本文主要是介绍Python通过OSM获取全国屋顶数据(经纬度、轮廓、面积、地址等),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引文
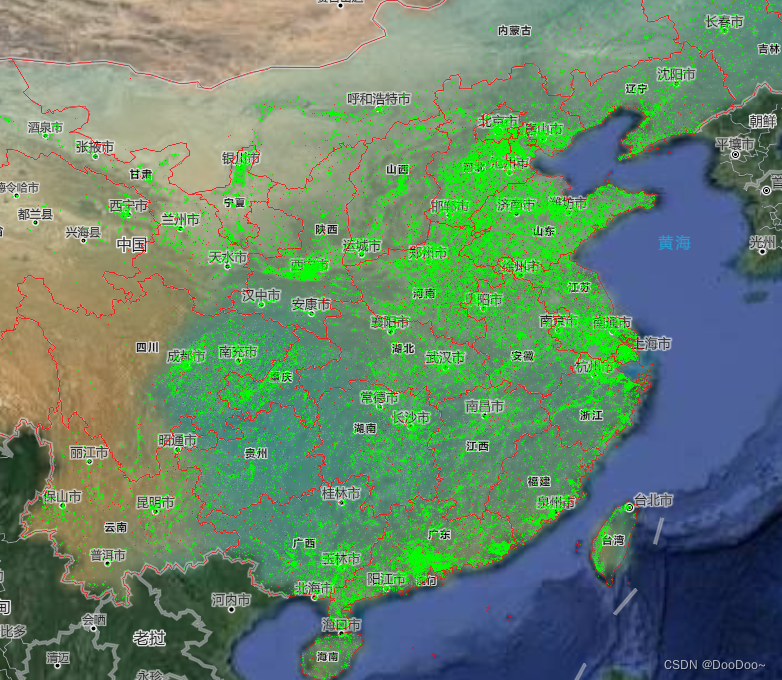
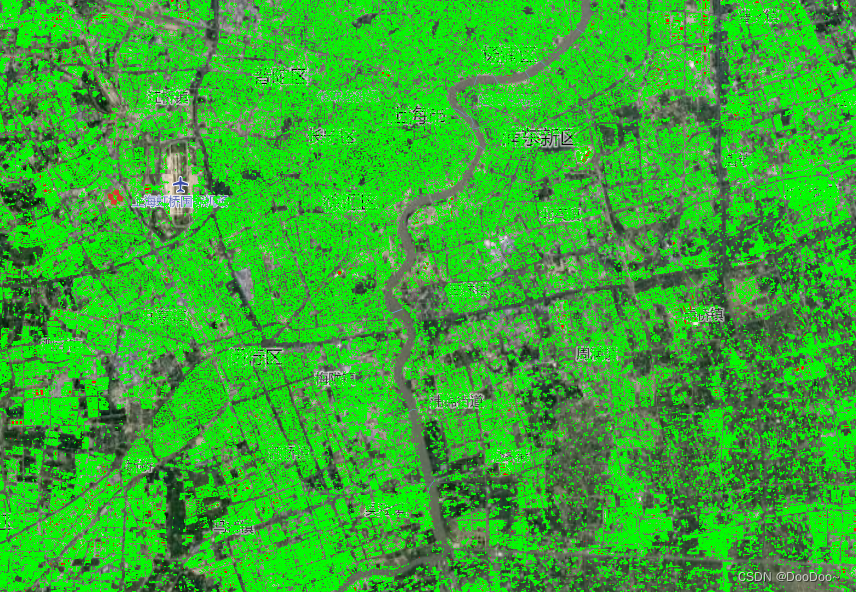
本文实现了使用Python通过OSM获取全国屋顶数据(经纬度、轮廓、面积、地址等)的效果,详细过程和效果可参考以下内容。
1. 导入相关依赖库
首先通过pip install pyrosm安装pyrosm,如果是Windows系统在安装中出现了问题,可参考https://pyrosm.readthedocs.io/en/latest/installation.html 尝试解决。
import requests
import pandas as pd
import os
from pyrosm import OSM
2. 下载各省的pbf文件
由于全国的pbf文件过大,而且在后续处理过程中容易爆内存,因此选择分各个省份进行处理后再合并。
url = 'http://download.openstreetmap.fr/extracts/asia/china/'
osm_dic = {'anhui': {'name_zh': '安徽','url': url + 'anhui-latest.osm.pbf'},'beijing': {'name_zh': '北京','url': url + 'beijing-latest.osm.pbf'},'chongqing': {'name_zh': '重庆','url': url + 'chongqing-latest.osm.pbf'},'fujian': {'name_zh': '福建','url': url + 'fujian-latest.osm.pbf'},'gansu': {'name_zh': '甘肃','url': url + 'gansu-latest.osm.pbf'},'guangdong': {'name_zh': '广东','url': url + 'guangdong-latest.osm.pbf'},'guangxi': {'name_zh': '广西','url': url + 'guangxi-latest.osm.pbf'},'guizhou': {'name_zh': '贵州','url': url + 'guizhou-latest.osm.pbf'},'hainan': {'name_zh': '海南','url': url + 'hainan-latest.osm.pbf'},'hebei': {'name_zh': '河北','url': url + 'hebei-latest.osm.pbf'},'heilongjiang': {'name_zh': '黑龙江','url': url + 'heilongjiang-latest.osm.pbf'},'henan': {'name_zh': '河南','url': url + 'henan-latest.osm.pbf'},'hong_kong': {'name_zh': '香港','url': url + 'hong_kong-latest.osm.pbf'},'hubei': {'name_zh': '湖北','url': url + 'hubei-latest.osm.pbf'},'hunan': {'name_zh': '湖南','url': url + 'hunan-latest.osm.pbf'},'inner_mongolia': {'name_zh': '内蒙古','url': url + 'inner_mongolia-latest.osm.pbf'},'jiangsu': {'name_zh': '江苏','url': url + 'jiangsu-latest.osm.pbf'},'jiangxi': {'name_zh': '江西','url': url + 'jiangxi-latest.osm.pbf'},'jilin': {'name_zh': '吉林','url': url + 'jilin-latest.osm.pbf'},'liaoning': {'name_zh': '辽宁','url': url + 'liaoning-latest.osm.pbf'},'macau': {'name_zh': '澳门','url': url + 'macau-latest.osm.pbf'},'ningxia': {'name_zh': '宁夏','url': url + 'ningxia-latest.osm.pbf'},'qinghai': {'name_zh': '青海','url': url + 'qinghai-latest.osm.pbf'},'shaanxi': {'name_zh': '陕西','url': url + 'shaanxi-latest.osm.pbf'},'shandong': {'name_zh': '山东','url': url + 'shandong-latest.osm.pbf'},'shanghai': {'name_zh': '上海','url': url + 'shanghai-latest.osm.pbf'},'shanxi': {'name_zh': '山西','url': url + 'shanxi-latest.osm.pbf'},'sichuan': {'name_zh': '四川','url': url + 'sichuan-latest.osm.pbf'},'tianjin': {'name_zh': '天津','url': url + 'tianjin-latest.osm.pbf'},'tibet': {'name_zh': '西藏','url': url + 'tibet-latest.osm.pbf'},'xinjiang': {'name_zh': '新疆','url': url + 'xinjiang-latest.osm.pbf'},'yunnan': {'name_zh': '云南','url': url + 'yunnan-latest.osm.pbf'},'zhejiang': {'name_zh': '浙江','url': url + 'zhejiang-latest.osm.pbf'},'taiwan': {'name_zh': '台湾','url': 'https://download.geofabrik.de/asia/taiwan-latest.osm.pbf'}
}
tip:由于目标文件在外网,所以下载速度会比较慢,使用科学上网工具可显著提高文件的下载速度!
path = 'osm_data/'
if not os.path.exists(path):os.makedirs(path)def get_all_pbf():def download_pbf(file_path, url):headers={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'}response = requests.get(url=url,headers=headers).contentwith open(file_path, "wb") as f:f.write(response)for location in osm_dic:file_path = path + location + '.osm.pbf'url = osm_dic[location]['url']try:download_pbf(file_path, url)print(location+'.osm.pbf下载成功!文件目录为:' + file_path)except:print(location+'.osm.pbf下载失败!')get_all_pbf()
3. 读取osm.pbf的建筑物数据,保存为csv文件
def pbf2csv(location):try:osm = OSM(path + location + '.osm.pbf')buildings = osm.get_buildings()buildings = buildings[buildings['geometry'].apply(lambda x: 'POLYGON' in str(x))][['addr:city', 'addr:postcode', 'addr:street', 'name', 'building','amenity', 'building:levels', 'height', 'office', 'shop', 'id', 'timestamp', 'version', 'geometry', 'tags','osm_type']]buildings.to_csv(path + location + '.csv', index=0, encoding='utf_8_sig')print(location+'.csv 提取成功!')except:print(location+'.csv 提取失败!!!')for location in osm_dic:pbf2csv(location)
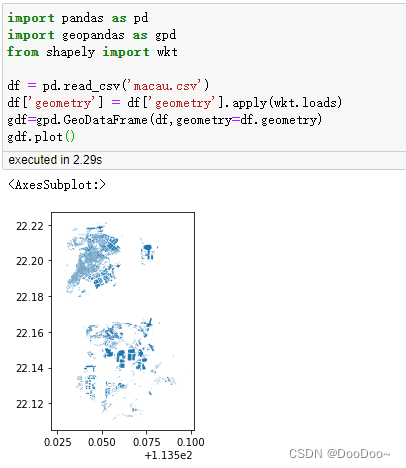
4. 简单展示数据结果
import pandas as pd
import geopandas as gpd
from shapely import wktdf = pd.read_csv(path + 'macau.csv')
df['geometry'] = df['geometry'].apply(wkt.loads)
gdf=gpd.GeoDataFrame(df,geometry=df.geometry)
gdf.plot()
5. 全国屋顶数据
由于篇幅所限,后续还有通过高德API解析地址、wgs_84坐标系和gcj_02的坐标系转换等步骤没有详细记录。
且由于全国屋顶数据量较大,需要最终结果文件的朋友可以私信我获取。

这篇关于Python通过OSM获取全国屋顶数据(经纬度、轮廓、面积、地址等)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





