本文主要是介绍[AI特训营第三期]基于PaddleSeg的衣物分割,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>

一、项目背景
语义分割是计算机视觉的主要任务之一。它是将图像像素化为对象类的分类。此数据集包含 1000 张图像和分割蒙版,用于个人服装。由于有 59 个对象类和相对较少的数据,建模任务预计将是一项具有挑战性的任务!数据不需要预处理,所有图像的大小、格式相同,可以建模。
二、项目任务说明
对某些衣服进行分割,并且miou要达到0.66以上
三、数据说明
数据集包含 1000 张图像和 1000 个相应的语义分割掩码,每个掩码的大小为 825 x 550 像素,采用 PNG 格式。分割面具属于59类,第一类是个人的背景,其余属于衬衫、头发、裤子、皮肤、鞋子、眼镜等58类服装类。数据集中包含包含 59 个类列表的 CSV 文件。数据集包含 JPEG 格式和 PNG 格式的数据。但是,JPEG被发现是有损的,而PNG是无损的,具有原创性的本质。
数据集下载源地址:下载地址
下面展示数据集中的部分图片以及其分割标签
%matplotlib inline
from PIL import Image
import numpy as np
import os
from os import listdir
import cv2
import random
import seaborn as sns
import matplotlib.pyplot as plt
from PIL import Image
from tqdm import tqdm
#建立文件夹
!mkdir segdata
#解压数据集
!unzip data/data186956/archive.zip -d segdata
数据可视化
TRAIN = 'segdata/png_images/IMAGES'
# TEST = '/home/aistudio/data/data131069/cow/images'train = os.listdir(TRAIN)
# test = os.listdir(TEST)f, axs = plt.subplots(4,5, figsize=(16,8))
for i in range(4):for j in range(5):axs[i][j].imshow(cv2.cvtColor(cv2.imread(os.path.join(TRAIN, train[random.randint(0,len(train)-1)]), cv2.IMREAD_UNCHANGED), cv2.COLOR_BGR2RGB));
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V2rO8FxK-1681632685130)(main_files/main_10_0.png)]
mask展示
MASK = 'segdata/png_masks/MASKS'
mask_path_plt = os.listdir(MASK)f, axs = plt.subplots(4,5, figsize=(16,8))
for i in range(4):for j in range(5):axs[i][j].imshow(cv2.imread(os.path.join(MASK, mask_path_plt[random.randint(0,len(mask_path_plt)-1)]), cv2.IMREAD_GRAYSCALE))
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2pHtvpwu-1681632685131)(main_files/main_12_0.png)]
四、代码实现
!pip install paddleseg
#解压paddleSeg
!git clone https://gitee.com/PaddlePaddle/PaddleSeg.git
数据可视化
plt.rcParams["figure.figsize"] = (7, 7)
plt.rcParams["font.size"] = 7
dd = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38,\39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 51, 52, 53, 54, 55, 56, 57, 58, 59]
labels = ['nan', 'accessories', 'bag', 'belt', 'blazer', 'blouse', 'bodysuit', 'boots', 'bra', 'bracelet', 'cape', 'cardigan', 'clogs', 'coat', 'dress', \
'earrings', 'flats', 'glasses', 'gloves', 'hair', 'hat', 'heels', 'hoodie', 'intimate', 'jacket', 'jeans', 'jumper', 'leggings', 'loafers', 'necklace', 'panties',\'pants', 'pumps', 'purse', 'ring', 'romper', 'sandals', 'scarf', 'shirt', 'shoes', 'shorts', 'skin', 'skirt', 'sneakers', 'socks', 'stockings', 'suit', 'sunglasses', \'sweater', 'sweatshirt', 'swimwear', 't-shirt', 'tie', 'tights', 'top', 'vest', 'wallet', 'watch', 'wedges']counts = [0]*len(dd)files = listdir("segdata/png_masks/MASKS/")for file in files:if file != ".ipynb_checkpoints":im = cv2.imread("segdata/png_masks/MASKS/"+file)im_s = np.unique(im)for k in range(0, len(im_s)):counts[dd.index(im_s[k])] += 1temp = []for k in range(0, len(counts)):temp.append((counts[k], labels[k]))
temp_ = temp.copy()
temp.sort(key=lambda xx: xx[0], reverse=False)for k in range(0, len(temp)):counts[k] = temp[k][0]labels[k] = temp[k][1]
plt.title("Total number of pixels by label")
plt.plot(counts, labels, linewidth=2, marker="o")
plt.fill_between(counts, labels, color="#d9d9d9")
plt.xlabel("Count")
plt.xlabel("Label")
plt.grid(linestyle="--")
plt.show()[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SGENBKzb-1681632685132)(main_files/main_17_0.png)]
划分数据集
label_new = []
multi_dd = []
unuseful_dd = []
for i in range(len(temp_)):if temp_[i][0]>250:label_new.append([temp_[i][0],temp_[i][1],i])multi_dd.append(i)else:unuseful_dd.append(i)
multi_dd
new_dd = [x for x in range(len(multi_dd))]
new_dd
#由于数据集不平衡,我们只选取数据量大于200的类别
#先读取mask,把无关的类别都置为0
seg_path = 'segdata/png_masks/MASKS'
for item in os.listdir(seg_path):if '.png' in item:mask = Image.open(os.path.join(seg_path,item))mask = np.array(mask)for i in unuseful_dd:mask[mask==i]=0mask = Image.fromarray(mask)mask.save(os.path.join(seg_path,item))
#读取mask
seg_path = 'segdata/png_masks/MASKS'
for item in os.listdir(seg_path):if '.png' in item:mask = Image.open(os.path.join(seg_path,item))mask = np.array(mask)for i in multi_dd:mask[mask==i]=new_dd[multi_dd.index(i)]mask = Image.fromarray(mask)mask.save(os.path.join(seg_path,item))
#划分数据集
#由于png质量比较高,所以采用png数据集
!python PaddleSeg/tools/data/split_dataset_list.py \--split 0.9 0.1 0.0\segdata \png_images/IMAGES\png_masks/MASKS \--format png png
模型介绍
RTFormer
RTFormer提出了一种新的Transformer块,名为RTFormer块,如图所示,其目的是在具有Transformer的类似GPU的设备上实现性能和效率之间的更好平衡。对于低分辨率分支,采用了新提出的GPU Friendly Attention,该注意力源自External Attention。它继承了External Attention的线性复杂性特性,并通过丢弃矩阵乘法操作中的通道分裂,缓解了类GPU设备的多头机制的弱点。相反,它扩大了外部参数的数量,并将External Attention提出的双范数运算中的第二个归一化分解为多个组。这使得GPU Friendly Attention能够在一定程度上保持多头机制的优势。对于高分辨率分支,采用交叉分辨率注意力,而不是仅在高分辨率特征本身内进行注意力。此外,与多分辨率融合的并行公式不同,作者将两个分辨率分支排列成阶梯布局。因此,通过辅助从低分辨率分支中学习到的高级别全局上下文信息,可以更有效地增强高分辨率分支。
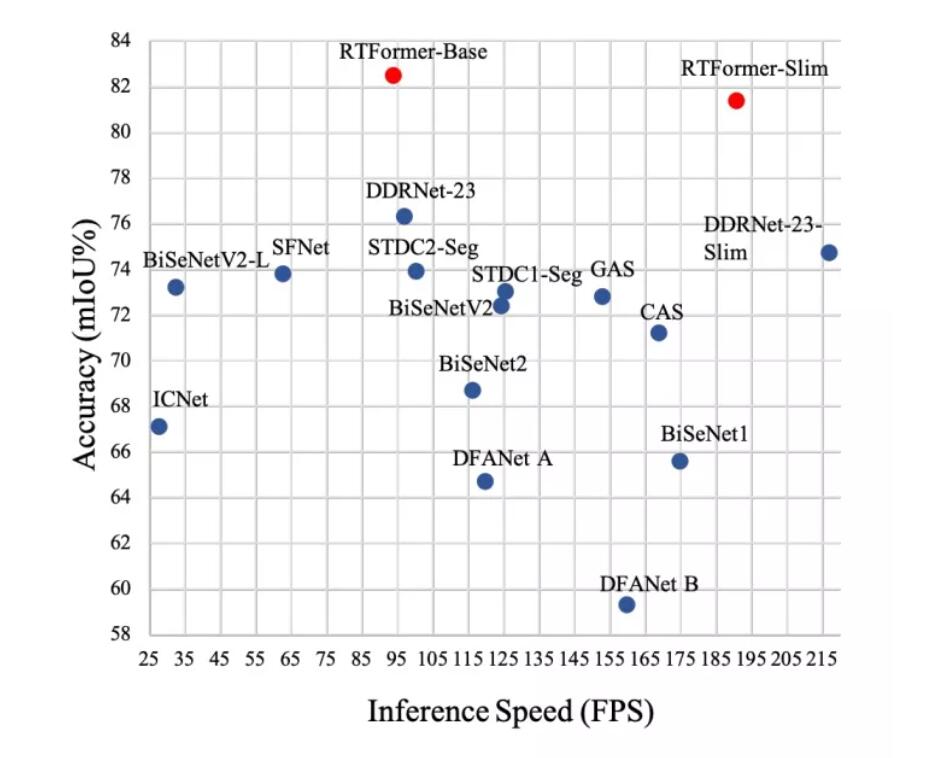
。
网络结构
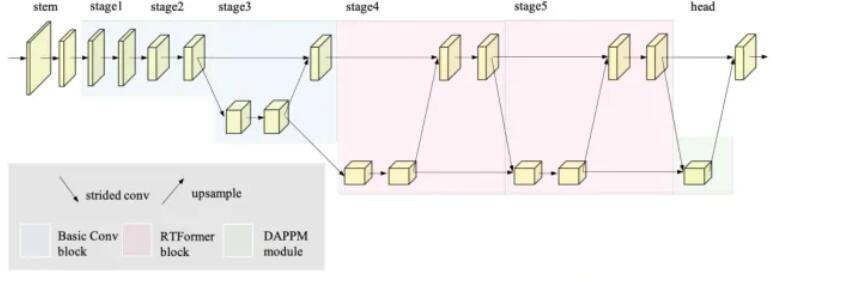
1、Backbone Architecture
为了提取高分辨率特征图所需的足够的局部信息,将卷积层与RTFormer块相结合来构造RTFormer。具体来说,让RTFormer从一个由两个3×3卷积层组成的干块开始,用几个连续的基本残差块组成前两个阶段。然后,从第3阶段开始,使用双分辨率模块,实现高分辨率和低分辨率分支之间的特征交换。对于最后三个阶段的高分辨率分支,特征stride保持为8不变,而对于低分辨率分支,则特征stride分别为16、32、32。特别是,将双分辨率模块安排为阶梯式布局,以借助低分辨率分支的输出增强高分辨率特征的语义表示。最重要的是,用提出的RTFormer块构造了stage4和stage5,如图2所示,用于有效的全局上下文建模,而stage3仍然由基本残差块组成。
2、Segmentation Head
对于RTFormer的分割头,在低分辨率输出特征之后添加了一个DAPPM模块。然后将DAPPM的输出与高分辨率特征融合,得到stride为8的输出特征图。最后,将该输出特征传递到像素级分类头,用于预测密集语义标签。分类头由3×3卷积层和1×1卷积层组成,隐藏特征维数与输入特征维数相同。
3、Instantiation
用RTFormer Slim和RTFormer Base实例化了RTFormer的架构,详细配置记录在表1中。对于通道数和块数,每个数组包含5个元素,分别对应于5个阶段。特别是,具有两个数字的元素对应于双分辨率级。例如,64/128表示通道数对于高分辨率分支为64,对于低分辨率分支为128。而1/2表示高分辨率分支的基本卷积块数为1,低分辨率分支为2
DeepLapV3+
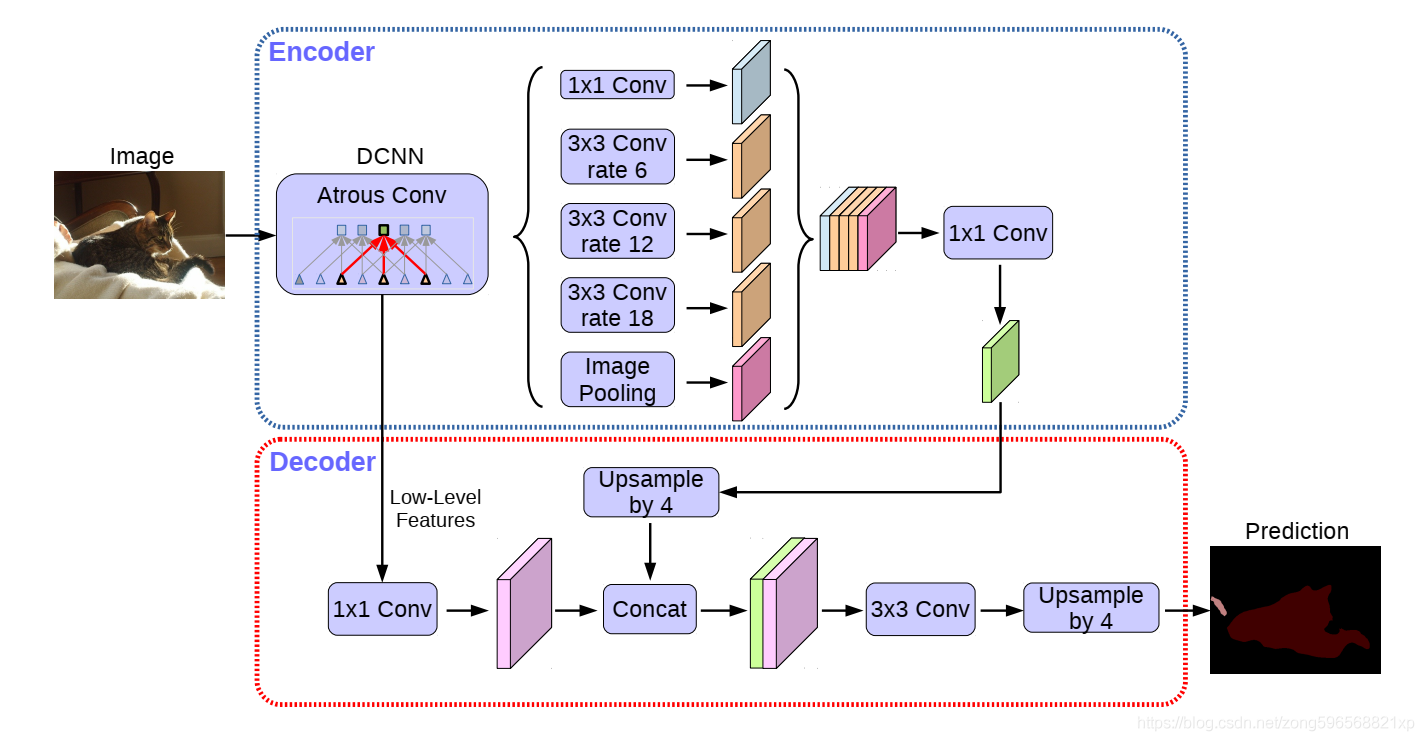
DeepLabv3+ 模型的整体架构如上图所示,它的 Encoder 的主体是带有空洞卷积的 DCNN,可以采用常用的分类网络如 ResNet,然后是带有空洞卷积的空间金字塔池化模块(Atrous Spatial Pyramid Pooling, ASPP)),主要是为了引入多尺度信息;相比DeepLabv3,v3+ 引入了 Decoder 模块,其将底层特征与高层特征进一步融合,提升分割边界准确度。从某种意义上看,DeepLabv3+ 在 DilatedFCN 基础上引入了 EcoderDecoder 的思路。
模型训练
#运行此处代码运行deeplapv3+,mou达到66%以上
!python PaddleSeg/train.py --config configs/deeplap+.yml \--do_eval \--save_dir log \--use_vdl \--iters 800\--save_interval 10\--log_iters 10 \--precision 'fp16'\
#取消注释,运行此处代码运行轻量级语义分割网络RTFormer,mou达到54.38%
# !python PaddleSeg/train.py --config configs/RTFormer.yml \
# --do_eval \
# --save_dir log \
# --use_vdl \
# --iters 800\
# --save_interval 10\
# --log_iters 10 \
# --precision 'fp16'\
模型评价
!python PaddleSeg/val.py --config configs/deeplap+.yml --model_path model/model.pdparams
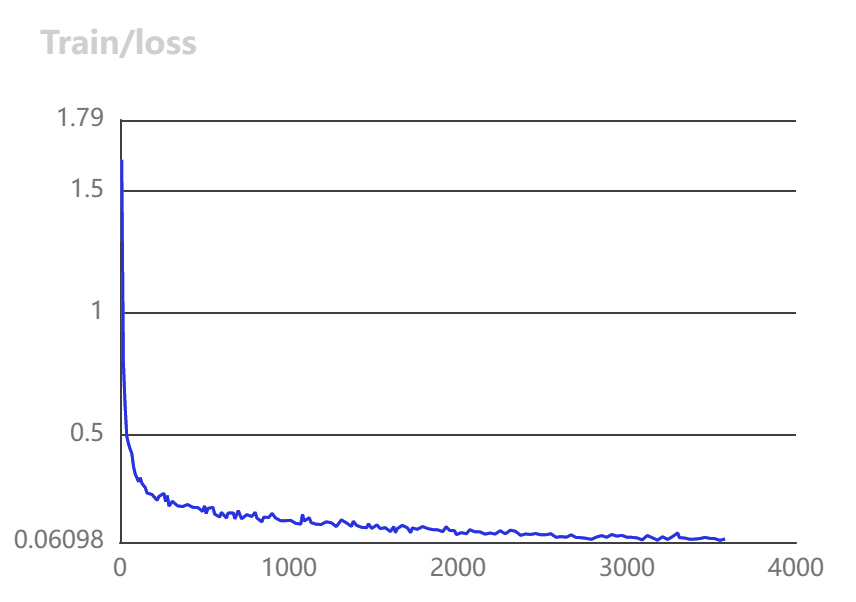
训练结果可视化
| Column 1 | Column 2 |
|---|---|
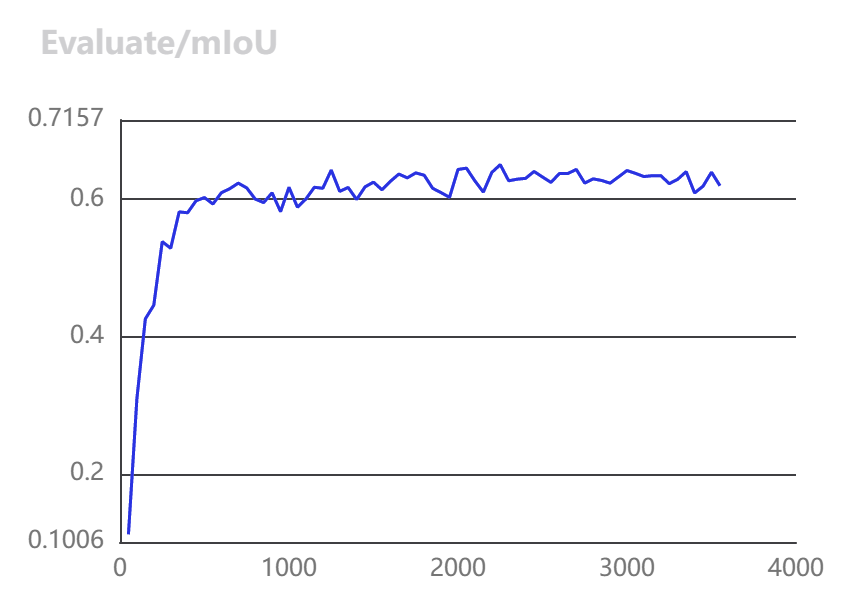 | 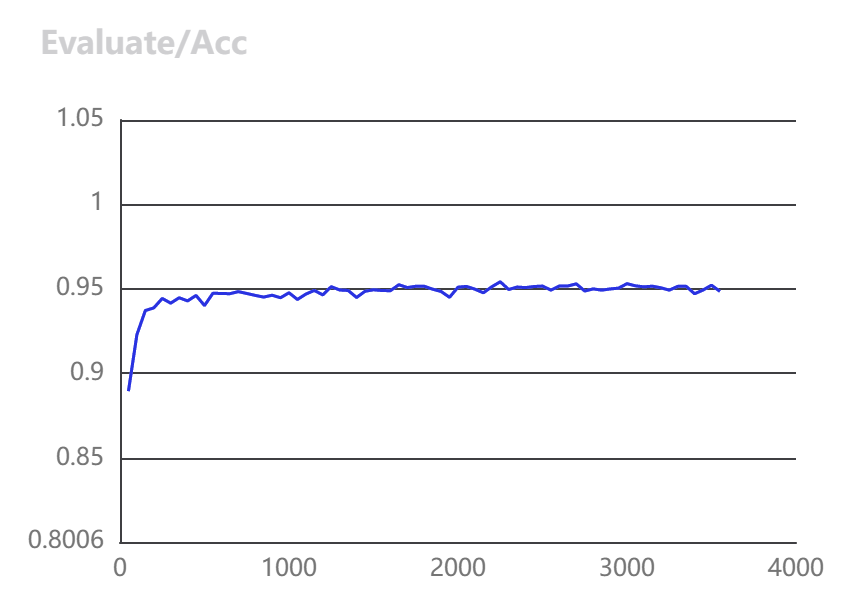 |
 |  |
模型导出
!python PaddleSeg/tools/export.py --config configs/deeplap+.yml --model_path model/model.pdparams
模型部署
!python PaddleSeg/deploy/python/infer.py \--config output/inference_model/deploy.yaml \--image_path segdata/png_images/IMAGES/img_0003.png
五、效果展示
 |  |  |
六、总结提高
总结:
- 去除了样本较少类别,提高模型在多类别样本上性能
- 采用了deeplapv3+算法,并进行部署
改进方向:
- 修改模型损失函数的各个类别权重
- 多个损失函数相结合
- 增加训练的采样算法
- 扩充数据集
七、作者介绍
关于作者
项目作者: 姓名:李灿 AI Studio昵称: Nefelibata0 个人主页
飞桨导师: 姓名:韩磊 AI Studio昵称: ninetailskim 个人主页
PS:本人菜鸟一只,欢迎互相关注

此文章为转载
原文链接
这篇关于[AI特训营第三期]基于PaddleSeg的衣物分割的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







