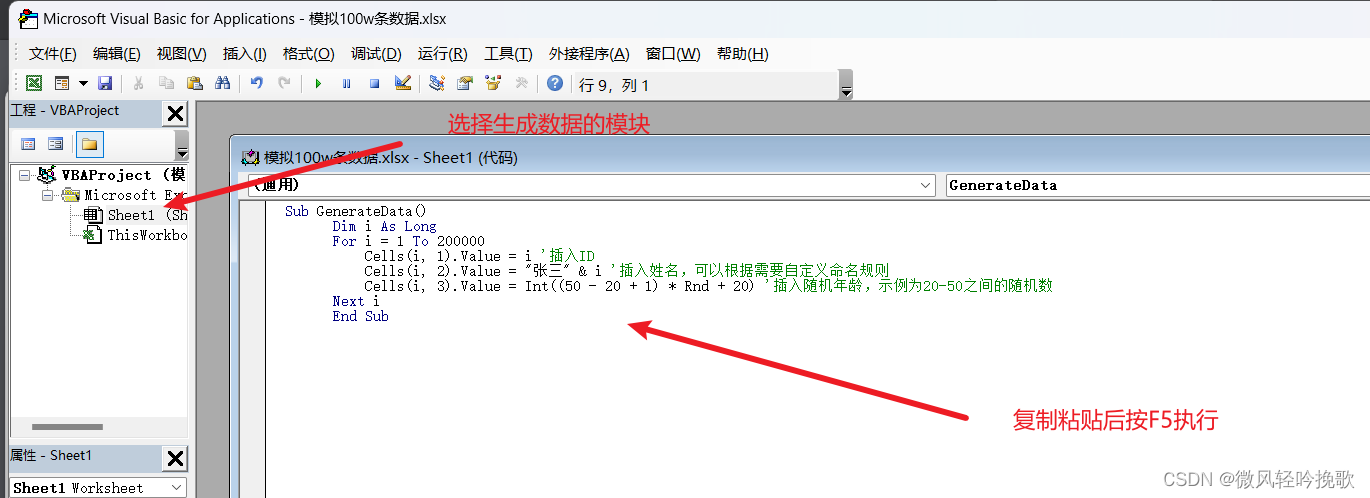
1.1 使用Excel 宏生成20w条数据
- 打开Excel,按下Alt+F11打开VBA编辑器。 在VBA编辑器中选择插入 -> 模块,然后将以下代码粘贴到模块中:
Sub GenerateData()Dim i As LongFor i = 1 To 200000Cells(i, 1).Value = i '插入IDCells(i, 2).Value = "张三" & i '插入姓名,可以根据需要自定义命名规则Cells(i, 3).Value = Int((50 - 20 + 1) * Rnd + 20) '插入随机年龄,示例为20-50之间的随机数Next i End Sub
- 按下F5执行宏,即可生成20万条数据。
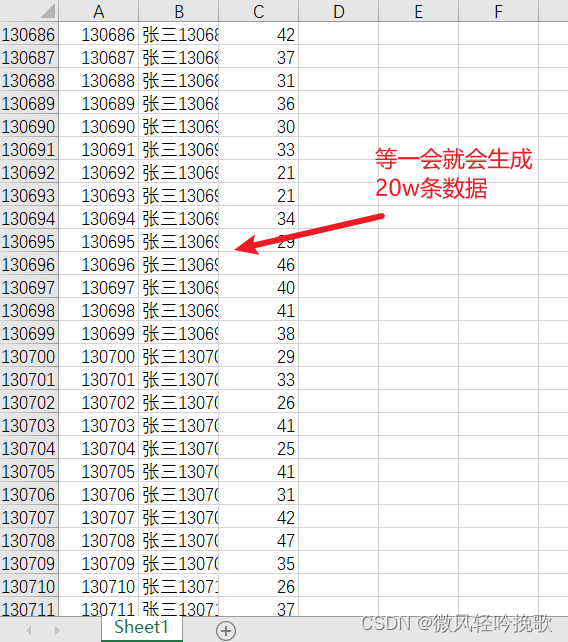
1.2 生成成功
因为数据量较大,所以需要稍微等上一小段时间
2. ExecutorType:批量操作执行器类型
在MyBatis中,ExecutorType是一种枚举类型,用于指定SQL语句执行的方式。其中,ExecutorType.BATCH和ExecutorType.SIMPLE是两种常见的执行方式。
2.1 ExecutorType.SIMPLE
ExecutorType.SIMPLE是MyBatis框架中的一种执行器类型,用于执行SQL语句并返回结果集。在这种执行器类型下,每个SQL语句的执行请求都将打开一个新的数据库连接,执行完毕后立即释放连接,适用于小型应用或轻负载的情况。
特点:
- ExecutorType.SIMPLE是默认的执行方式。
- 每次执行SQL语句时,都会打开一个新的PreparedStatement对象。
- 每条SQL语句都会立即被执行并提交到数据库。
- 每个SQL语句的执行请求都将打开一个新的数据库连接,执行完毕后立即释放连接
- 适用于常规的单个或少量SQL操作。
2.2 ExecutorType.BATCH
- ExecutorType.BATCH会将一批SQL语句集中在一起批量执行,减少了与数据库的交互次数,提高性能。
- 多条SQL语句会一起提交到数据库执行,可以提升执行效率。
- 可以通过sqlSessionFactory.openSession(ExecutorType.BATCH)方法手动触发批量执行。
- 适用于需要执行大量SQL操作的场景,如批量插入、更新或删除多条记录。
2.3 ExecutorType.REUSE
- 当多次调用相同的SQL语句时,会重用已编译的SQL语句和执行计划。
- 适用于单条SQL语句的重复执行,例如在一个循环中多次执行相同的SQL语句。
- 每次执行都会创建一个新的Statement对象,但会重用已编译的SQL语句和执行计划,以提高执行效率。
3. 20w条数据直接插入数据库
dao 层 的代码
@Insert("insert into excel(id,name,age) values (#{id},#{name},#{age})")
void insert(Man man);
3.1 使用ExecutorType.SIMPLE
public void insert1() {//用于记录读取数据所需要的时间long start0 = System.currentTimeMillis();//ExcelUtil hutool工具类用来读取Excel文件ExcelReader reader = ExcelUtil.getReader(FileUtil.file("C:\\Users\\26896\\Desktop\\test.xlsx"), "sheet1");//将读取到的 reader 转化为 List<Man>集合List<Man> mans = reader.readAll(Man.class);//读取数据的结束时间同时也是写入数据库的开始时间long start = System.currentTimeMillis();//sqlSessionFactory是通过ioc容器注入的 设置其SqlSession的执行器格式ExecutorType.SIMPLE(默认)SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.SIMPLE);ExcelDao mapper = sqlSession.getMapper(ExcelDao.class);//循环将List<Man>中的数据插入数据库for (Man man : mans) {mapper.insert(man);}sqlSession.commit();long end = System.currentTimeMillis();sqlSession.close();System.out.println("最终的结果为:" + (start - start0) );System.out.println("最终的结果为:" + (end - start) );}
执行结果

3.2 使用ExecutorType.BATCH
rewriteBatchedStatements=true
当该参数设置为true时,MySQL会对批量操作进行重写,将多个SQL语句合并成一条批量执行的SQL语句。这样可以减少网络传输和数据库连接的开销,从而提高批量操作的效率。
public String insert2() {long start0 = System.currentTimeMillis();ExcelReader reader = ExcelUtil.getReader(FileUtil.file("C:\\Users\\26896\\Desktop\\test.xlsx"), "sheet1");List<Man> mans = reader.readAll(Man.class);long start = System.currentTimeMillis();SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);ExcelDao mapper = sqlSession.getMapper(ExcelDao.class);for (Man man : mans) {mapper.insert(man);}sqlSession.commit();long end = System.currentTimeMillis();sqlSession.close();System.out.println("读取最终的结果为:" + (start - start0) );System.out.println("插入数据库最终的结果为:" + (end - start) );return null;}
执行结果

3.3 ExecutorType.REUSE
ExecutorType.REUSE 本身不做验证,这里主要比较其它两个区别,但是都到这里啦就写上
public void insert3() {long start0 = System.currentTimeMillis();ExcelReader reader = ExcelUtil.getReader(FileUtil.file("C:\\Users\\26896\\Desktop\\test.xlsx"), "sheet1");List<Man> mans = reader.readAll(Man.class);long start = System.currentTimeMillis();SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.REUSE);ExcelDao mapper = sqlSession.getMapper(ExcelDao.class);for (Man man : mans) {mapper.insert(man);}sqlSession.commit();long end = System.currentTimeMillis();sqlSession.close();System.out.println("读取最终的结果为:" + (start - start0) );System.out.println("插入数据库最终的结果为:" + (end - start) );}

3.半 拓展
吃瓜观众: 歌歌 呀,既然ExecutorType.SIMPLE适合执行一个语句,那就用MyBatis 的,将20w条数据拼接为1条。这样是不是就快了
歌歌:非常好
xml代码
<insert id="add">insert into excel(id,name,age) values<foreach collection="list" item="man" separator=",">(#{man.id},#{man.name},#{man.age})</foreach></insert>
service代码
@AutowiredExcelDao excelDao;public String add2() {long start0 = System.currentTimeMillis();ExcelReader reader = ExcelUtil.getReader(FileUtil.file("C:\\Users\\26896\\Desktop\\test.xlsx"), "sheet1");List<Man> mans = reader.readAll(Man.class);long start = System.currentTimeMillis();excelDao.add(mans);long end = System.currentTimeMillis();System.out.println("最终的结果为:" + (start - start0) );System.out.println("最终的结果为:" + (end - start) );return null;}
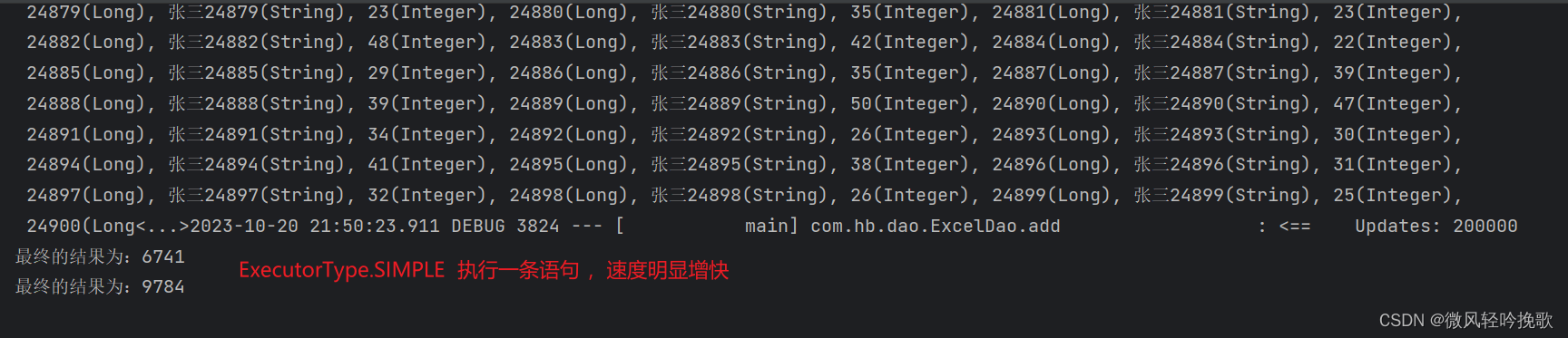
4. 总结
在需要将大量数据通过java程序放入数据库时, 可以通过sqlSessionFactory.openSession(ExecutorType.BATCH)方法手动触发批量执行。并且可以通过在链接数据库的时候加上rewriteBatchedStatements=true来开始数据库的批处理操作
5. 多线程版本
点个关注,不迷路
个人主页 个人主页
这篇关于Excel 5s内导入20w条简单数据(不使用多线程)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



