本文主要是介绍java毕业设计——基于Java+Moosefs的分布式文件系统设计与实现(毕业论文+程序源码)——分布式文件系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于Java+Moosefs的分布式文件系统设计与实现(毕业论文+程序源码)
大家好,今天给大家介绍基于Java+Moosefs的分布式文件系统设计与实现,文章末尾附有本毕业设计的论文和源码下载地址哦。需要下载开题报告PPT模板及论文答辩PPT模板等的小伙伴,可以进入我的博客主页查看左侧最下面栏目中的自助下载方法哦
文章目录:
- 基于Java+Moosefs的分布式文件系统设计与实现(毕业论文+程序源码)
- 1、项目简介
- 2、资源详情
- 3、关键词
- 4、毕设简介
- 5、资源下载
- 6、更多JAVA毕业设计项目
1、项目简介
-
分布式文件系统,在当今集群存储中起着重要的作用,其中moosefs更是当中的佼佼者,他是一种分布式网络系统,它分布在多个计算机节点上面,每个节点只会存储整个文件的一部分内容,它有多重备份,易于部署,方便扩容等诸多的优点,而且它能够统一接口,使用它就像使用普通的文件系统一样,而且它对小文件的处理,性能优秀。它采用当今主流的Master /Chunk 设计,而且有强大的日志功能,数据恢复更有保证。
-
本文所提及实现的是一个基于分布式文件系统的网盘,主要是通过大量的分布式存储节点提供存储服务,再通过指定的服务器进行挂在到本地,对外提供存储服务。提供统一的开放接口,提供给开发者使用。
此分布式网盘,可以提供数据自动备份,将数据备份为3份,备份到不同的节点至上,从而使得数据的安全性大大的提高。 -
整个开放分布式网盘,主要由三个部分组成,Moosefs,分布式网盘,分布式网盘开放接口。Moosefs主要提供分布式存储,备份,冗余等功能,分布式网盘主要提供逻辑上的操作,开放接口,是分布式网盘对外提供服务的桥梁,开发者通过API来使用分布式网盘,从而提高分布式网盘的使用范围。
2、资源详情
项目难度:中等难度
适用场景:相关题目的毕业设计
配套论文字数:12456个字42页
包含内容:全套源码+配整论文
开题报告、论文答辩、课题报告等ppt模板推荐下载方式:
3、关键词
分布式文件系统 Moosefs 数据恢复 开放式4、毕设简介
提示:以下为毕业论文的简略介绍,项目完整源码及完整毕业论文下载地址见文末。
1 引言
1.1 课题背景与现状
现在网络技术的发展和深入的应用,互联网上的信息呈现爆炸式的增长,大数据,大批量的小文件等等的处理能力越来越重要,尤其是以javascript,css,图片,音频,和视频等文件形式的小中型数据的增长尤为迅速,如何高效的,方便的,安全的,存储和管理这些数据,并且快速的读取,写入等等,已经成为了业界一个难题。
现在计算机技术,人们的需求,正在迅速的发展,几百万亿字节的存储,已经是司空见惯了,cpu,内存等等指标正在不断的提高,但是磁盘的存储能力却一直很难有质的飞跃,对于大数据,大量的文件的处理,人们一直为之头疼。人们对于存储系统的速度,容量以及可靠性提出了极高的要求。
由此,分布式文件系统油运而生,若能解决这个问题,则未来几年的存储将会不再是Internet发展的瓶颈或者是制约因素,而且基于大数据的应用,更加能够促进国民经济的发展。
1.2 选题价值与意义
关与分布式存储,将信息分布式存储,首先对骨干网络的带宽相对要求较低,其次是有较高的容错性能,之后,分布式存储,相对于集中式存储,每个节点相对独立,而且数据分散,数据的安全性的得到了保证。
选择研究分布式存储,当前,最火的词汇就是云存储,移动与联网,而这两个东西,都离不开分布式存储,因为他们都会产生大量的数据,大量的数据就需要好的存储系统,对存储要求更高。而本地文件系统由于是单个节点本身的局限性,已经很难满足海量数据存取的需求了,因此,不得不借助分布式文件系统来解决这一难题,把系统的负载转移到多个节点之上。如果我能在学校了解到这方面的知识,将会更好的适应外面的企业。符合外面企业的要求。
1.3 研究内容
在这个课题中,我主要的研究内容是基于Moosefs的分布式存储,其他的内容也会涉及,和Moosefs进行对比。而且我更侧重与中小文件的性能,对大文件的要求不高。
1.4 论文结构
本文第一章为引言主要是介绍技术的背景和现状,研究这个问题的意义所在。第二章主要是进行分布式文件系统基础知识的讲解,包括流行的hadoop,GFS,TFS等当前流行的文件系统的介绍。第三章主要是将Moosefs文件系统的系统架构,包括它系统架构,机器架构等相关的知识介绍。第四章主要是介绍的基于Moosefs文件系统搭建的网盘实现,包括系统分析,设计,实现等核心技术问题。第五章主要是对搭建的网盘进行测试。
2 分布式文件系统的介绍
2.1 研究方法和技术路线
当前的存储分为两大类型,分别是分布式存储和集中式存储
关于集中式共享存储,这类多处理机在目前至多有几十个处理器。由于处理器数目较小,可通过大容量的Cache和总线互连使各处理器共享一个单独的集中式存储器。因为只有一个单独的主存,而且从各处理器访问该存储器的时间是相同的,所以这类机器有时被称为UMA(Uniform Memory Access)机器。它的优点就是数据集中,方便管理,但是也存在许多的缺点,其中由于数据太集中,容灾性差,是它致命的缺点,如下图2.1.1是它的基本架构图。
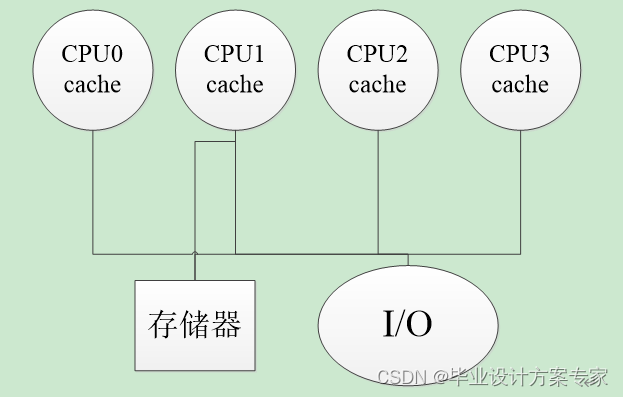
图 2.1.1 集中式共享存储器多处理机基本架构图
而关于分布式存储,它具有分布的物理存储器。为支持较大数目的处理器,存储器必须分布到各个处理器上,而非采用集中式,否则存储器系统将不能满足处理器带宽的要求。系统中每个结点包含了处理器、存储器、I/O以及互连网络接口。随着处理器性能的迅速提高和处理器对存储器带宽要求的不断增加,甚至在较小规模的多处理机系统中,采用分布式存储器结构也优于采用集中式共享存储器结构(这也是不按规模大小进行分类的一个原因)。当然,分布式存储器结构需要高带宽的互连。如下图2.1.2所示
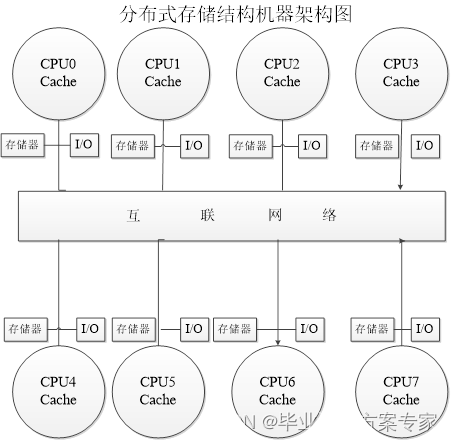
图 2.1.2 分布式存储结构机器架构图
将存储器分布到各结点有两个好处,其一,如果大多数的访问是针对本结点的局部存储器,则可降低对存储器和互连网络的带宽要求,其二,对局部存储器的访问延迟低。分布式存储器体系结构最主要的缺点是处理器之间的通信较为复杂,且各处理器之间访问延迟较大。
通常情况下,I/O和存储器一样也分布于多处理机的各结点当中。每个结点内还可能包含较小数目(2~8)的处理器,这些处理器之间可采用另一种技术(例如通过总线)互连形成簇(cluster),这样形成的结点叫做超结点。采用超结点对机器的基本运行原理没有影响。由于采用分布式存储器结构的机器之间的主要差别在于通信方法和分布式存储器的逻辑结构方面,所以本章将集中讨论每个结点只有一个处理器的机器。
2.2 Hadoop中HDFS介绍
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS(Hadoop Distributed File System)是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。(陆嘉桓 etc 2012),以下是HDFS的架构图。
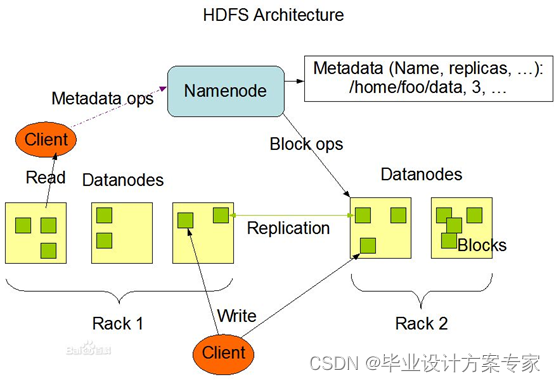
图2.2.1 HDFS架构图
HDFS中进行数据存储的时候,将数据分成多分存储到不同的节点中。如下图2.2.2 所示,HDFS有如下的有点,如硬件故障检测和自动快速恢复,因为HDFS设计之初就以大量的廉价机器为设计初衷,它把硬件故障认为是常态而不是异常。其次,流式数据的数据访问模型,HDFS是被手机城市和处理批量的,而不是用户交互式,它的重点是数据的吞吐量,而不是数据的反应时间。再者,大数据集,典型的HDFS文件大小是GB到TB的级别,他提供了很高的聚合数据带宽,一个集群之中支持数百个节点,故而保证了可以支持到大数据集,而且有简单的一致性模型,HDFS设计之初,就对文件操作进行了定位,为一次写多次读取的操作模式,一个文件一旦被创建,写入,关闭之后就不需要修改。通过这个简单化的数据一致性问题和并使得高吞吐量的数据访问变成了可能。先进的NameNode 和DataNode设计,HDFS是一个主从结构,一个HDFS由一个NameNode,它是管理文件命名空间和调节客户端访问文件的主服务器,还有许许多多的DataNode,他是管理对应节点的存储,HDFS对外开放文件命名空间,而且允许用户数据源文件的形式进行存储。优秀的文件系统的元数据的持久化功能,HDFS的命名空间是由NameNode节点来存储。NameNode使用叫做EditLog的事务日志来持久记录每一个对文件系统数据的改变,从而保证文件系统的持久化。
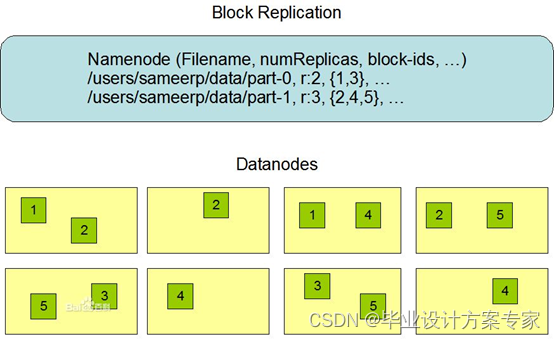
图 2.2.2 HDFS存储示意图
当然,HDFS也有一些缺点,如对小文件处理较为困难,因为HDFS默认64M,只有当本地机器存储超过此空间才会将数据写入到HDFS中,所以若遇到大量的小文件,就相对吃力了,而且如果访问大量的小文件,需要从一个DataNode跳到另外一个DataNode,从而严重影响性能。再者,访问有一定的延时,主要是两个方面,由于HDFS设计之初,就是以吞吐量为重点,从而相对忽略了延时问题,其二是Java本身效率不高。最后,也是最为人诟病的,只能支持单个Master,如Master出现了故障,整个集群将不能提供服务,从而造成不能预计的损失。
2.3 传统NFS文件系统介绍
NFS是Network File System的简写,即网络文件系统.网络文件系统是FreeBSD支持的文件系统中的一种,也被称为NFS. NFS允许一个系统在网络上与他人共享目录和文件。通过使用NFS,用户和程序可以像访问本地文件一样访问远端系统上的文件。(蔡明德 2010)
NFS至少有两个主要部分:一台服务器和一台(或者更多)客户机。客户机远程访问存放在服务器上的数据。为了正常工作,一些进程需要被配置并运行。
NFS 有很多实际应用。下面是比较常见的一些,多个机器共享一台CDROM或者其他设备。这对于在多台机器中安装软件来说更加便宜跟方便。在大型网络中,配置一台中心 NFS 服务器用来放置所有用户的home目录可能会带来便利。这些目录能被输出到网络以便用户不管在哪台工作站上登录,总能得到相同的home目录。几台机器可以有通用的/usr/ports/distfiles 目录。这样的话,当您需要在几台机器上安装port时,您可以无需在每台设备上下载而快速访问源码。
以下是NFS最显而易见的好处,本地工作站使用更少的磁盘空间,因为通常的数据可以存放在一台机器上而且可以通过网络访问到。用户不必在每个网络上机器里头都有一个home目录。Home目录 可以被放在NFS服务器上并且在网络上处处可用。诸如软驱,CDROM,和 Zip(是指一种高储存密度的磁盘驱动器与磁盘)之类的存储设备可以在网络上面被别的机器使用。这可以减少整个网络上的可移动介质设备的数量。
当然NFS也有很多的缺点,容错性不佳,和其他分布式文件系统相比,NFS不具备数据备份功能,而且日志功能较为简单,很难进行数据恢复。最不好的是他的可扩展性能,NFS只能支持类UNIX系统,对windows系统不支持,而且同时使用用户较低。
2.4 闭源的GFS介绍
GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,但可以提供容错功能。它可以给大量的用户提供总体性能较高的服务。
GFS 也就是 google File System,google公司为了存储海量搜索数据而设计的专用文件系统。以下是GFS的体系架构图
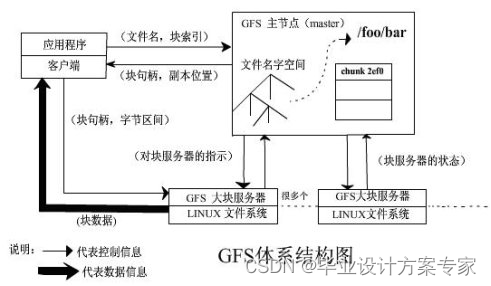
图 2.4.1 GFS体系架构图
GFS有点很多高可用性,如果一个GFS客户失效,数据可以通过其它的GFS高效访问,可扩展性能,不需要中心数据中心,容易扩展存储的容量和访问的带宽,对大数据处理能力强。容错能力强,它的数据同时会在多个chunk server上进行备份,具有相当的容错性能。
当然GFS也有许多的缺点,如没有实现像POSIX那样标准的API,从而若使用GFS,则很多上层的应用需要修改。文件在目录中按层次组织起来并有路径名标示,对大量的小文件处理不佳,当大量的小文件访问的时候,将严重的影响性能,单Master设计,Master会压力过大,可能会让整个集群宕机。
2.5 开源的TFS介绍
TFS(Taobao File System)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化了文件的访问流程,一定程度上为TFS提供了良好的读写性能。(淘宝核心技术人员 2011)
TFS有不少有优点,首先,它是由两个NameServer节点组成(一主一备)和多个DataServer组成,而且这些服务程序是作为一个用户级别的程序运行在普通Linux机器上面,它是将大量的小文件合并为一个大文件来进行存储 。同时为了容灾,NameServer采用HA结构,即两台机器互为热备份,同时运行,一主一备,当主机宕机后,迅速切换到备份NameServer中,对外提供服务。TFS设计是针对小文件设计的而且会将写请求尽可能的均匀的分布在不同的DataServer之中,而且用平滑的扩容机制,当需要系统扩容时,只需要对将相对应的心DataServer部署好,启动即可。
当然也有不少缺点,如对大文件处理不佳,因为TFS大小的块大小为64M,设计初衷是为小文件设计,所以大文件处理不佳。
2.6 较新Moosefs文件系统介绍
Moosefs是一款网络分布式文件系统,它把数据分散在多台服务器上,但是对用户来讲,看到的只是一个源。MFS也像其他类Unix文件系统一样,包含了层次结构(目录树),存储着文件属性(权限,最后访问和修改时间),可以创建特殊的文件(块设备,字符设备,管道,套接字),符号连接,硬链接等。
MooseFS文件系统结构包括以下四种角色:管理服务器managing server (master),元数据日志服务器Metalogger server(Metalogger),数据存储服务器data servers(chunkservers),客户机挂载使用client computers。
Moosefs拥有以下的特性,首先,它是免费的,因为它支持的是GPL协议,其次它拥有通用文件系统,不需要修改上层应用就可以使用,可以直接挂载到本地,像使用本地文件一样,并且可以在线扩容,体系架构可伸缩性极强。(官方的case可以扩到70台了!),而且部署简单,只需要修改一下配置文件就能运行了。高可用,可设置任意的文件冗余程度,提供比raid1+0更高的冗余级别,而绝对不会影响读或者写的性能,只会加速!可回收在指定时间内删除的文件,“回收站”提供的是系统级别的服务,不怕误操作了,提供类似oralce 的闪回等高级dbms的即时回滚特性!提供netapp,emc,ibm等商业存储的snapshot特性,可以对整个文件甚至在正在写入的文件创建文件的快照,google filesystem的一个c实现。
MFS 的读取数据过程:
- Client当需要一个数据的时候,首先向master server发起查询请求
- 管理服务器检索自己的数据,获取到数据所在的可用的数据服务器位置ip|port|chunkid
- 管理服务器将数据服务器的地址发送给客户端
- 客户端向具体的数据服务器发起数据获取请求
- 数据服务器发送给客户端
如下图所示,MFS读取数据时原理图
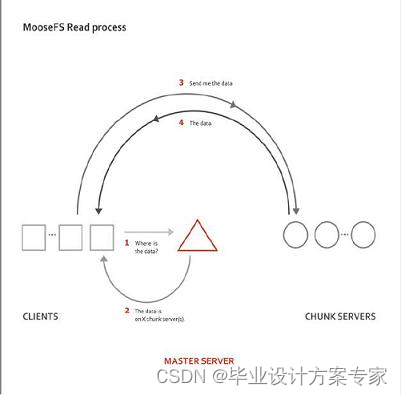
图 2.6.1 MFS读取数据原理图
MFS的写数据过程:
- 当客户端有数据写需求时,首先向管理服务器提供文件元数据信息请求存储地址(元数据信息如:文件名|大小|份数等)
- 管理服务器根据写文件的元数据信息,到数据服务器创建新的数据块
- 数据服务器返回创建成功的消息
- 管理服务器将数据服务器的地址返回给客户端(chunkIP|port|chunkid)
- 客户端向数据服务器写数据;
- 数据服务器返回给客户端写成功的消息;
- 客户端将此次写完成结束信号和一些信息发送到管理服务器来更新文件的长度和最后修改时间
- 一个写操作就此完成
下面是MFS 写数据原理图如图2.6.2 所示:
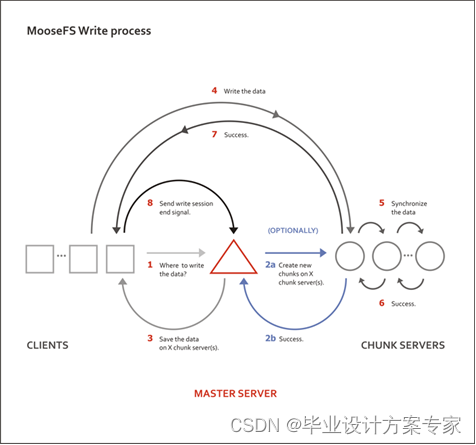
图 2.6.2 MFS 写数据原理图
MFS的删除文件过程
- 客户端有删除操作时,首先向Master发送删除信息;
- Master定位到相应元数据信息进行删除,并将chunk server上块的删除操作加入队列异步清理;
- 响应客户端删除成功的信号
- MFS修改文件内容的过程
- 客户端有修改文件内容时,首先向Master发送操作信息;
- Master申请新的块给.swp文件,
- 客户端关闭文件后,会向Master发送关闭信息;
- Master会检测内容是否有更新,若有,则申请新的块存放更改后的文件,删除原有块和.swp文件块;
- 若无,则直接删除.swp文件块。
MFS重命名文件的过程 - 客户端重命名文件时,会向Master发送操作信息;
- Master直接修改元数据信息中的文件名;返回重命名完成信息;
- MFS遍历文件的过程
- 遍历文件不需要访问chunk server,当有客户端遍历请求时,向Master发送操作信息;
- Master返回相应元数据信息;
- 客户端接收到信息后显示
2.7 各种分布式文件系统的概要分析
首先,文本首先对需求进行分析,对这个文件系统的定位是大量普通用户使用的一个海量存储文件系统。正常情况下,普通用户的文件以文档,图片,音频,视频居多。大部分文件在10M以下。
其次,普通的用户,一般情况下以上传信息居多。而且文件系统要易于扩展,方便扩容,再者文件系统要有较强的容错性,最好自身带有备份功能。
关于Hadoop的分析,HDFS上,每一个文件都需要在namenode上建立一个索引,一个索引大约150byte,当小文件比较多的时候(小于一个block被HDFS视为一个小文件),就会产生许许多多的索引文件,一方面,会大量的占用NameNode的内存空间,另一方面,就是索引文件过大,会让索引速度变得很慢。HDFS的设计思路是多次读,少量写操作,这个和我们定位有所不同。
关于NFS的分析,NFS 搭建简单,但是可扩展性能差,NFS不带备份功能。NFS 可以搭建的最大容量有限。
关于GFS的分析,由于是GFS闭源,即使性能很优秀,但是不能使用。
关于TFS的分析,对小文件处理优秀,但对稍大的文件处理困难。
关于Moosefs的分析,MFS自带备份功能,MFS对小文件处理能力强,MFS对大文件处理能力强,MFS自带日志功能,MFS可扩展性能强。
综上所述,选择Moosefs。原因如下,首先,它对大文件,小文件的支持力度较高,其次它有着较强的可扩展性能,再者容错备份功能齐全。故而选之。
3 文件系统的架构
3.1 平台要求
目前Moosefs只能支持类UNIX操作系统,如Linux内核的操作系统,Unix如Solaris,MacOx等,不支持Windows。
若是Linux内核,建议使用2.6或者以上内核,才能很好的支持到FUSE功能,可以将Moosefs很好的挂在到本地使用。
3.2 机器架构
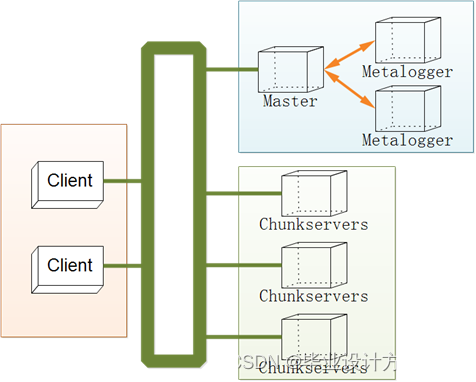
图 3.3.2 机器架构图
Moosefs主要是由四种类型的角色,它们分别是Master(主控服务器),主要负责各个数据存储服务器的管理,文件读写调度,文件空间回收以及恢复,多节点的拷贝等等功能,Metalogger(日志服务器)主要负责Master服务器的变化的日志文件,若Master Server出现问题的时候,可以接替进行工作,ChunkServers负责管理服务器,听从Master调度,并提供存储空间,为客户提供数据传输,Client,主要是通过fuse内核接口挂接远程的Master服务器上面,看起来共享的文件系统和本地的Uinx文件系统使用效果一样。
3.3 文件系统架构
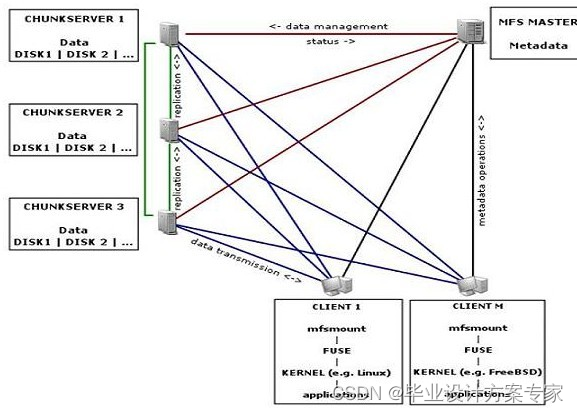
图 3.3.1 文件系统架构
Moosefs分布式文件系统,主要是通过一个master来管理多个chunkservers进行分布式存储,让整个chukservers群中的存储空间得到共享,通过metalogger服务器进行日志记录和数据删除后的回滚。用户通过fuse来将分布式文件系统挂载到本地,想访问普通的文件系统一样,提工一个抽象,使得用户在不需要更改上层应用的情况下,可以使用分布式文件系统。
3.4 分布式文件系统的搭建
我采用了8台主机搭建实验使用的分布式文件系统,一台主服务器,作为Master,一台日志服务器,用于日志备份和记录,四台ShunkServer,用于存储数据,之后将MFS挂载在两台机器上面,有两台clinet对外提供服务。
以下是文件系统的架构图,如下图3.5.1所示。
它们统一安装的Archlinux 内核版本是Linux 3.8,java版本是JDK7,安装了FUSE。
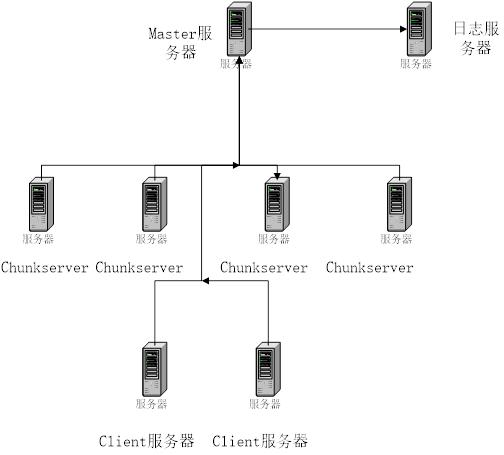
图 3.5.1 文件系统机器架构图
3.5 性能测试
二级100*100目录 创建 列表 删除
单片15k.5
ext3
client单进程 real 0m0.762s
user 0m0.048s
sys 0m0.261s real 0m0.179s
user 0m0.036s
sys 0m0.125s real 0m0.492s
user 0m0.036s
sys 0m0.456s
单片15k.5
ext3
client 10并发进程 real 0m0.724s
user 0m0.015s
sys 0m0.123s real 0m0.057s
user 0m0.006s
sys 0m0.025s real 0m0.226s
user 0m0.010s
sys 0m0.070s
6chunkserver
cache
client单进程 real 0m2.084s
user 0m0.036s
sys 0m0.252s real 0m4.964s
user 0m0.043s
sys 0m0.615s real 0m6.661s
user 0m0.046s
sys 0m0.868s
6chunkserver
cache
client 10并发进程 real 0m1.422s
user 0m0.007s
sys 0m0.050s real 0m2.022s
user 0m0.008s
sys 0m0.108s real 0m2.318s
user 0m0.008s
sys 0m0.136s
进行小文件性能测试,采取的是两级目录,1000*1000的方式。
二级1000*1000目录 创建 列表 删除
单片15k.5
ext3
client单进程 real 11m37.531s
user 0m4.363s
sys 0m37.362s real 39m56.940s
user 0m9.277s
sys 0m48.261s real 41m57.803s
user 0m10.453s
sys 3m11.808s
单片15k.5
ext3
client 10并发进程 real 11m7.703s
user 0m0.519s
sys 0m10.616s real 39m30.678s
user 0m1.031s
sys 0m4.962s real 40m23.018s
user 0m1.043s
sys 0m19.618s
6chunkserver
cache
client单进程 real 3m17.913s
user 0m3.268s
sys 0m30.192s real 11m56.645s
user 0m3.810s
sys 1m10.387s real 12m14.900s
user 0m3.799s
sys 1m26.632s
6chunkserver
cache
client 10并发进程 real 1m13.666s
user 0m0.328s
sys 0m3.295s real 4m31.761s
user 0m0.531s
sys 0m10.235s real 4m26.962s
user 0m0.663s
sys 0m13.117s
由此分析可见,当进行单盘多进程操作的时候,性能提升的空间有限,主要是IO瓶颈制约,甚至消耗了大量的系统调用,当进行多盘的时候,性能有了巨大的提升。
4 开放网盘的实现方式
4.1 需求分析
首先我们对本系统进行定位,系统供开发者使用,他们一般都具备一定的计算机水平,可以熟练的操作计算机,数据库,操作系统等等。而且要具备如下的功能,具有上传,下载功能的开放接口,具有权限控制的接口,具有安全快捷认证的用户接口,具有注册用户,修改用户信息的接口,具有显示目录信息的接口具有删除文件,目录的接口,具有移动文件,目录的接口,具有数据删除后恢复功能,并提供开放接口。而且要自动帮用户进行数据备份。
4.2 系统分析
系统主要用例,开发者通过用户的授权,获取权限,进行操作,如修改文件的目录,获取文件的信息,下载文件,修改文件内容,移动文件等操作。
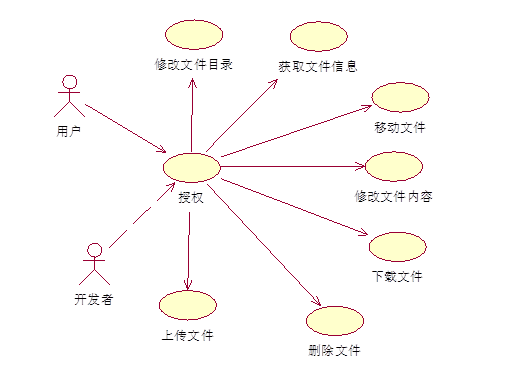
图 4.2.1 系统主要用例图
Aouth2.0授权顺序图
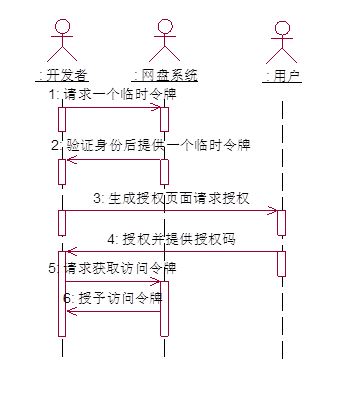
图 4.2.2 Aouth2.0授权顺序图
开发者首先向系统请求一个临时令牌,系统验证开发者的身份后,授予一个临时的令牌,开发者获取了临时令牌后,通过自己的信息和临时令牌,将用户引导至系统的授权页面请求用户的授权,在这个过程中临时令牌和开发者毁掉连接发送给系统,用户在系统提供的页面输入用户名和密码,然后授权该开发者访问锁请求的资源,授权成功后,系统将引导用户返回到开发者的页面,开发者根据临时令牌,从系统中获取访问的临牌,系统根据临时临牌和用户的授权情况授予开发者访问令牌,开发者获得令牌后,访问系统中用于受保护的资源。
用户获取目录信息顺序图,如下图 4.2.3所示,用户请求获取指定目录的信息,系统首先查看请求中是否含有授权,若有授权则通过,否则将拒绝。当权限允许的时候,调用封装好的Driver进行访问指定的路径,获取目录信息,若不存在目录,则返回空,存在则将之保存为对象传给xml生成器,xml生成器生成xml,并将之返回给Servlet,Servlet将生成xml的响应回复给用户。
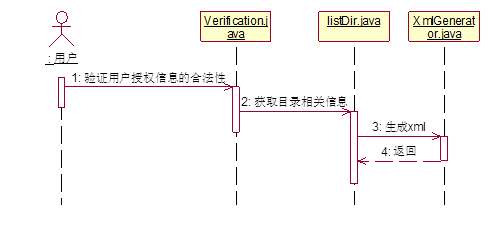
图 4.2.3 用户获取目录信息
以下是上传文件顺序图用户请求上传指定文件,系统首先验证用户的请求是否合法,若有授权则通过,否则将拒绝,当权限允许的时候,首先对文件的类型进行检测,是否符合系统要求,不符合则拒绝,之后获取上传文件列表,将文件上传至指定的目录中,首先判断目录是否存在,若不存在则递归的创建目录,并上传,最后生成上传报告,并将上传报告返回给用户。如图4.2.4所示
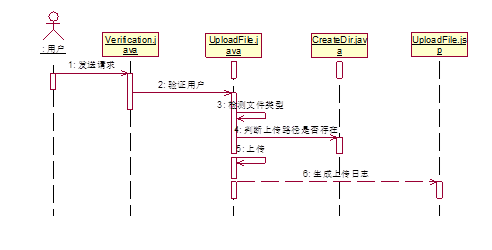
图 4.2.4 上传文件顺序图
4.3 网盘的架构
普通用户,通过开发者的应用来进行使用网盘,开发者同过网盘提供的API来进行访问网盘,进行操作,而网盘和分布式文件系统相对独立,网盘调用分布式文件系统中封装好的接口,进行分布式文件系统的使用。
总体来说,设计的时候,把网盘分成了3层架构,分别是存储层,逻辑层(基础管理层),应用接口交互层。
存储层采用Moosefs来做为存储实现的。由Moosefs来进行存储,将其挂在到本地使用,对外提供服务。
逻辑层,首先有一些本地I/O的底层驱动,还有和数据库访问的驱动封装,其他的就是网盘的核心部分,包括用户认证,上传下载文件,数据封装等等。
最表层的是应用接口层,主要是通过API来调用逻辑层的实现,从而可以使用到网盘。
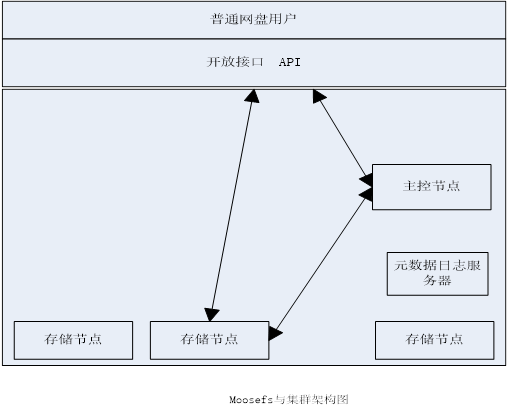
图 4.3.1 Moosefs集群架构图
网盘的架构图,本文采用的是MVC架构模型。
View:主要是通过jsp 和servlet来进行展现,主要是用于和API进行交互
Control:主要是自己进行写逻辑,DAO是主要是实现简易的与mysql进行通讯的,而FSDriver主要是封装了很多常用的访问文件系统的接口
Model:主要使用的JavaBean。
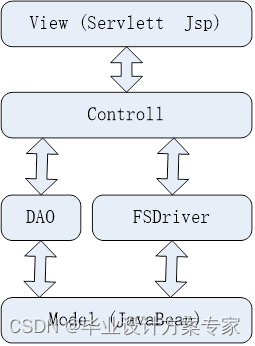
图4.3.2 网盘系统架构图
4.4 数据表结构
用户注册的实现中,我们采取的是简单的认证体制,我们建立一个数据库表。
我们当获取了规定用户的密码必须上传为SHA1,不能上传明文默认是以ID为主键,而且ID可以自己增长,不需要有默认值,用户名默认不支持中文,优先使用英文,关于密码,我们将密码进行了SHA1加密,当获得了密码后立刻进行SHA1加密,故系统本身不知道密码,从而保证用户的隐私,UserKey,是用于存储用户访问令牌,通过这个和表UserKey表进行关联,从而获取用户的访问令牌,保证用户同时可以拥有多个访问令牌。
User Table
名称 类型 长度 是否允许空值 默认值 是否是主键 说明
ID Int 64 否 否 是 编号
UserName Char 40 否 Null 否 用户名
Password Char 60 否 Null 否 密码
Sex Char 10 否 男 否 性别
UserKey Char 60 否 Null 否 访问的令牌
对于开发者,我们创建了另外一个表来存储信息,ID是表的主键,用于区别不同的开发者,而且不需要有是否有空,AppKey 用于当开发者申请开发者身份的时候获取的唯一绝对的认证,可以通过这个AppKey来确定一个开发者,AppSecret,主要使用Aouth认证的时候,通过AppSecret获得唯一的认证的临时令牌。
Developer Table
名称 类型 长度 是否允许空值 默认值 是否是主键 说明
ID Int 64 否 否 是 编号
UserName char 40 否 Null 否 用户名
Password Char 60 否 Null 否 密码
Sex Char 10 否 男 否 性别
AppKey Char 60 否 Null 否 应用的key
AppSecret Char 60 否 Null 否 应用的密码
为了保证多个开发者可以为同一个用户服务,而创建的这个表,其中存储的主要是用户的授权UserKey 和AppKey的对应关系。
User Table
名称 类型 长度 是否允许空值 默认值 是否是主键 说明
ID Int 64 否 否 是 编号
UserName char 40 否 Null 否 用户名
UserKey Char 60 否 Null 否 用户令牌
AppKey Char 60 否 Null 否 应用的key
4.5 核心代码实现
上传功能上,我们采用的是FileUpload这个开源库,FileUpload 是 Apache commons下面的一个子项目,用来实现Java环境下面的文件上传功能。它可以支持上传一个或者是多个文件,并且支持控制缓存空间的控制,可以手动的控制缓存的位置,是在硬盘或者是内存都是可以实现的。还可以限制上传文件的大小。支持RFC 1867标准。而且API简单易学。下面是使用FileUpload的核心代码,实现以下功能,包括进行文件类型过略,上传文件列表,设置缓存,进行目录检测,设置响应体格式等等工作。当上传成功后,将会生成上传日志,并将上传的日志展示给用户,让用户知道自己上传成功。


删除文件功能,即删除用户对应的文件或者目录,删除完成后,返回是否删除成功。代码首先判断文件是否存在,之后判断文件权限是否允许,最后才决定是否删除,删除后会有返回信息产生。
以下是删除文件的核心代码:

获取文件信息,当用户想知道自己某个目录的信息的时候,可以调用此接口,它将获取目录的信息,进行过滤加工,将信息封装为xml返回给用户。
我主要是用的是一个javax中原生的xml库,来生成xml,生成了xml之后,再将xml发送给用户。
首先我获取文件的相关信息,把它们通过正则表达式来进行切割,分到不同的数组中,之后利用javax.xml下面的类来进行生成xml
下面是关键代码:
通过系统调用,获取对应的文件目录信息,保存在对象之中

以下是生成xml的核心代码

5
测试用例
由于我做的主要是开放接口,故测试程序写的比较简陋。
5.1 用户认证
以下是用户认证功能测试
需要以下信息 用户名 密码 以及用户授权的key_number
首先,开发者通过引导用户到系统的授权页面,如下
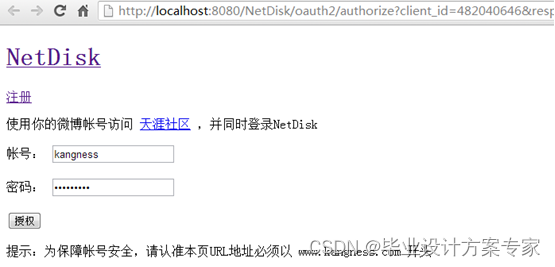
图 5.1.1 用户授权界面
当用户授权后,若用户通过验证,则提示用户是否授权,如下图5.1.3 所示,其中,里面包含了许多的信息,比如你的用户名,你网盘里面的部分照片,开者者将获取的权限等等信息都会显示出来。若认证失败,则出现如下图 5.1.2所示

图 5.1.2 认证失败
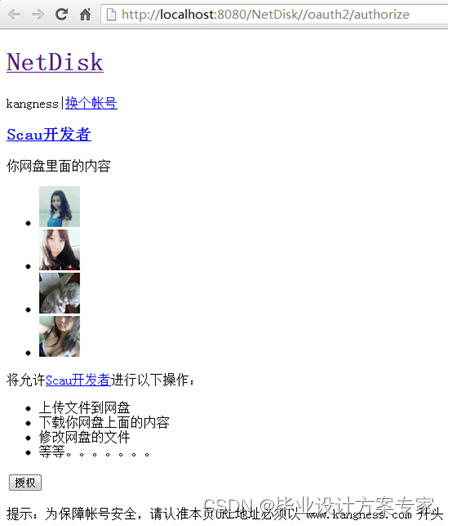
图 5.1.3 认证成功
若认证成功则提供一串授权码,但必须是开发者去访问系统,则能得到一个授权码,也就是我们所说的令牌,如下图 5.1.4所示

图 5.1.4 获取UserKey
经过测试 结果正确
5.2 上传下载
上传文件功能测试:
上传文件,只能上传指定类型的文件,如MP3,jpg等等
这是没有上传前,存储目录的情况 ,如下图 5.2.1 所示
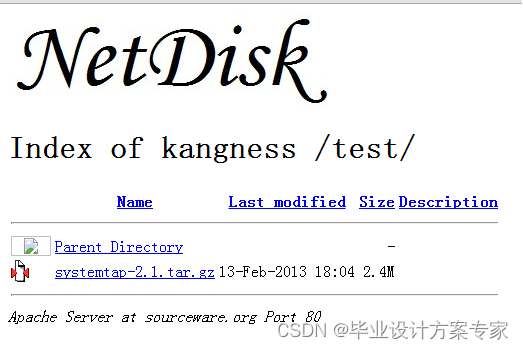
图 5.2.1 未上传情况
首先我们测试上传一张图片,如图 5.2.2所示

图 5.2.2 上传图片
上传后,网盘目录信息如图5.2.3所示可见,网盘是可以实现上传图片等功能,可以上传到指定的目录之中,而且可以获得文件的大小,修改时间,文件类型等内容。
现在测试上传失败,上传一个vsd的绘图文件,来进行测试,结果如图所示,当我们上传文件时,如图 5.2.4所示,当上传之后,由于失败的到的结果是如图5.2.5 所示,显示上传失败,之后我们在查看目录信息,如图5.2.6所示,依旧是没有添加,据此,我们可以得到网盘实现了过略文件类型的功能。
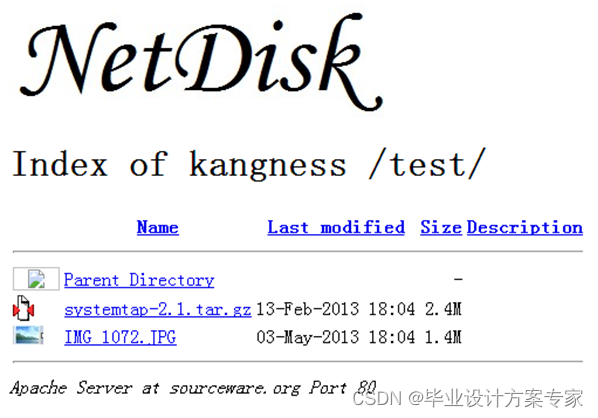
图 5.2.3 上传图片后的情况

图 5.2.4 上传vsd文件
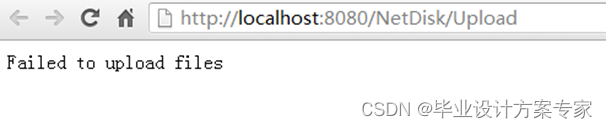
图 5.2.5 上传失败
现在我们查看目录的信息,可以看到,目录中没有添加到刚才上传文件的任何信息,和刚才一样,所以可以据此判断,网盘具有拒绝指定类型的文件上传的功能。
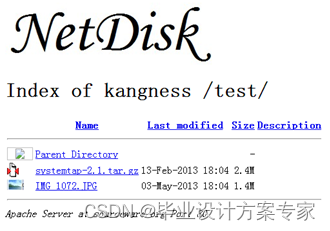
图 5.2.6 上传失败后目录
上传失败,和预期一样,所以网盘实现了拒绝指定文件类型的功能。符合要求。
5.3 获取目录信息
现在测试显示目录信息的接口,若访问,则显示目录的信息,如下图5.3.1 所示
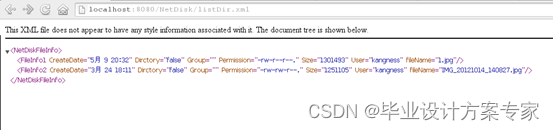
图 5.3.1 目录信息xml
如图所示,可以获取目录的相关信息,并生成对应的xml文件,其中包含了文件名称,大小,权限,时间等信息,符合要求。
5.4 数据恢复功能
现在测试数据恢复功能,首先删除刚才上传的图片,在回收站中,会有如下页面,如图 5.4.1所示

图 5.4.1 回收站信息
当选中需要恢复的文件后,单击恢复按钮,就能恢复。之后查看目录的信息,如下图5.4.2 所示,所以由此可见,网盘具有删除恢复功能。
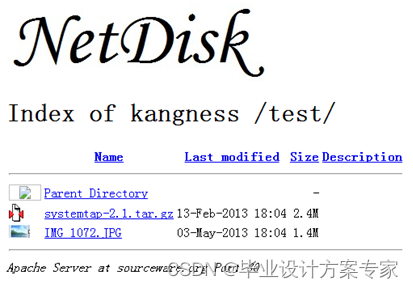
图5.4.2 删除恢复后目录信息
6 总结与展望
6.1 总结
在这次毕业设计中也使我们的同学关系更进一步了,同学之间互相帮助,有什么不懂的大家在一起商量,听听不同的看法对我们更好的理解知识,所以在这里非常感谢帮助我的同学。
我的心得也就这么多了,总之,不管学会的还是学不会的的确觉得困难比较多,真是万事开头难,不知道如何入手。最后终于做完了有种如释重负的感觉。此外,还得出一个结论:知识必须通过应用才能实现其价值!有些东西以为学会了,但真正到用的时候才发现是两回事,所以我认为只有到真正会用的时候才是真的学会了。
在此要感谢我的指导老师对我悉心的指导,感谢老师给我的帮助。在设计过程中,我通过查阅大量有关资料,与同学交流经验和自学,并向老师请教等方式,使自己学到了不少知识,也经历了不少艰辛,但收获同样巨大。在整个设计中我懂得了许多东西,也培养了我独立工作的能力,树立了对自己工作能力的信心,相信会对今后的学习工作生活有非常重要的影响。而且大大提高了动手的能力,使我充分体会到了在创造过程中探索的艰难和成功时的喜悦。虽然这个设计做的也不太好,但是在设计过程中所学到的东西是这次毕业设计的最大收获和财富,使我终身受益。
6.2 展望
大数据和分布式存储,是将来互联网发展所必须的,现在,微软对它旗下的Skydirver进行了全面的升级,国内的金山,有道,坚果等网盘巨头,都对自己的网盘进行了升级,可以相信,将来网盘将变成一种必须的工具,他方便访问,随时读取,没有地域的限制。所以,我相信,网盘和分布式将会大行其道。分布式的存储,将更加的流行,未来是大数据的时代,分布式能够很好的解决这个问题。
参 考 文 献
董黎刚.分布式系统中的调度与缓存技术[M] .浙江工商大学出版社,2010
明日科技编著. JSP开发技术大全[M]. 人民邮电出版社,2007
麻志毅.面向对象分析与设计[M]. 机械工业出版社,2008
陆嘉桓. Hadoop实战[M]. 机械工业出版社,2012
刘振安,董兰芳. 面向对象技术与UML. 北京: 机械工业出版社,2007
张晓东. Java 数据库高级教程[M]. 北京: 清华大学出版社, 2004
周忠,吴威. 分布式虚拟环境[M],科学出版社
刘军. 文件系统原理,机械工业出版社,2005
淘宝核心技术. 淘宝文件系统[EB/OL] 2013 http://tfs.taobao.org/index.html
George Coulouris .分布式系统概念与设计[M].机械工业出版社,2013
Amand Rajarman,Jeffrey David Ullman Mining of Massive Datasets[M],人民邮电出版社
Michat Borgchowski . Installing Moosefs Step by Tutorial[EB/OL] Gemius SA 2010 http://www.moosefs.org/tl_files/manpageszip/moosefs-step-by-step-tutorial-cn-v.1.1.pdf
致 谢
省略
5、资源下载
本项目源码及完整论文如下,有需要的朋友可以点击进行下载。如果链接失效可点击下方卡片扫码自助下载。
| 序号 | 毕业设计全套资源(点击下载) |
|---|---|
| 本项目源码 | 基于Java+Moosefs的分布式文件系统设计与实现(源码+文档)_Java_分布式文件系统.zip |
6、更多JAVA毕业设计项目
精选JAVA毕业设计83套——源码+论文完整资源
这篇关于java毕业设计——基于Java+Moosefs的分布式文件系统设计与实现(毕业论文+程序源码)——分布式文件系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






