本文主要是介绍论文阅读| Adaptive Consistency Prior based Deep Network for Image Denoising,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
0 摘要
1. Introduction
2. Proposed Method
2.1. Adaptive Consistency Prior for Denoising
2.2. Deep Unfolding Denoising Network
2.3. Further Analyze and Optimize DeamNet
3. Experimental Results
3.2. Dataset Preparation and Testing
3.4. Ablation Study (see Table 3)
3.5. Denoising on Synthetic Noisy Images
3.6. Denoising on Real Noisy Images
补充材料:
4. Conclusion
0 摘要
提出一种新的基于模型的去噪方法来指导我们去噪网络的设计。
- 首先,在传统的一致性先验中引入非线性滤波算子、可靠性矩阵和高维特征变换函数,我们提出了一种新的自适应一致性先验(ACP)
- 其次,将ACP项引入最大后验框架,提出了一种基于模型的去噪方法。该方法进一步被用于网络设计,产生一个新的端到端可训练和可解释的深度去噪网络,称为DeamNet.
展开过程导致了一个很有前途的模块,称为双元素级注意机制(DEAM)模块。
1. Introduction
图像去噪方法:Filtering-Based Methods / Model-Based Methods / Learning-Based Methods
- 1)提出了一种新的图像先验(即自适应一致性先验(ACP)),通过引入非线性滤波算子、可靠性矩阵和高维转换函数来改进传统的一致性先验然后,在MAP框架下利用ACP提出了一种基于模型的去噪方法.
- 2)利用基于模型的去噪方法的迭代优化步骤来指导网络设计,从而得到一个端到端可训练和可解释的去噪网络(DeamNet)。DeamNet将基于模型的方案的能力与深度学习相结合;
- 3)在此展开过程中,提出了一种基于ACP可靠性矩阵的双元智能注意机制(dual element-wise attention mechanism, DEAM)模块,该模块由ACP的可靠性矩阵导出。DEAM还支持跨层次/跨尺度的特征交互和在每个迭代阶段的元素级特征重新校准。
- 4)提出了一种带有DEAM模块的多尺度非线性运算(NLO)子网络,该子网络可以同时利用NLO子网络中的细尺度和粗尺度特征,实现更好的特征域(FD)非线性滤波。
2. Proposed Method
2.1. Adaptive Consistency Prior for Denoising
由于自然图像具有局部连续性和非局部自相似性,因此容易产生局部和非局部的强相关性。基于这些相关性,提出了一致性先验。
一致性先验的局限性及其解. 设x∈Rn为n个像素的图像,xi表示x中的第i个像素,Di表示x内xi相关像素的索引向量,wij为与xi和xj相关的归一化权重。一致性先验JCP(x): Rn→R1可以写成
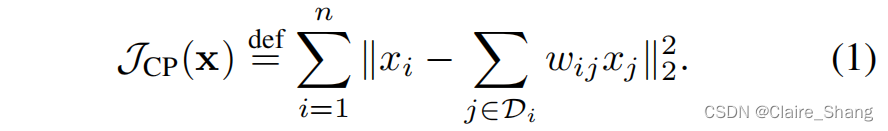
为了便于分析,方程(1)重写为:
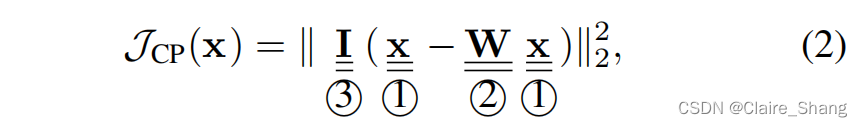
其中,I∈Rn×n是一个单位阵,W∈Rn×n是由wij -s组成的对角一致性矩阵。
我们可以这样理解一致性先验:像素域的图像x(标记为①)首先用线性一致性矩阵W(标记为②)进行过滤,然后将拟合偏差向量(x-Wx)的大小统一约束为I (标记为③)。因此,一致性先验的主要局限性及其解决方案为:
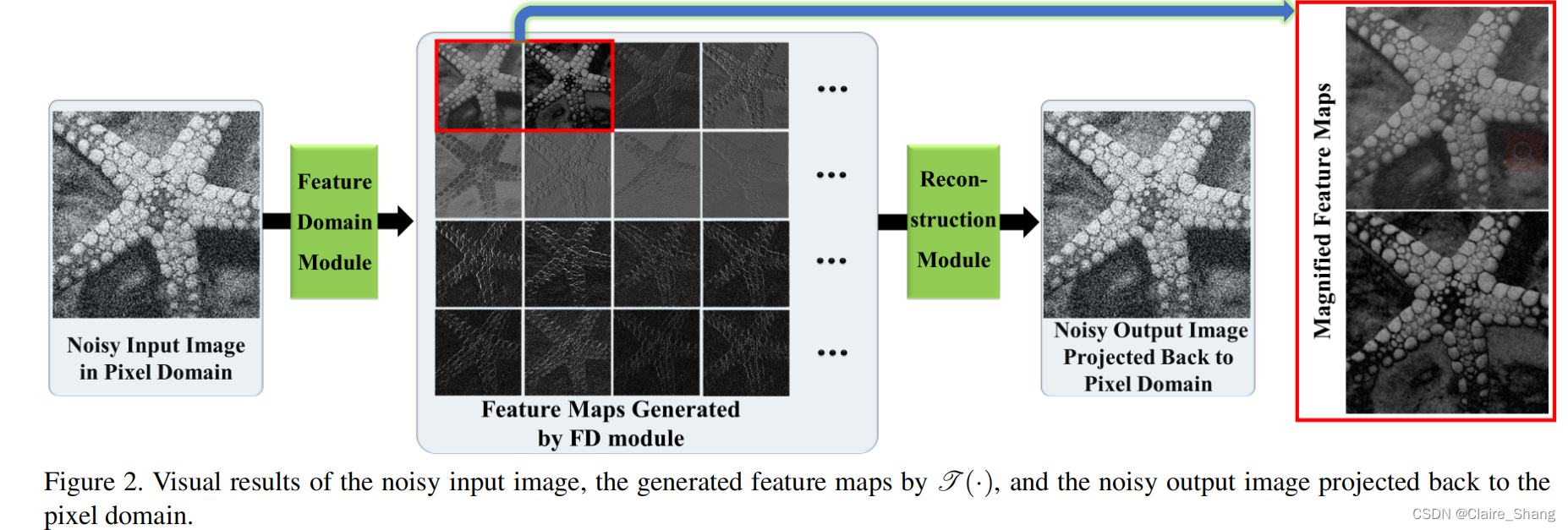
- 1)一致性先验在像素域内进行约束,而传统方法,如BM3D及其变体[10,11],在FD(特征域)中进行去噪可以更好地重建图像细节。此外,通过扩展空间维度,可以捕捉到更多的特征,以便更好地恢复细节。因此,可以使用高维变换函数T(·)对x进行变换;
- 2) W对每个像素进行线性运算,可能会使图像细节过平滑,导致性能较差。为了更好地保持边缘和图像细节,我们希望引入自适应的非线性滤波算子K(·)来代替W。
- 3) 在一致性先验中对拟合偏差进行一致的惩罚。但是,根据对应像素的可靠性自适应地对每个拟合偏差进行惩罚是有用的。这促使使用可靠性矩阵Λ来自适应加权 (x-Wx) .
提出的自适应一致性先验(ACP). 先前的分析激发了ACP的提出,它整合了FD、非线性滤波和可靠性估计的概念。设T(·):Rn→Rn·m表示一个变换函数,Λ=D(a1,...,al,...anm)∈Rnm×nm为主对角线上元素al-s的对角线可靠性矩阵(al > 0),K(·):Rn·m→Rn·m表示一个非线性滤波算子。ACP可以写成
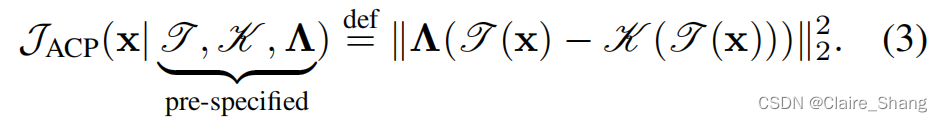
JACP(·)的不同设置有一些有趣的特殊情况。例如,JACP(x|I, K, Λ) = ||Λ(x-K(x))||22成为像素域中的ACP; JACP(x|I,W, I) = JCP(x)成为原始一致性先验。也就是说,一致性先验是ACP的一个特例,扩展了JCP(·)的函数空间,对JACP(·)中的复杂约束关系进行建模。
提出的去噪优化问题. 让X=T(x)和Xk+∆X=X,那么K(Xk+∆X)可以用大约在第k次迭代周围的Taylor级数来近似:
![]()
其中Jk是雅可比矩阵,因此我们可以得到(结合(3)(4)代入即可)
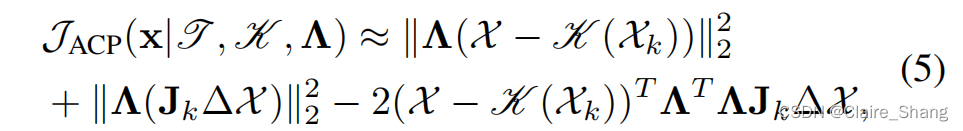
第二项和第三项对一个很小的扰动∆X趋于零。
当X在Xk附近时,我们可以得到一个近似的ACP
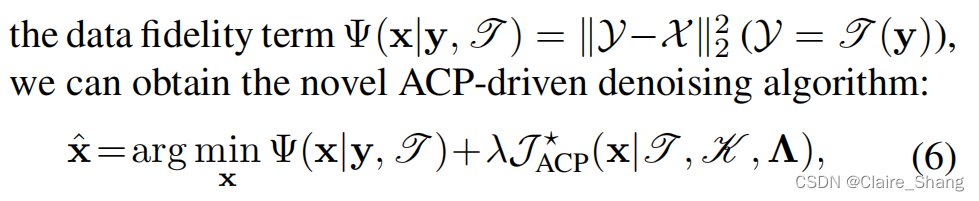
式中λ为正则化参数(λ > 0).由于K(·)、Λ、λ、T(·)是在优化前预设的,因此x是唯一需要估计的未知变量。

证明见补充材料.
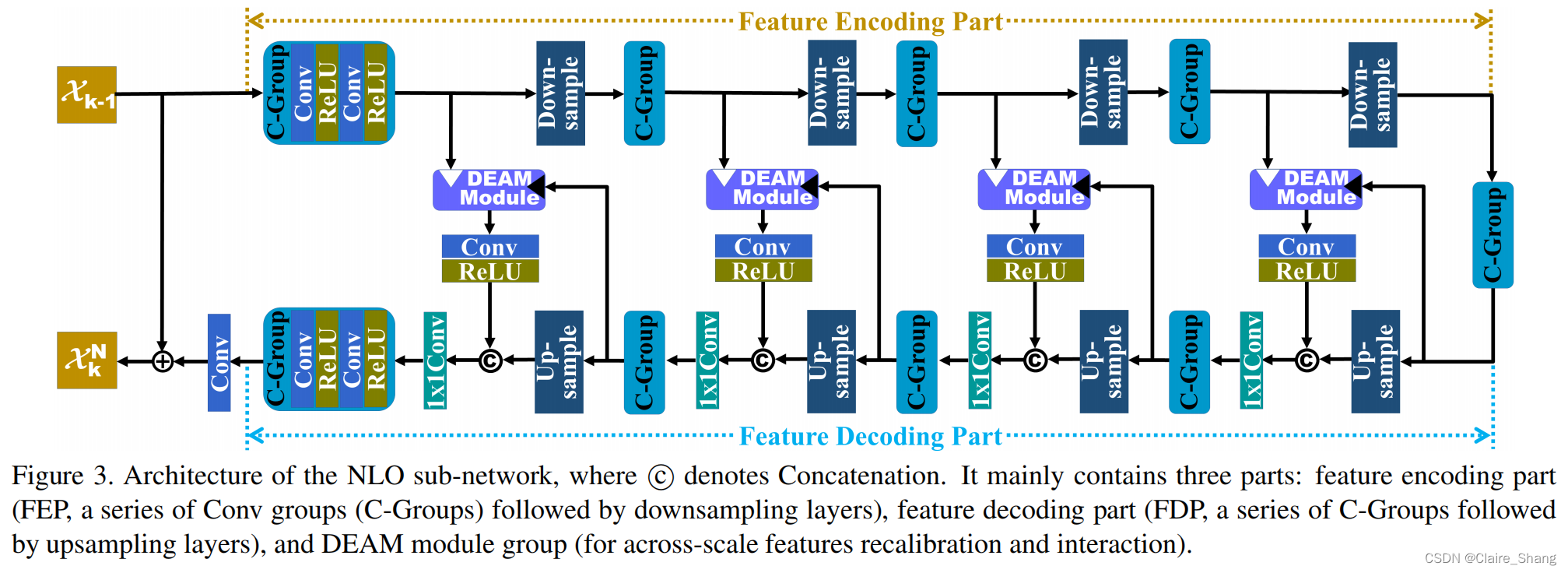
2.2. Deep Unfolding Denoising Network
手动设计{K(·)、Λ、λ、T(·)、L(·)}是非常具有挑战性和耗时的。因此,本文提出的基于模型的框架是通过一个由FD模块(T(·))、重构模块(L(·))、NLO子网络(K(·))和DEAM模块(λ和Λ)构建的深度展开去噪网络来实现的。设Θψ为算子 ψ的可训练参数集。在我们的网络中,超参数λ, Λ, ΘT,ΘK和ΘL以一种判别的方式学习。
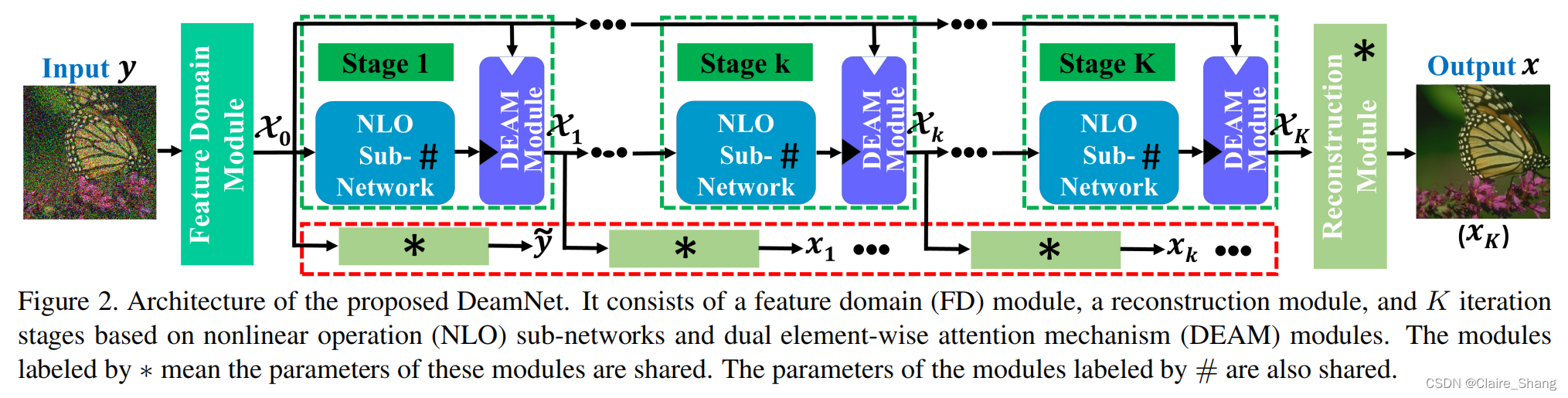
最后,通过重构模块对输出的Xk进行重构,得到第k个图像估计Xk = L (Xk)。另外,为了保证L(·)是T(·)的反转版本,我们在FD模块之后增加了一个由重构模块组成的额外分支,然后强制该分支的输出闭合到输入y。有N个干净-噪声的训练对![]() 我们的网络可以通过优化以下Lp损失函数进行训练:
我们的网络可以通过优化以下Lp损失函数进行训练:
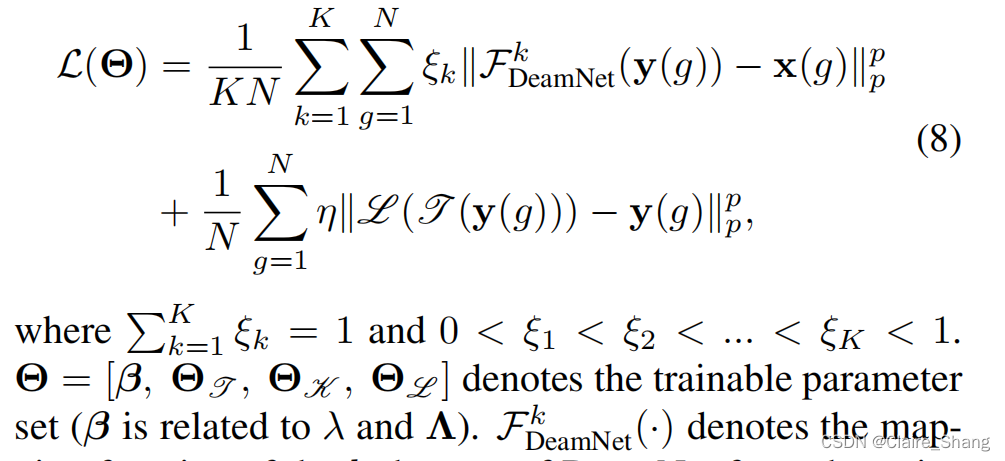
DeamNet(·)表示DeamNet第k阶从噪声图像到干净图像的映射函数. 通过简单地设置![]() ,可以得到
,可以得到![]() 一般来说,L2损失对高斯噪声有较好的置信度,而L1损失对异常值有较好的容忍度。因此,高斯噪声设为p = 2,真实噪声设为p = 1。
一般来说,L2损失对高斯噪声有较好的置信度,而L1损失对异常值有较好的容忍度。因此,高斯噪声设为p = 2,真实噪声设为p = 1。
![]()
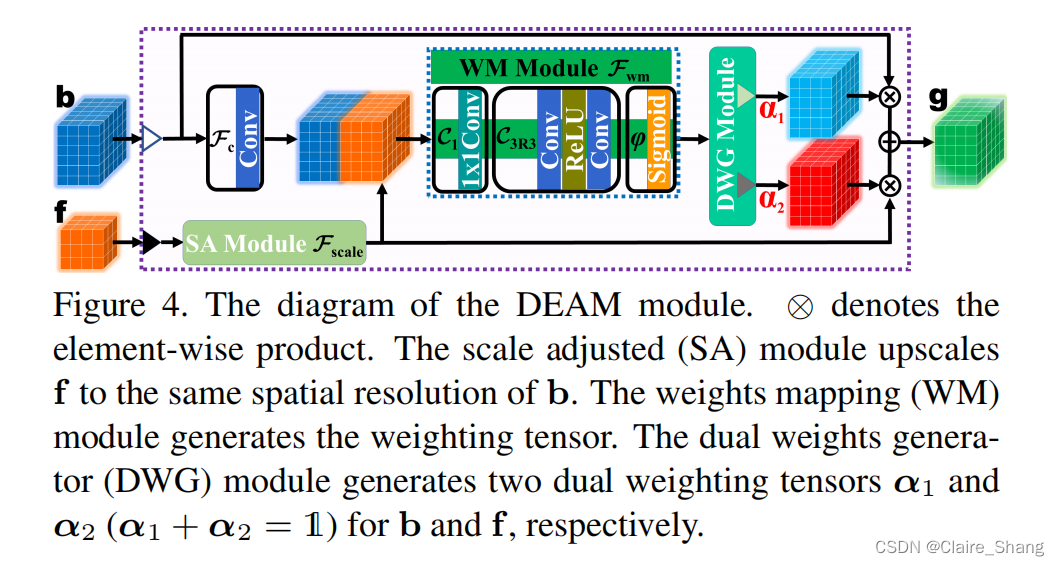
具体来说,DEAM模块有两个输入(粗水平特征b和高水平特征f)和一个输出g。首先,b使用Conv层Fc(·)进行调整,f使用SA模块Fscale(·)进行处理。在我们的网络中,SA模块对于NLO子网络的每一阶段的输出都是一个相同的矩阵,对于NLO子网络中FDP中的C-Group的输出,SA模块是上采样模块。然后,这两个调整后的输入由Concat层连接,获得特征![]() 之后,f0被送到权重映射(WM)模块中。在WM模块中,首先使用1×1Conv层C1来降低f0的维度。接下来,使用两个具有s0和s通道(s0 < s)的3 × 3 Conv层和一个ReLU层生成初始元素特征权重,用于稳定性和非线性。一个sigmoid激活层用于将权值归一化为(0,1)并生成加权张量α,总的来说,α可以写成
之后,f0被送到权重映射(WM)模块中。在WM模块中,首先使用1×1Conv层C1来降低f0的维度。接下来,使用两个具有s0和s通道(s0 < s)的3 × 3 Conv层和一个ReLU层生成初始元素特征权重,用于稳定性和非线性。一个sigmoid激活层用于将权值归一化为(0,1)并生成加权张量α,总的来说,α可以写成
![]()
其中Fwm(·)表示WM运算符,C3R3表示两个3×3 Conv层加一个ReLU的运算符。然后,将α输入到对偶权重生成器(DWG)模块中,分别为b和f生成两个对偶加权张量(即α1 =α和![]() )。最后,DEAM模块的输出可以表示为
)。最后,DEAM模块的输出可以表示为
![]()
在每个迭代阶段的DEAM模块中,采用α = β和![]() 对Y和K (Xk)进行加权。在每个NLO子网络的DEAM模块中,用α和1-α对
对Y和K (Xk)进行加权。在每个NLO子网络的DEAM模块中,用α和1-α对![]() 进行加权。DEAM模块的优点........
进行加权。DEAM模块的优点........
2.3. Further Analyze and Optimize DeamNet
DeamNet是ACP驱动去噪问题的可训练扩展版本,它在一定程度上解释了其数学方法的有效性。但式(8)中使用了很多带有重构模块和损失函数的子分支。这不仅使网络训练难度大,而且限制了网络参数的自由度。此外,在等式中预设参数ξk-s和η也具有挑战性和耗时性 (8). 为了使网络架构和训练更加紧凑,去掉了图2中红色矩形标注的重构模块,因此,采用以下优化的损失函数方案代替原方案:
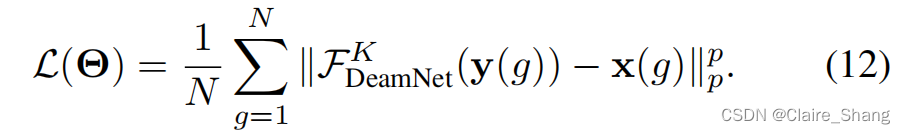
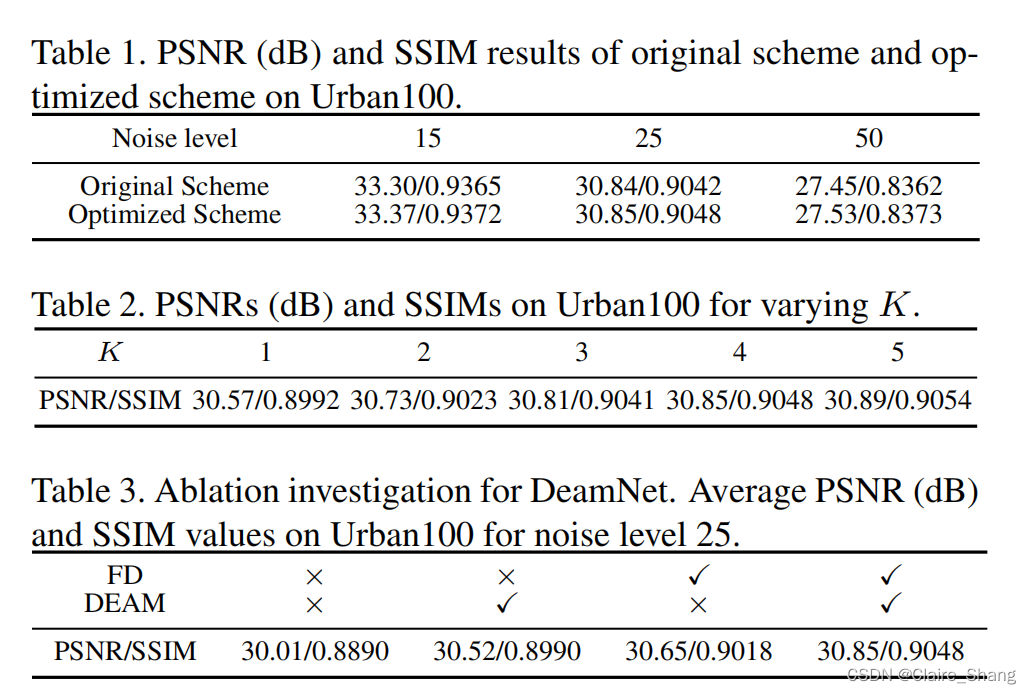
我们比较了这两种方案在Urban100[21]上的噪声水平为15、25、50的附加高斯白噪声(AWGN)。优化后的方案更好(Table1),因此使用优化后的方案作为默认方案。
3. Experimental Results
在本节中,我们演示了我们的方法在合成和真实的噪声数据集上的有效性。由于篇幅有限,在《补充材料》中给出了更多的实验结果和进一步的分析。代码地址:
https://github.com/chaoren88/DeamNet3.1. Network Implementation Details
3.2. Dataset Preparation and Testing
训练DeamNet采用的数据集:Berkeley Segmentation Dataset (BSD) and Div2K
在合成噪声和真实噪声的情况下,我们将这些训练图像对随机裁剪成大小为128×128的小块。为了增加训练样本,应用了旋转180◦和水平翻转。
采用三个数据集对真实图像进行去噪:DnD、 SIDD、 RNI15
3.3. Study of Parameter K (see Table 2)
3.4. Ablation Study (see Table 3)
Table 3 的结果验证了FD处理比DeamNet中的像素域处理更有效。且DEAM模块对DeamNet的性能是必不可少的。 需要注意的是,没有FD和DEAM模块的网络可以看作是传统一致性先验去噪方法的扩展。
3.5. Denoising on Synthetic Noisy Images
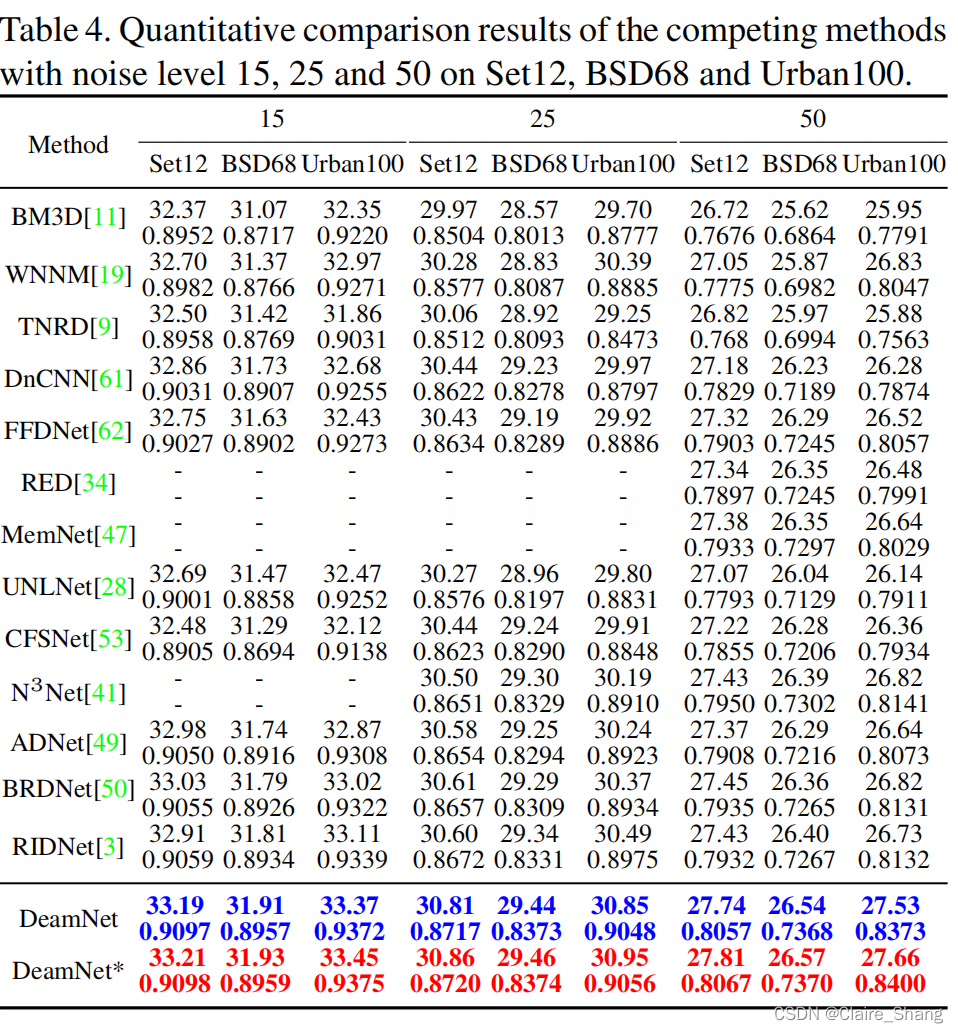
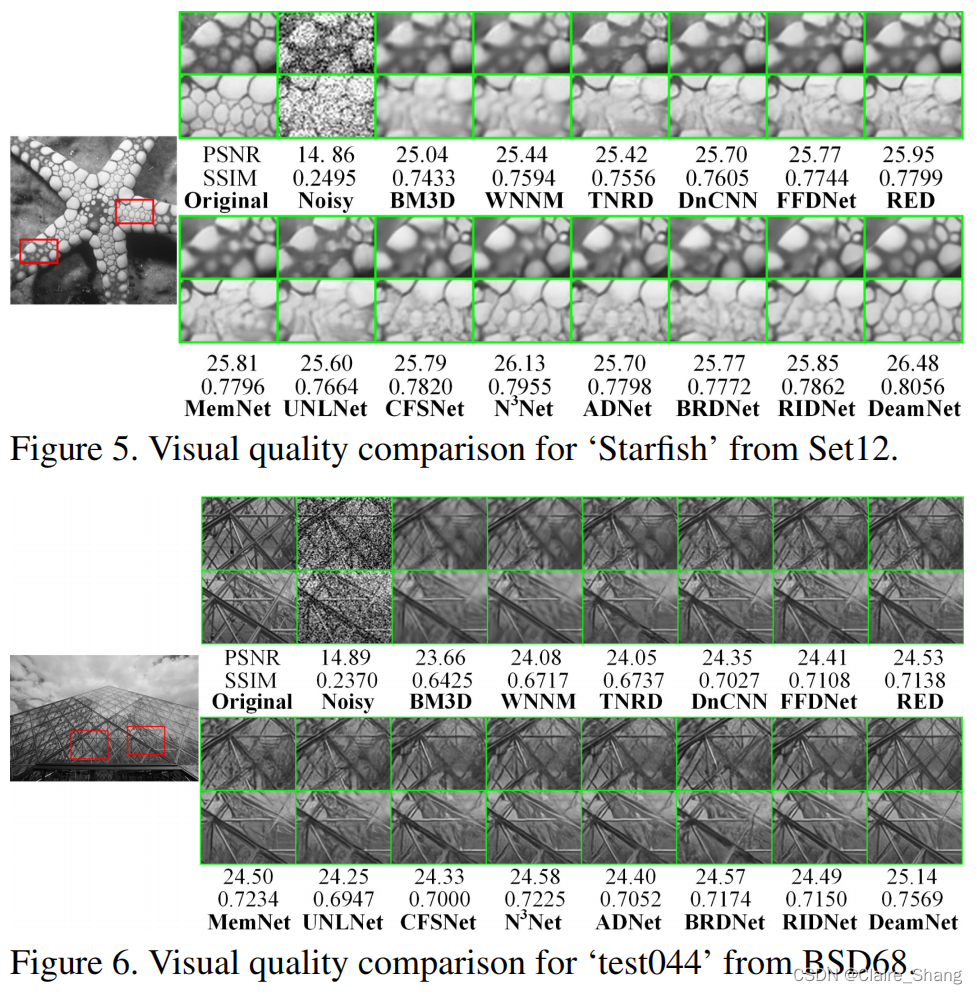
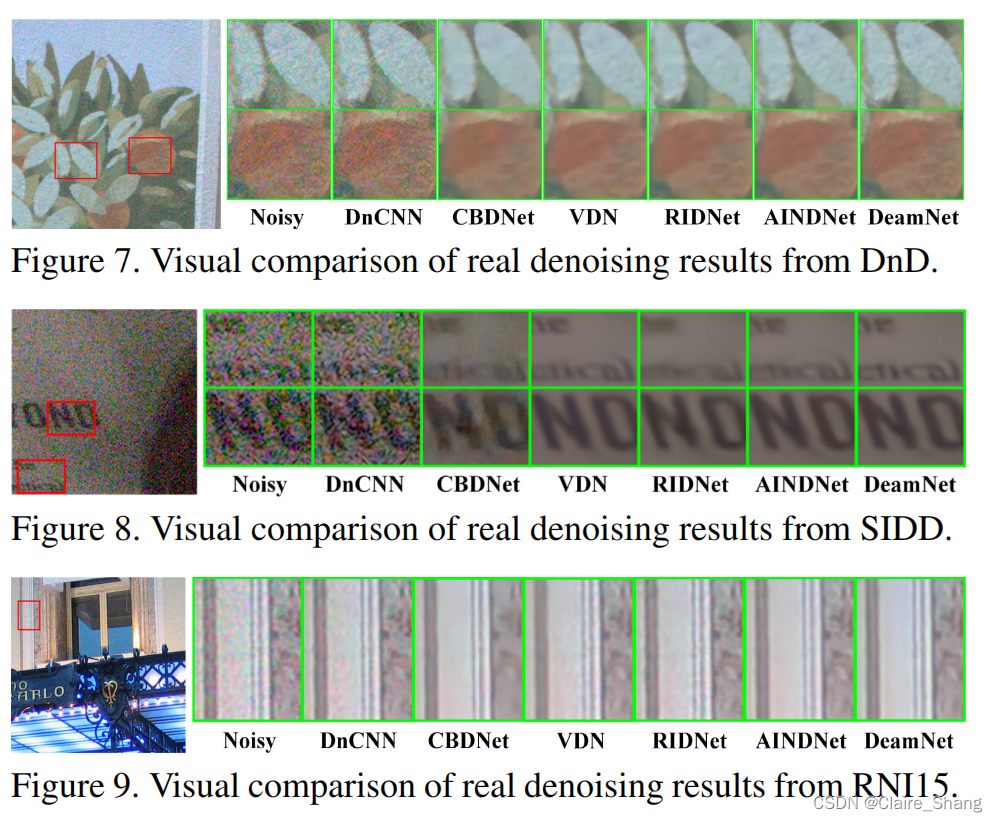
3.6. Denoising on Real Noisy Images
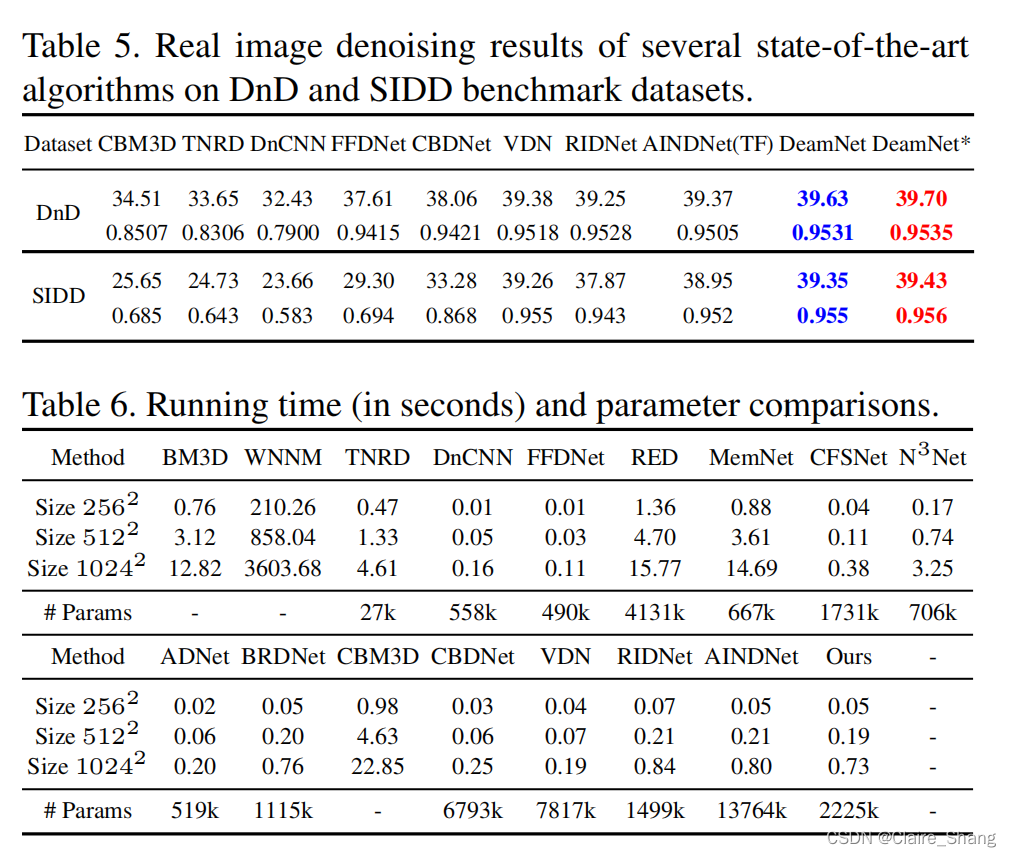
3.7. Computational Complexity(see Table 6)
补充材料:
参数数量
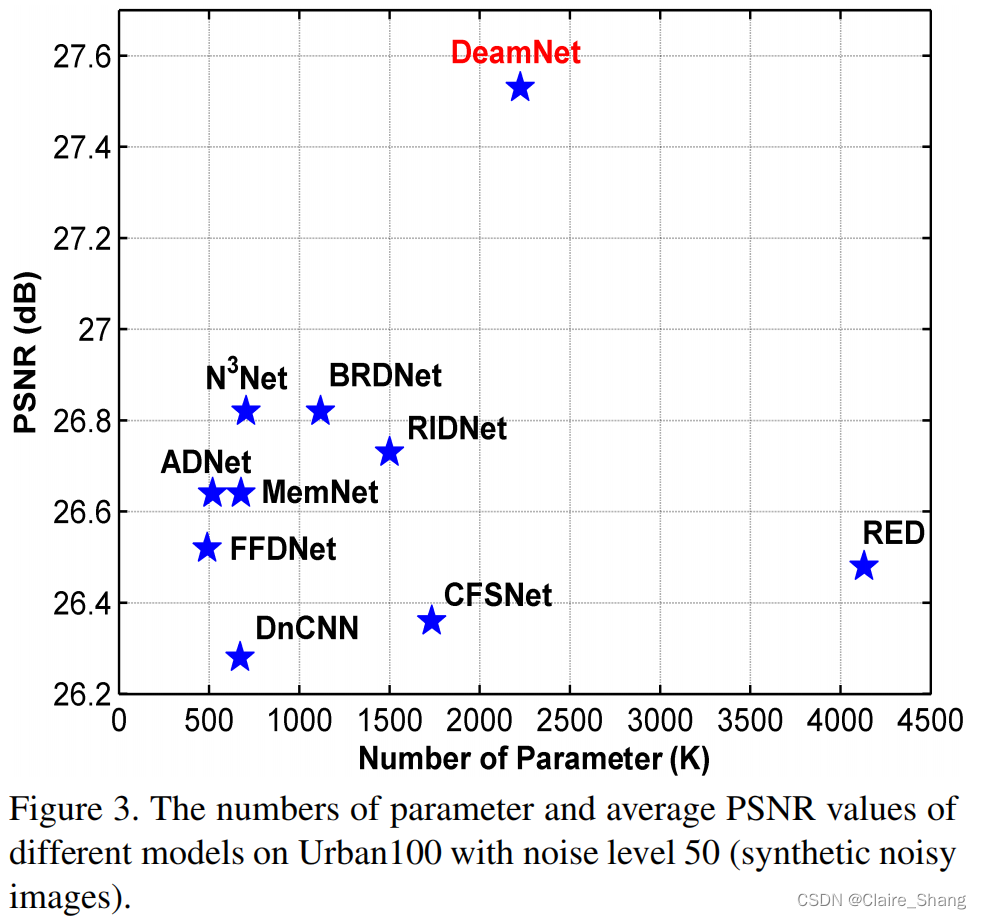
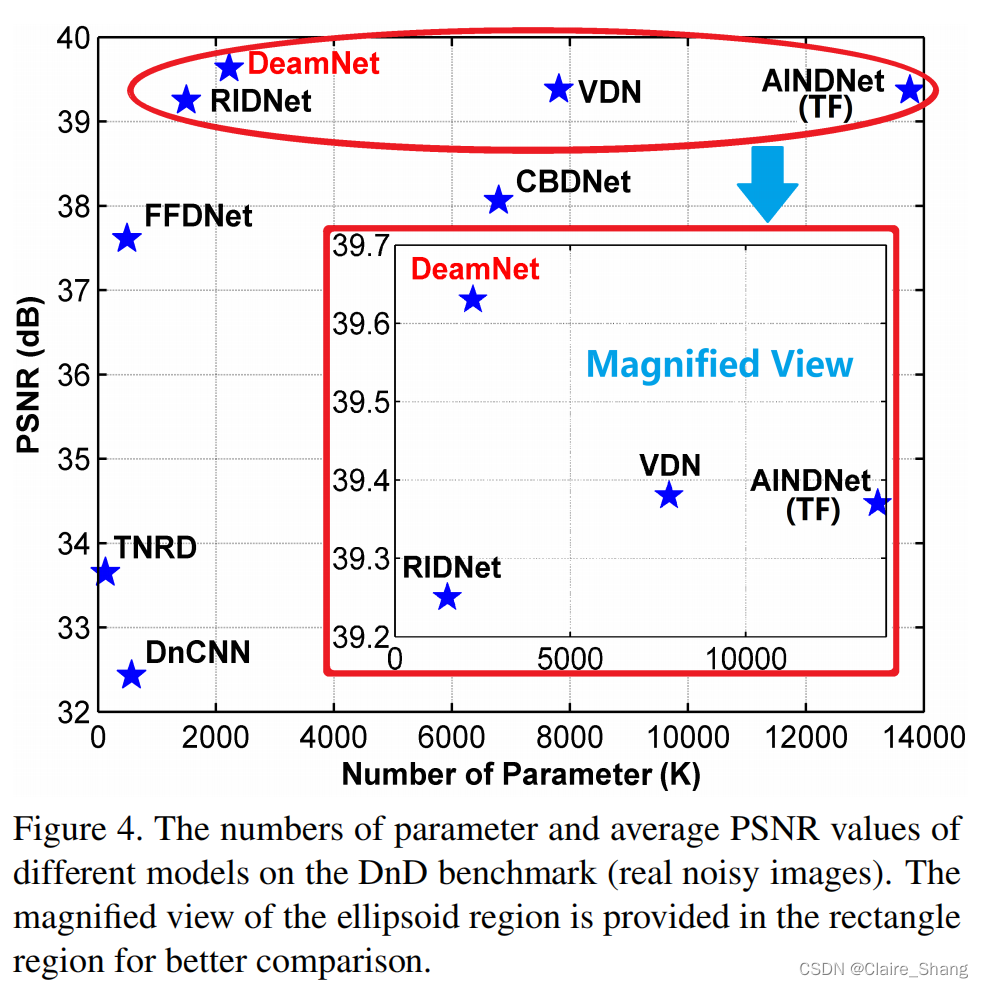
图5-7提供了更多的合成噪声图像的结果,图8-10提供了更多的真实噪声图像的结果。

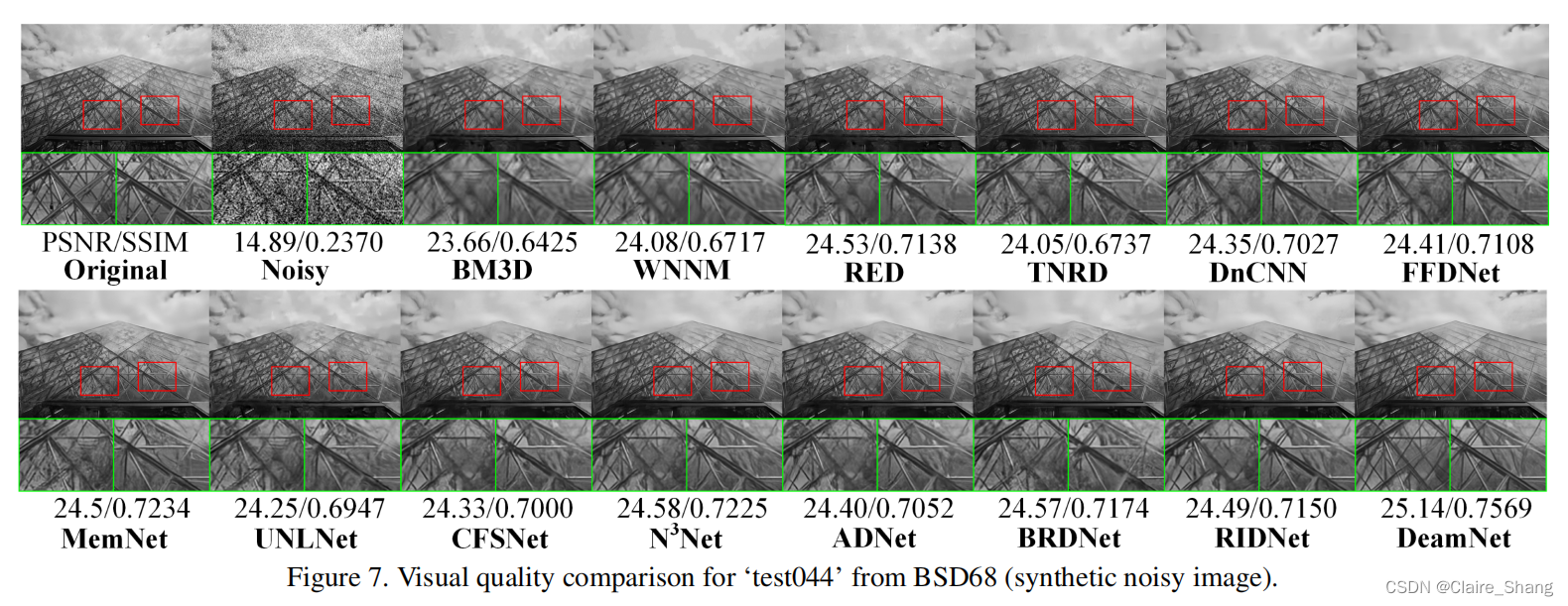
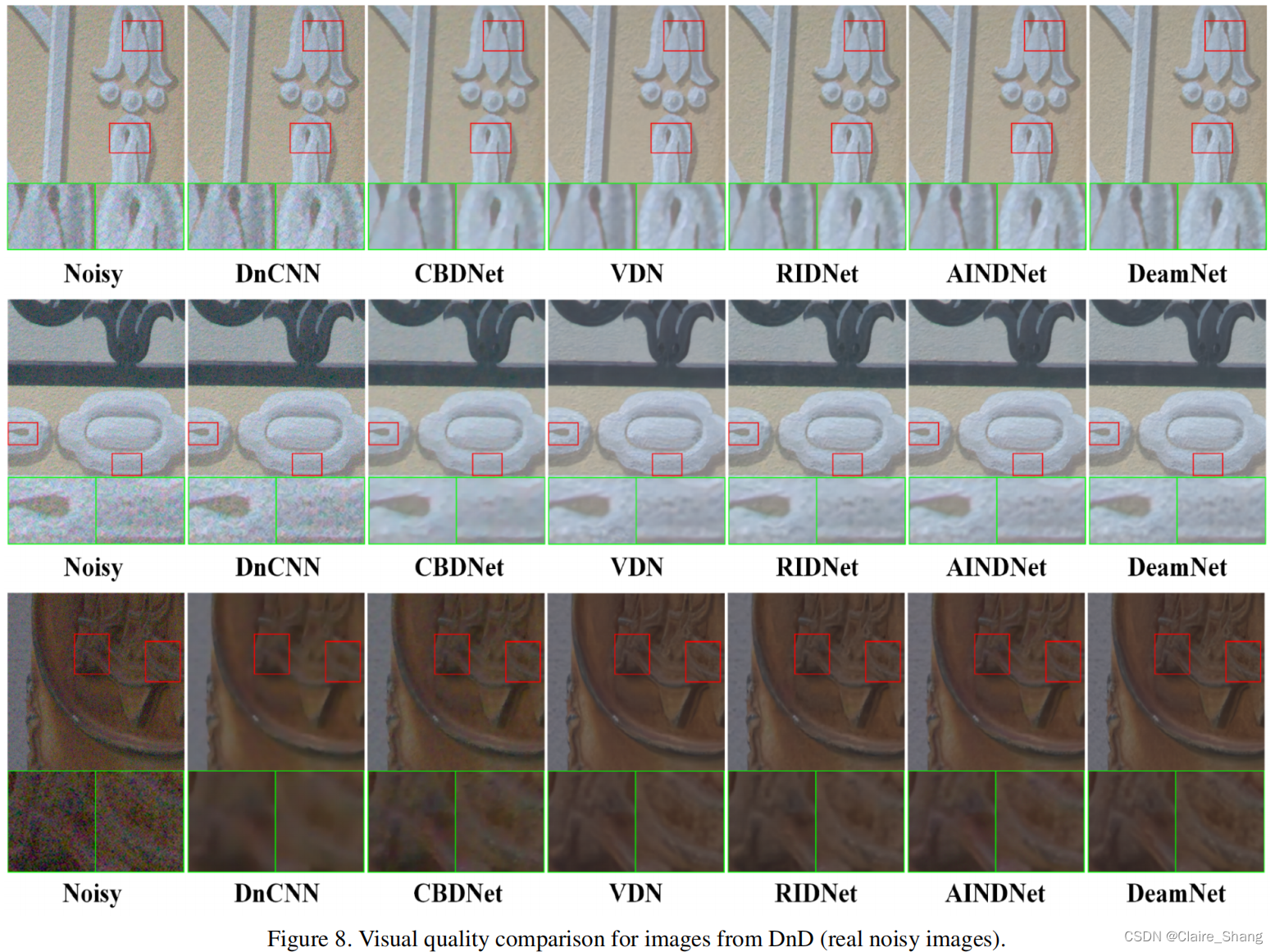


4. Conclusion
本文提出了一种新的深度网络图像去噪方法。与现有的基于深度网络的去噪方法不同,我们加入了新的方法将ACP项引入优化问题,利用优化过程,利用展开策略为深度网络设计提供信息。ACP驱动去噪网络结合了经典去噪方法的一些有价值的成果,并在一定程度上提高了其可解释性。实验结果表明,该网络具有较好的去噪性能。
这篇关于论文阅读| Adaptive Consistency Prior based Deep Network for Image Denoising的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








