本文主要是介绍pandas使用HYPERLINK追加写入超链接-url、文件、图片,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
pandas使用HYPERLINK追加写入超链接-url、文件、图片
使用HYPERLINK即可达到目的,可以写url、文件、图片、各种你自己能访问的路径
注意:HYPERLINK里面的字符长度不能超过255,否则无法写入超链接
调试目录结构
manFile(文件夹)
- images(文件夹)
- res1.png
- test.txt
- result(文件夹)
- 生成excel文件.xlsx
- test2.txt
- main.py
- draft.txt
主要代码段
#四个示例
textpath1 = r'../draft.txt' #写相对于表格的路径
textpath2 = r'..\images\test.txt'
textpath3 = r'test2.txt'
textpath4 = r'../images/res1.png'# print("--------------开始写入到表格中--------------------")
# 不加index会报错ValueError: If using all scalar values, you must pass an index
df = pandas.DataFrame(self.summary_title, index=[0]) # 字典数据,
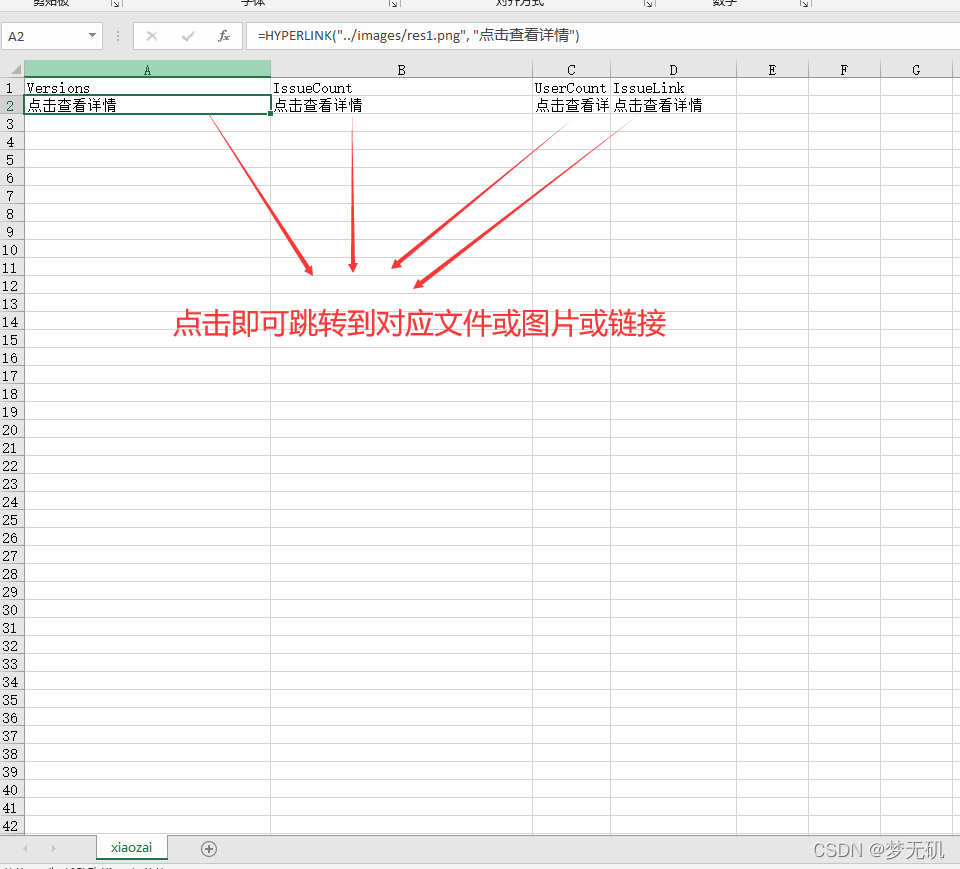
df._set_value(0, 'UserCount', '=HYPERLINK("{}", "点击查看详情")'.format(textpath1))
df._set_value(0, 'IssueLink', '=HYPERLINK("{}", "点击查看详情")'.format(textpath2))
df._set_value(0, 'IssueCount', '=HYPERLINK("{}", "点击查看详情")'.format(textpath3))
df._set_value(0, 'Versions', '=HYPERLINK("{}", "点击查看详情")'.format(textpath4))
注意事项:
- 关于路径:路径是以表格的路径为原点,进行写相对路径的,不是根据py文件所在的路径写相对路径
- 关于调试:手动在excel中手写这个函数无法生效,必须要通过这套代码写才会生效
- 关于file路径:不通过HYPERLINK,通过file也可以写文件,但只能写入绝对路径,格式
file:///D:\D_Working\文档.txt- 手动写入也会生效,注意file后面有英文冒号顺斜杆,路径是反斜杆,这个写错是不生效的
可直接运行代码
# -*- coding: utf-8 -*-# @Time : 2022/2/24 10:24
# @Author : Vincent.xiaozai
# @Email : Lvan826199@163.com
# @File : demo11_pandas写入文件图片超链接.py
from datetime import datetimeimport pandas
import xlsxwriter as xlsxwriter
from openpyxl import load_workbookclass A():def __init__(self):passdef create_excel(self, game_name):# # print("-------------------------创建{}表格------------------------".format(project_name_list[project_index]))# # 以当前时间命名now_time = datetime.now().strftime('%Y-%m-%d-%H-%M-%S')self.excel_name = r"result/{}_{}.xlsx".format('mengwuji', now_time)workbook = xlsxwriter.Workbook(self.excel_name)# 新增sheet页sheet = workbook.add_worksheet(name=game_name)sheet.set_column(0, 0, 30) # 设置第一列的宽度sheet.set_column(1, 1, 32) # 设置第二列的宽度sheet.set_column(2, 2, 9) # 设置第三列的宽度sheet.set_column(3, 3, 15) # 设置第四列的宽度workbook.close() # 保存book = load_workbook(self.excel_name)# 在AllCloseTime这个sheet中进行数据汇总self.summary_title = {"Versions": ["Versions"],"IssueCount": ["IssueCount"],"UserCount": ["UserCount"],"IssueLink": ["IssueLink"]}df = pandas.DataFrame(self.summary_title) # 字典数据,按顺序,第一个为第一列,每个key后面的value长度必须一样,可以为空df1 = pandas.DataFrame(pandas.read_excel(self.excel_name, sheet_name="xiaozai")) # 读取原数据文件和表writer = pandas.ExcelWriter(self.excel_name, engine='openpyxl')writer.book = book # 写入指定给的表格writer.sheets = dict((ws.title, ws) for ws in book.worksheets)df.to_excel(writer, sheet_name="xiaozai", startrow=0, index=False,header=False) # 将标题写入excel中Summary表writer.save() # 保存print("-------------------------创建{}项目表格成功------------------------".format(self.excel_name))book = load_workbook(self.excel_name)self.summary_title['Versions'] = 'hell0'self.summary_title['IssueCount'] = 'hell0'self.summary_title['UserCount'] = '点击跳转'self.summary_title['IssueLink'] = '点击跳转'textpath1 = r'../draft.txt' #相对于表格的路径textpath2 = r'..\images\test.txt'textpath3 = r'test2.txt'textpath4 = r'../images/res1.png'# print("--------------开始写入到表格中--------------------")# 不加index会报错ValueError: If using all scalar values, you must pass an indexdf = pandas.DataFrame(self.summary_title, index=[0]) # 字典数据,df._set_value(0, 'UserCount', '=HYPERLINK("{}", "点击查看详情")'.format(textpath1))df._set_value(0, 'IssueLink', '=HYPERLINK("{}", "点击查看详情")'.format(textpath2))df._set_value(0, 'IssueCount', '=HYPERLINK("{}", "点击查看详情")'.format(textpath3))df._set_value(0, 'Versions', '=HYPERLINK("{}", "点击查看详情")'.format(textpath4))df1 = pandas.DataFrame(pandas.read_excel(self.excel_name, sheet_name="xiaozai")) # 读取原数据文件和表writer = pandas.ExcelWriter(self.excel_name, engine='openpyxl')writer.book = book # 写入指定给的表格writer.sheets = dict((ws.title, ws) for ws in book.worksheets)df_rows = df1.shape[0] # 获取原数据的行数df.to_excel(writer, sheet_name="xiaozai", startrow=df_rows + 1,index=False,header=False) # 将数据写入excel中对应的项目sheet表,从第一个空行开始写writer.save() # 保存if __name__ == '__main__':run = A()run.create_excel('xiaozai')
表格展示
欢迎关注我的微信公众号:
梦无矶的测试开发之路
这篇关于pandas使用HYPERLINK追加写入超链接-url、文件、图片的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




