本文主要是介绍mysql事务在提交后才发送给数据库执行_mysql事务隔离级别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1,mysql的主从复制
主从复制概念:是指数据可以从一个mysql数据库服务器主节点复制到一个或者多个从节点.mysql默认采用异步复制的方式.
主从复制的主要用途:1)读写分离:在实际开发中,如果遇见某sql语句需要锁表,导致暂时不能使用读服务,这样会影响现有业务,这种情况下使用主从复制,让主数据库负责写,从数据库负责读,这样可以保证业务正常运作 2)数据实时备份:当系统中某个节点发生故障时,可以方便的故障切换 3)高可用HA 4)架构扩展:随着系统业务访问量增大,单机部署数据库可能会有I/O访问频率过高问题.有了主从复制,增加多个数据存储节点,将敷在分布在多个从节点上,降低单机磁盘I/O访问频率,提高单机的I/O性能
mysql主从形式: 1)一主一从 2)一主多从 3)多主一从(将多个数据库备份到一台存储性能比较好的服务器上) 4)双主复制 5)级联复制:级联复制模式下,部分slave的数据同步不连接主节点,而是连接从节点。因为如果主节点有太多的从节点,就会 损耗一部分性能用于replication,那么我们可以让3~5个从节点连接主节点,其它从节点作为二级或者三级与从节点连接,这样不仅可以缓解主节点 的压力,并且对数据一致性没有负面影响
mysql主从复制原理:涉及三个线程,一个运行在主节点(log dump thread),其余两个(I/O thread,SQL thread)运行在从节点
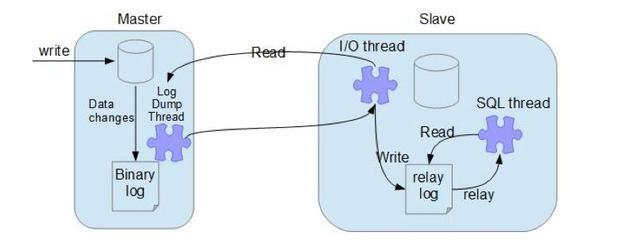
log dump thread:当从节点连接主节点时,主节点会创建一个log gump线程,用于发送bin-log的内容.在读取bin-log中的操作时,log-dump thread会对主节点上的bin-log加锁,当读取完成,甚至在发送给从节点之前,锁会被释放.
I/O thread:当从节点上执行 "start slave"命令后,从节点会创建一个I/O线程用来连接主节点,请求主库中更新的bin-log。I/O线程接收到主节点binlog dump 进程发来的更新之后,保存在本地relay-log中。
SQL thread:SQL线程负责读取relay log中的内容,解析成具体的操作并执行,最终保证主从数据的一致性
当主节点有多个从节点时,主节点会为每一个当前连接的从节点建一个binary log dump 进程,而每个从节点都有自己的I/O进程,SQL进程。从节点用两个线程将从主库拉取更新和执行分成独立的任务,这样在执行同步数据任务的时候,不会降低 读操作的性能。比如,如果从节点没有运行,此时I/O进程可以很快从主节点获取更新,尽管SQL进程还没有执行。如果在SQL进程执行之前从节点服务停 止,至少I/O进程已经从主节点拉取到了最新的变更并且保存在本地relay日志中,当服务再次起来之后,就可以完成数据的同步
复制的基本过程如下:
从节点上的I/O 进程连接主节点,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;主 节点接收到来自从节点的I/O请求后,通过负责复制的I/O进程根据请求信息读取指定日志指定位置之后的日志信息,返回给从节点。返回信息中除了日志所包 含的信息之外,还包括本次返回的信息的bin-log file 的以及bin-log position;从节点的I/O进程接收到内容后,将接收到的日志内容更新到本机的relay log中,并将读取到的binary log文件名和位置保存到master-info 文件中,以便在下一次读取的时候能够清楚的告诉Master“我需要从某个bin-log 的哪个位置开始往后的日志内容,请发给我”;Slave 的 SQL线程检测到relay-log 中新增加了内容后,会将relay-log的内容解析成在祝节点上实际执行过的操作,并在本数据库中执行。
mysql主从复制模式:MySQL 主从复制默认是异步的模式。MySQL增删改操作会全部记录在binary log中,当slave节点连接master时,会主动从master处获取最新的bin log文件。并把bin log中的sql relay
1)异步模式:这种模式下,主节点不会主动push bin log到从节点,这样有可能导致failover的情况下,也许从节点没有即时地将最新的bin log同步到本地。
2)半同步模式:这种模式下主节点只需要接收到其中一台从节点的返回信息,就会commit;否则需要等待直到超时时间然后切换 成异步模式再提交;这样做的目的可以使主从数据库的数据延迟缩小,可以提高数据安全性,确保了事务提交后,binlog至少传输到了一个从节点上,不能保 证从节点将此事务更新到db中。性能上会有一定的降低,响应时间会变长
3)全同步模式:全同步模式是指主节点和从节点全部执行了commit并确认才会向客户端返回成功
bin-log记录格式:MySQL 主从复制有三种方式:基于SQL语句的复制(statement-based replication,SBR),基于行的复制(row-based replication,RBR),混合模式复制(mixed-based replication,MBR)。对应的binlog文件的格式也有三种:STATEMENT,ROW,MIXED I:Statement-base Replication (SBR)就是记录sql语句在bin log中,Mysql 5.1.4 及之前的版本都是使用的这种复制格式。优点是只需要记录会修改数据的sql语句到binlog中,减少了binlog日质量,节约I/O,提高性能。缺点 是在某些情况下,会导致主从节点中数据不一致(比如sleep(),now()等) II:Row-based Relication(RBR)是mysql master将SQL语句分解为基于Row更改的语句并记录在bin log中,也就是只记录哪条数据被修改了,修改成什么样。优点是不会出现某些特定情况下的存储过程、或者函数、或者trigger的调用或者触发无法被正 确复制的问题。缺点是会产生大量的日志,尤其是修改table的时候会让日志暴增,同时增加bin log同步时间。也不能通过bin log解析获取执行过的sql语句,只能看到发生的data变更。III:Mixed-format Replication(MBR),MySQL NDB cluster 7.3 和7.4 使用的MBR。是以上两种模式的混合,对于一般的复制使用STATEMENT模式保存到binlog,对于STATEMENT模式无法复制的操作则使用 ROW模式来保存,MySQL会根据执行的SQL语句选择日志保存方式。
GTID复制模式:1)在传统的复制里面,当发生故障,需要主从切换,需要找到binlog和pos点,然后将主节点指向新的主节点,相对来说比较麻烦,也容易出错。在 MySQL 5.6里面,不用再找binlog和pos点,我们只需要知道主节点的ip,端口,以及账号密码就行,因为复制是自动的,MySQL会通过内部机制 GTID自动找点同步。2)多线程复制(基于库),在MySQL 5.6以前的版本,slave的复制是单线程的。一个事件一个事件的读取应用。而master是并发写入的,所以延时是避免不了的。唯一有效的方法是把多 个库放在多台slave,这样又有点浪费服务器。在MySQL 5.6里面,我们可以把多个表放在多个库,这样就可以使用多线程复制。
基于GTID复制实现的工作原理:主节点更新数据时,会在事务前产生GTID,一起记录到binlog日志中。从节点的I/O线程将变更的bin log,写入到本地的relay log中。SQL线程从relay log中获取GTID,然后对比本地binlog是否有记录(所以MySQL从节点必须要开启binary log)。如果有记录,说明该GTID的事务已经执行,从节点会忽略。如果没有记录,从节点就会从relay log中执行该GTID的事务,并记录到bin log。在解析过程中会判断是否有主键,如果没有就用二级索引,如果有就用全部扫描。
2,mysql四种事务隔离级别
1)未提交读:允许脏读,即可能读到其他会话中未提交事务修改的数据
2)提交读:oracle等多数数据库默认级别,该级别存在不可重复读和幻读问题
3)可重复读:mysql默认隔离级别,该级别消除了不可重复读,但还是存在幻读
4)每次读都需要获得表级共享锁,读写会相互阻塞
脏读:脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据
不可重复读:一个事务内,多次读同一个数据,在这个事务还没有结束时,另外一个事务也访问该同一数据,那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,导致第一个事务前后读到的数据可能不一样.这样一个事务内两次读到的数据不一样,因此称为不可重复读
幻读:第一个事务对一个表中的数据进行修改,这种修改设计表中的全部数据行.同时,第二个事务也修改这个表中数据,这种修改是向表中插入一行新数据,那么,对于第一个事务而言就会发现表中还有没有修改的数据行,这种情况称为幻读.当隔离级别是可重复读,且禁用innodb_locks_unsafe_for_binlog的情况下,在搜索和扫描index的时候使用的next-key locks可以避免幻读。
四种级别逐渐增加,事务级别越高,性能越差.大多数互联网项目中用的提交读这个隔离级别
然后,mysql为什么选择可重复读作为默认级别而不是像oracle和sqlServer选择读已提交???
mysql的主从复制是基于binlog复制的.binlog有三中格式:1)statement 记录修改的sql语句 2)row 记录的是每行实际数据的变更 3)mixed statement和 row 模式的混合 mysql5.0版本以前,binlog只支持statement格式,这种格式在提交读隔离级别下主从复制存在bug,因此mysql将可重复读作为默认隔离级别.
然后,当binlog为statement格式,隔离级别为提交读时,有什么bug呢?假设在主机上执行如下事务
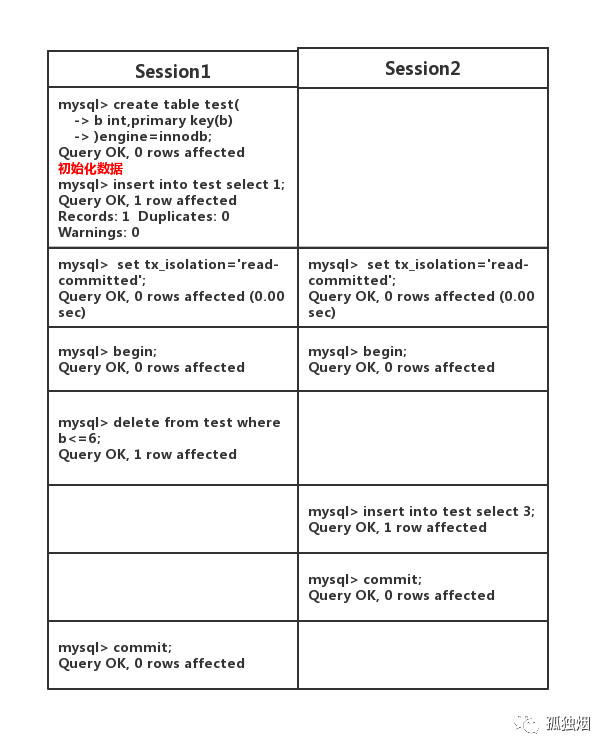
此时在主(master)上执行下列语句
select * from test;
输出如下
+---+
| b |
+---+
| 3 |
+---+
1 row in set
但是,你在此时在从(slave)上执行该语句,得出输出如下
Empty set
这样,你就出现了主从不一致性的问题!原因其实很简单,就是在master上执行的顺序为先删后插!而此时binlog为STATEMENT格式,它记录的顺序为先插后删!从(slave)同步的是binglog,因此从机执行的顺序和主机不一致!就会出现主从不一致!
如何解决?
解决方案有两种!
(1)隔离级别设为可重复读(Repeatable Read),在该隔离级别下引入间隙锁。当Session 1执行delete语句时,会锁住间隙。那么,Ssession 2执行插入语句就会阻塞住!
(2)将binglog的格式修改为row格式,此时是基于行的复制,自然就不会出现sql执行顺序不一样的问题!奈何这个格式在mysql5.1版本开始才引入。因此由于历史原因,mysql将默认的隔离级别设为可重复读(Repeatable Read),保证主从复制不出问题!
那么,当我们了解完mysql选可重复读(Repeatable Read)作为默认隔离级别的原因后,接下来我们将其和读已提交(Read Commited)进行对比,来说明为什么在互联网项目为什么将隔离级别设为读已提交(Read Commited)!
对比
ok,我们先明白一点!项目中是不用读未提交(Read UnCommitted)和串行化(Serializable)两个隔离级别,原因有二
采用读未提交(Read UnCommitted),一个事务读到另一个事务未提交读数据,这个不用多说吧,从逻辑上都说不过去!
采用串行化(Serializable),每个次读操作都会加锁,快照读失效,一般是使用mysql自带分布式事务功能时才使用该隔离级别!(笔者从未用过mysql自带的这个功能,因为这是XA事务,是强一致性事务,性能不佳!互联网的分布式方案,多采用最终一致性的事务解决方案!)
也就是说,我们该纠结都只有一个问题,究竟隔离级别是用读已经提交呢还是可重复读?
接下来对这两种级别进行对比,讲讲我们为什么选读已提交(Read Commited)作为事务隔离级别!
假设表结构如下
CREATE TABLE `test` (
`id` int(11) NOT NULL,
`color` varchar(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB
数据如下
+----+-------+
| id | color |
+----+-------+
| 1 | red |
| 2 | white |
| 5 | red |
| 7 | white |
+----+-------+
为了便于描述,下面将
可重复读(Repeatable Read),简称为RR;
读已提交(Read Commited),简称为RC;
缘由一:在RR隔离级别下,存在间隙锁,导致出现死锁的几率比RC大的多!
此时执行语句
select * from test where id <3 for update;
在RR隔离级别下,存在间隙锁,可以锁住(2,5)这个间隙,防止其他事务插入数据!
而在RC隔离级别下,不存在间隙锁,其他事务是可以插入数据!
ps:在RC隔离级别下并不是不会出现死锁,只是出现几率比RR低而已!
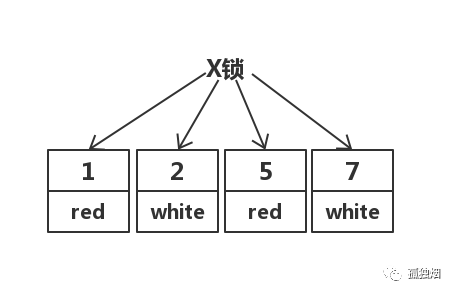
缘由二:在RR隔离级别下,条件列未命中索引会锁表!而在RC隔离级别下,只锁行
此时执行语句
update test set color = 'blue' where color = 'red';
在RC隔离级别下,其先走聚簇索引,进行全部扫描。加锁如下:
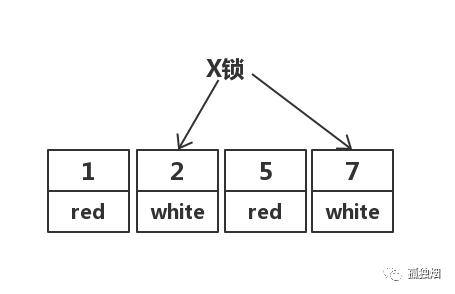
但在实际中,MySQL做了优化,在MySQL Server过滤条件,发现不满足后,会调用unlock_row方法,把不满足条件的记录放锁。
实际加锁如下
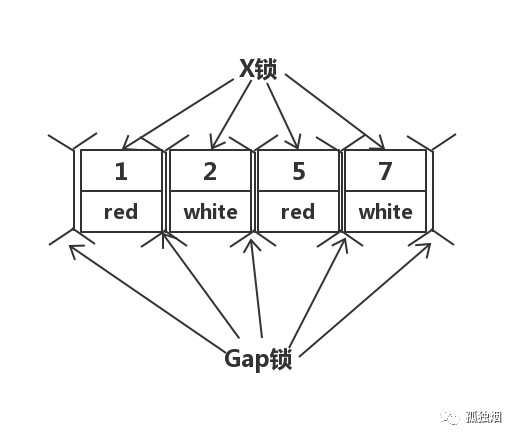
然而,在RR隔离级别下,走聚簇索引,进行全部扫描,最后会将整个表锁上,如下所示
缘由三:在RC隔离级别下,半一致性读(semi-consistent)特性增加了update操作的并发性!
在5.1.15的时候,innodb引入了一个概念叫做“semi-consistent”,减少了更新同一行记录时的冲突,减少锁等待。
所 谓半一致性读就是,一个update语句,如果读到一行已经加锁的记录,此时InnoDB返回记录最近提交的版本,由MySQL上层判断此版本是否满足 update的where条件。若满足(需要更新),则MySQL会重新发起一次读操作,此时会读取行的最新版本(并加锁)!
具体表现如下:
此时有两个Session,Session1和Session2!
Session1执行
update test set color = 'blue' where color = 'red';
先不Commit事务!
与此同时Ssession2执行
update test set color = 'blue' where color = 'white';
session 2尝试加锁的时候,发现行上已经存在锁,InnoDB会开启semi-consistent read,返回最新的committed版本(1,red),(2,white),(5,red),(7,white)。MySQL会重新发起一次读操 作,此时会读取行的最新版本(并加锁)!
而在RR隔离级别下,Session2只能等待!
两个疑问
在RC级别下,不可重复读问题需要解决么?
不用解决,这个问题是可以接受的!毕竟你数据都已经提交了,读出来本身就没有太大问题!Oracle的默认隔离级别就是RC,你们改过Oracle的默认隔离级别么?
在RC级别下,主从复制用什么binlog格式?
OK,在该隔离级别下,用的binlog为row格式,是基于行的复制!Innodb的创始人也是建议binlog使用该格式!
这篇关于mysql事务在提交后才发送给数据库执行_mysql事务隔离级别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





