本文主要是介绍Course数字图像处理 Week2习题(Image and Video Processing: From Mars to Hollywood with a Stop at the Hospital),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Week2习题——Image and Video Processing: From Mars to Hollywood with a Stop at the Hospital
1.Suppose we have an image with 256 different gray levels. All the gray values appear an equal number of times.Will variable-length coding lead to any compression in this image without additional processing?
假设我们有一幅有256个不同灰度的图像。所有灰色值出现的次数相等。可变长度编码会导致在没有额外处理的情况下对图像进行压缩吗?
Yes
No
解释: 可变长度编码即Haffman Coding,主要对于出现灰度次数不同进行编码,出现次数最多的用较短的数字进行编码,而出现次数少的则用稍微长的进行编码,达到最好的压缩率,所有灰度值出现的次数相同,不进行处理,不可以进行压缩。
2.How can lossless image compression be achieved for the image in Question 1?
如何对问题1中的图像进行无损压缩?
A.Lossless compression will never be achieved for such image.
这种图像永远无法实现无损压缩
B.Via predictive coding.
通过预测编码
C.Erasing pixels.
擦除像素
D.Performing a DCT.
执行DCT(离散余弦变换)
3.How many unique sets of Huffman codes can you construct for an image with only 3 different pixel values (e.g., all the image is composed of 0s, 255s, and 128s)?
对于只有3个不同像素值的图像(例如,所有的图像都是由0、255和128组成的),你能构造多少个独特的霍夫曼编码集?
A.Infinity
B.3
C.2
D.5
0 10 11
解释: 三个不同的像素值编码集可以是1 00 01,或者 0 10 11,共两种
4.For an image with intensities 21, 95, 169 and 243; and respective probabilities 3/8, 1/8, 1/8, and 3/8; the length of the corresponding variable-length code created by the Huffman coding procedure are
对于强度为21,95,169和243的图像;以及各自的概率3/8,1/8,1/8,3/8;由霍夫曼编码过程创建的相应的变长代码的长度为
A.2, 2, 2, 2
B.1, 3, 3, 2
C.1, 4, 4, 1
D.1, 2, 2, 1
解释: 如图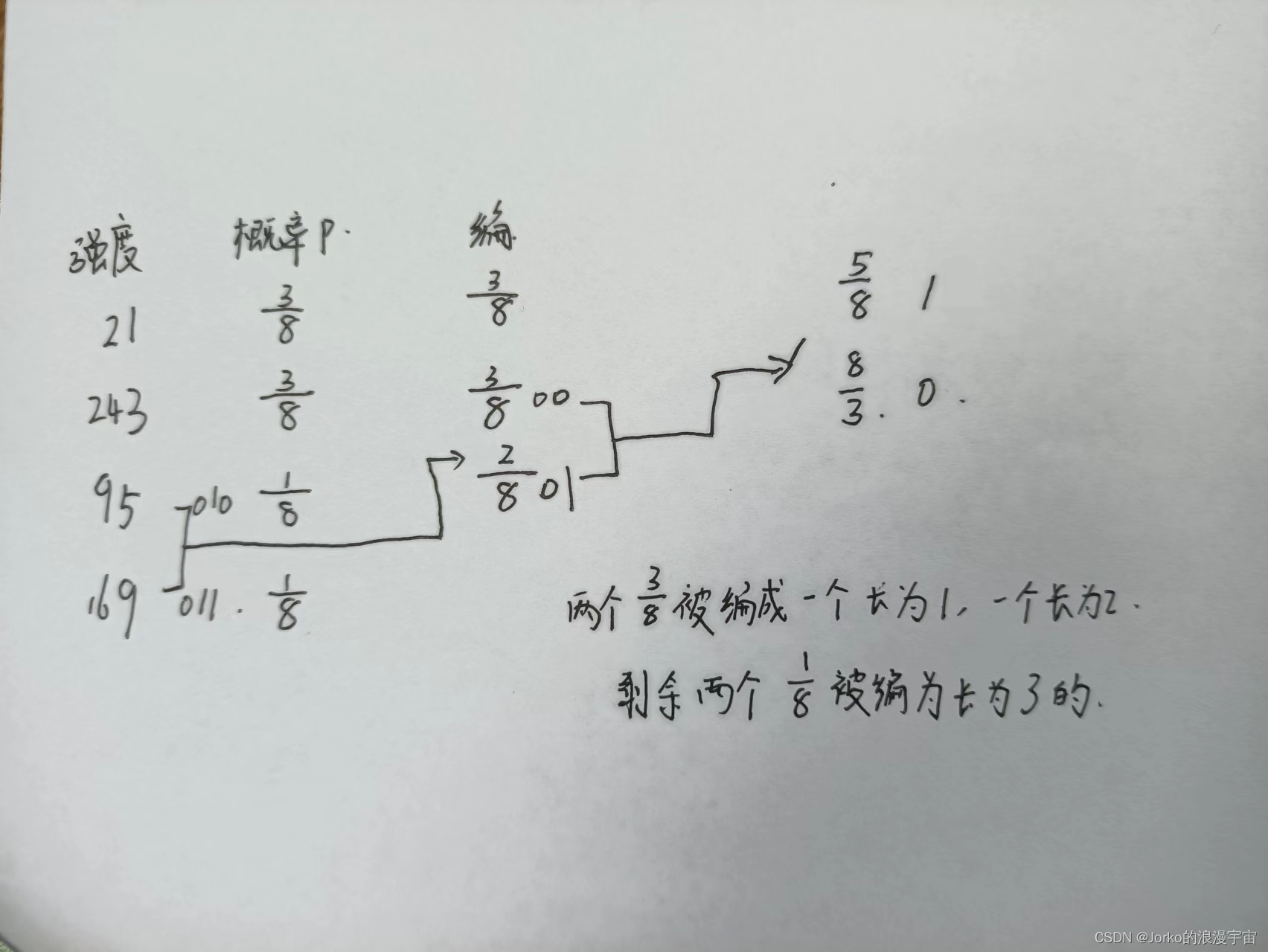
5.The main source of error (lossy compression) in JPEG is
JPEG格式的主要误差来源(有损压缩)是
The variable-length (Huffman) coding.
The division into 8x8 blocks.
The DCT.
The quantization.
解释: 量化的过程会产生误差,在量化器中,被分为有限个灰度值,进行处理
6.In lossless image compression, prediction can be based on any pixel in the image.
在无损图像压缩中,预测可以基于图像中的任何像素。
False
True
解释: 因为编码要和解码对应,所以解码的时候只能看到当前像素之前的灰度值,无法看到未来的,所以,编码阶段只能在前面灰度值已知情况来推断后面像素的情况
7.A reason for using DCT (instead of Fourier, for example) in JPEG is
在JEPG中没有使用傅里叶而是使用离散余弦变换的一个原因是
A.No particular reason
没有特殊原因
B.It is simpler to compute
它计算容易
C.Its favorable periodicity property
它更具有周期性
D.It is real while Fourier is complex
傅里叶变换是复数,DCT是实数
解释:
8.Since we must encode all pixels in the image, JPEG needs at least a bit per pixel and therefore in a 256 levels image (8 bits), it can only achieve up to 8:1 compression.
假设我们对图像的每个像素编码,JPEG需要至少每个像素使用1bit,因此在256个灰度级(8bits)图像中可以达到8:1的压缩率
True
False
解释:
9.In JPEG, if we double the quantization step, then we double the compression ratio.
在JPEG中,如果我们将量化矩阵使用两次处理,我们可以达到两倍的压缩率
True
False
解释:
10.Without JPEG or a similar compression technique, digital cameras will no be as popular as they are today.
没有JPEG或者简单的压缩技术,数码相机将不会像今天这么流行
True
False
这篇关于Course数字图像处理 Week2习题(Image and Video Processing: From Mars to Hollywood with a Stop at the Hospital)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







