本文主要是介绍论文翻译——Comparing Deep Learning And Support V ector Machines for Autonomous Waste Sorting,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
比较深度学习和支持向量机的自动垃圾分类
摘要:垃圾分类是将垃圾分类成不同类型的过程。目前的趋势是有效地对垃圾进行分类,以便适当地处理。必须尽早进行分离,以减少其他物质对废物的污染。这一过程自动化的需要对垃圾处理公司来说是一个重要的促进因素。本研究旨在通过应用机器学习技术,仅从垃圾图片中识别垃圾类型,实现垃圾分类的自动化。使用了两种流行的学习算法:卷积神经网络(CNN)深度学习和支持向量机(SVM)。每种算法都创建了不同的分类器,利用256 x 256彩色png图像将废物分为3大类:塑料、纸张和金属。比较了两种分类器的准确率,以选出最佳分类器并在树莓派3上实现。pi控制一个机械系统,引导废物从其初始位置进入相应的容器。然而,在本文中,我们只比较了两种机器学习技术,并在pi上实现了最佳模型,以衡量其分类速度。支持向量机的分类准确率达到94.8%,而CNN仅达到83%。支持向量机对不同类型的垃圾也表现出了特殊的适应性。CNN使用NVIDIA DIGITS进行训练,SVM使用Matlab 2016a进行训练。SVM模型最终在树莓派3上实现,它产生了快速分类,平均每张图像0.1s。
1.说明
垃圾分类在家庭级别[1]变得特别重要。目前的趋势是有效地对垃圾进行分类,以便适当地处理。把废物流中不同的元素分开,可回收有用的物料,从而减少运往堆填区的大量物料,并使可循环再造的物料可运往目的地。公司还对材料进行分类和回收,以提取价值[1]。因此,对智能垃圾分类的需求越来越大。从另一个角度来看,计算技术正在发展,日常使用的小工具正变得更加智能。凭借其计算能力,它们可以被整合到一个环保高效的垃圾分类系统中。
垃圾的产生在最近一段时间急剧增加。如果不妥善处理,它们会对环境产生有害影响。垃圾分类应尽早完成,以最大限度地增加可回收物品的数量,减少被其他物品污染的可能性。让垃圾桶更智能有助于解决这一问题,无论是在家庭还是大型场合,都可以自动进行垃圾分类。在本研究中,我们旨在通过比较两个非常流行的分类器CNN和SVM来创建这样一个设备。该分类器显示了更好的准确性,实现了自动垃圾分类。结果就是一个树莓派控制的垃圾桶。智能垃圾桶会拍下垃圾的照片,然后自动识别出垃圾的类型,并将其重定向到相应的容器中。第二部分包含了一个类似的技术审查,第三部分介绍了数据收集过程和预处理,第四部分简要介绍了CNN和方框图描述了训练阶段和使用的网络体系结构,第五部分简要介绍支持向量机和使用的技术培训,第六部分比较两种模型的精度,第七部分展示了我们的模型的实现在覆盆子π和描述了分类过程,最后对本文的工作进行了总结,并对研究结果、不足和未来的工作进行了总结。
2.背景
卷积神经网络[3]对模式识别[4]产生了很大的影响。在CNN时代之前,特征是人工挑选和设计的,然后由分类器跟踪。CNN革命性的一点是,特征大多是从训练数据中自动学习的。CNN的架构使其在图像识别方面特别强大。特别是卷积操作捕捉图像的二维性质。此外,滑动内核的使用有助于减少通过权值共享来学习的参数数量。CNN已经在商业上使用了20多年[5],CNN的使用在最近几年呈爆炸式增长,因为最近的两个发展。首先,大型标记数据集,如大规模视觉识别挑战(ILSVRC)[6]已经可以用于训练和验证。其次,CNN学习算法已经在大规模并行图形处理单元(gpu)上实现,加速了学习和推理。CNN的完整描述可以在第四部分找到。
另一方面,SVM在许多应用中显示了最先进的准确性,从医疗[7]到环境[8]到许多其他应用。简而言之,支持向量机是一种最小风险分类器。支持向量机总是通过在两类之间留下尽可能大的距离来找到分离数据的平面。最近,支持向量机与卷积神经网络相结合,以便更好地进行预测。支持向量机最近也与大量用于图像识别的特征技术[9]捆绑在一起。第五节简要介绍了支持向量机和特征包技术。
垃圾自动分类一直是许多研究的课题。最近的一项研究使用OWL本体对垃圾[10]进行分类。然而,排序的元素需要配备RFID,以确保排序的准确性。另一种方法是使用光学传感器[11]来区分纹理和颜色。然而,光学传感器比Pi相机更昂贵,而且需要手工制作才能进行分类。
在本文中,我们提出了一种新的使用CNN AlexNet[12]和SVM捆绑袋特征技术用于自动垃圾分类。所提出的方法是垃圾分类的端到端学习方法。不需要手工制作任何特征,取而代之的是CNN和SVM将能够自动发现模式。然后,我们在树莓派3上实现了最佳模型,它通过pi相机拍摄的图像自动对废物进行分类。但在训练模型之前,必须收集废弃的图像。下一节将描述数据收集过程。
3.数据收集
通过对许多项目拍照来收集训练数据。一个圆周率摄像机连接到树莓圆周率3,它实现了一个简单的python脚本来捕捉图像。它们被存储为256 × 256无损png彩色图像。该系统还包含一个初步的立方体小室,废物最初被扔在里面。这个房间由10个1瓦的led灯照亮。当舱门打开时,led灯自动打开。在关闭腔室后,led将会亮5秒,在此期间,废料的图片会自动从pi捕获。在数据收集阶段,使用一个按钮来触发捕获脚本。为了更好地学习,我们需要捕捉各种废物类型的图像。拍摄到的物品包括各种形状和大小的塑料水瓶,瓶子也被弯曲和扭曲,以创造更多的图像。各种形状的纸也被使用,快餐杯和盒子,软饮料罐和其他类型的饮料也包括在内。一旦图像被捕获,它被手动放置在相应的文件夹(塑料,纸或金属)。总共收集了2000张照片:667张塑料的,667张纸的和666张金属的。然后这些图像被分成3组:训练,验证和测试。训练集包含60%的数据,用于获得深度网络和支持向量机的最优权值。验证数据由20%的图像组成,用于在每次训练迭代时获得分类器的精度。测试集由剩余的20%组成,用于达到最高验证精度的模型,以便报告模型的最终精度。
为了减少过拟合,使用保持标签的变换[13],[14],[15],人工将训练集增强到6000张图像。所使用的方法在[4]中描述,它只包括在训练图像中改变RGB通道的强度。方法应用主成分分析(PCA)的RGB分量训练集,然后添加多个发现原则组件,与比例系数等于相应的特征值随机变量乘以一个来自与零均值高斯分布和标准偏差为0.1。在下一节中,我们将描述CNN以及如何在训练阶段使用所描述的训练数据。
4.卷积神经网络
在本节中,我们将简要介绍卷积神经网络,并强调其相对于其他技术的优势。在规则神经网络中,输入层的每个神经元都与图像的所有像素相连。因此,一个尺寸为28 x 28的图像将导致每个神经元有784个输入权重。然而,平等对待图像中的所有像素是很奇怪的。例如,该网络对彼此相距较远的像素和在同一条件下彼此相距较近的像素进行处理。这是因为常规的神经网络没有考虑到图像的空间结构。卷积神经网络试图利用图像中的空间结构。这些网络采用了一种特殊的结构,能够很好地适应图像识别。卷积神经网络基于3种思想:局部接受域或核、权值共享和池化。
A.局部感受野
在常规的神经网络中,神经元被认为是沿着一条垂直的线堆叠的。然而,在卷积神经网络中,神经元被表示为一个二维的神经元矩阵。并不是每个像素都与网络的所有神经元相连,而是只有一小部分被连接。更精确地说,输入层的每个神经元都将连接到图像中一个5 × 5的区域,对应25个输入。内核的大小是可变的,并根据验证集的精度来选择。图像中的这个区域被称为局部感受区。所以每个神经元都想知道它的感受野的权重。然后我们将局部接收域滑动到一定数量的像素,称为跨越图像。每迈出一步,感受区就会改变位置,产生另一个与不同神经元相连的感受区。
B.共享权重和偏差
我们上面提到过,每个神经元都连接到不同的感受野,但所有的神经元都有相同的权重。这使得网络能够通过整张图片学习同样的东西。因此,所有的神经元都将学习如何在图像的不同部分检测特定的东西。这个想法是非常有用的,因为如果一个神经元学习在图像的一个部分检测垂直边缘,它也是有用的使用相同的网络在图像的另一个位置检测这个边缘。这个属性使CNN移位不变。因此,如果一篇论文被检测到在图像的左上角,它也会被检测到,如果它碰巧是在图像的右下角。现在的问题是,一个卷积层将学习如何识别图像中的一个东西。因此,卷积网络是通过将许多卷积层叠加在一起而形成的。因此,通过叠加三层,网络将能够学习整个图像的三种不同的东西。也许它将学习如何检测相同的边缘,但在不同的颜色。实际上,要使用更多的层。
C.池化
除了卷积层。卷积网络也包含池化层。它们通常在卷积层之后使用,以简化其输出。一个常用的池化层是“最大池化”层。这层神经元是由2 × 2的图组成的。因此,每4个来自卷积层的神经元就被简化为一个神经元,对应于一个具有最大输出的神经元。这样我们得到的输出数减少了4倍。最大池化应用于所有的卷积层。因此,如果卷积网络是3 × 28 × 28(3层28 × 28个神经元),它就会减少到3 × 14 × 14(仍然是3层,但有14 × 14个神经元)。从逻辑上讲,最大池化层是询问接收字段是否检测到什么,并丢弃关于检测到的位置的所有其他信息。这是有意义的,因为如果一个特征被检测到,它的位置并不重要。这有助于减少后续层中所需参数的数量。将多个CNN层组合在一起,形成一个深度网络。下面将介绍一个流行的深度网络AlexNet [4]。
D.AlexNet
AlexNet是一个由7层组成的深层网络。它总共包含65万个神经元,6000万个参数和6.3亿个连接。使用的激活函数是矫正线性单元(ReLU)。第一个卷积层接收256 × 256 × 3的图像。总共96层大小为5x5的局部感受野被应用到图像上,步长为1,填充为2。填充是为了保持输出的大小等于输入的大小。换句话说,一个5x5窗口在256 x 256的图像上滑动,步长为1,可能会出现252 x 252不同的位置。通过从四面八方填充2个像素的图像将导致256 × 256的输出,因此,与输入的大小相同。为了深入到网络中,填充是很重要的,否则只在几层之后,特征的数量就会减少到微不足道的数量。所以现在的输出是256x256x96。本地接收字段层之后是一个内核大小为3的maxpool层,stride为2,没有填充。第二部分与第一个卷积网络相同,后面是一个类似的maxpool层。第三部分与初始卷积网络相同,后面跟着一个相同的maxpool层。最后一部分是用于数据分类的softmax层。这一层由一个由3个神经元组成的完全连接的层组成。每一个神经元都与上一层的每一个输出相连。输出层的每个神经元都有自己的输出。网络选择有最高输出的那一个。神经元1对应塑料,神经元2对应纸,神经元3对应金属。图1显示了带有所有系数的原始AlexNet。

使用CNN的优点在于,内核将充当一个过滤器,从左到右、从上到下扫描图像,使分类过程具有移位不变。因此,如果一个瓶子在图像中间或图像的其他地方被捕获,它将被该网络识别。总之,卷积神经网络可以从像素中学习新的特征。网络的每个部分都将从上一层学习自己的特征。最后,将这些特征呈现给softmax层,以便做出最终决策。
训练图像被送入分类器,然后计算一个建议的类。将提出的类与该图像的期望类进行比较,并调整CNN的权值,使CNN输出更接近期望输出。权重调整是通过反向传播来完成的,就像在数字机器学习包中实现的那样。我们的培训系统框图如图2所示。经过训练后,网络可以从pi摄像机的图像中生成类,如图3所示。由于GPU内存大小的限制,图像从256 x 256压缩到32 x 32。与没有这种限制的SVM相比,这种尺寸的减少会影响CNN的精度。


在本节中,我们将介绍用于图像分类的支持向量机和包特征技术。
A.SVM
在最简单的形式中,支持向量机使用线性超平面来创建具有最大边界[16]的分类器。在其他情况下,数据不是线性可分的,数据被映射到更高维的特征空间。该任务使用各种非线性映射函数:多项式,sigmoid和径向基函数(RBF)如高斯RBF。在高维特征空间中,支持向量机算法使用线性超平面分离数据。与其他技术不同的是,概率模型和概率密度函数不需要先验已知。这对于泛化是非常重要的,因为在实际情况中,关于输入和输出之间的潜在概率规律和分布没有足够的信息。由于支持向量机在许多领域都记录了目前最先进的准确性,而且它具有出色的泛化能力,因此也被用于本研究。
下面是一个关于支持向量机的理论介绍和将这两类分开的超平面的一般方程。在线性可分数据的情况下,方法是在所有分离的超平面中找到一个最大限度的边缘。显然,任何其他超平面都会比这个超平面有更大的预期风险。
在学习阶段,机器使用训练数据寻找参数w = [w1w2…]给定的决策函数d(x,w, b)的wn]Tand b:
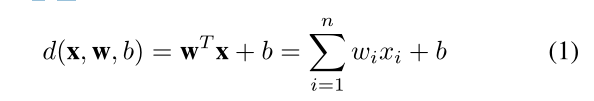
分离的超平面遵循方程d(x,w, b) = 0。在测试阶段,一个看不见的向量x,将根据以下指标函数产生输出y:

也就是说,决策规则是:如果d(x,w, b) > 0,则x属于第1类;如果d(x,w, b) < 0,则x属于第2类。通过最小化下式得到权向量和偏差:
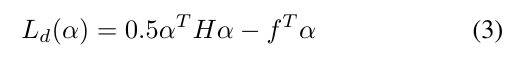
受下列限制:
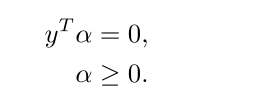
其中H为Hessian矩阵,H = yiyj(xixj), f为单位向量f =[1,1…1]T。有对偶优化问题的解α 0i将足以确定权向量和偏差,使用以下方程:

其中N为支持向量的个数。上述线性分类器的能力有限,因为它只用于线性可分的数据,而在大多数实际应用中,数据是随机的,不能线性可分。非线性数据必须通过适当的映射函数φ (x)映射到高维的新特征空间,该映射函数具有很高的维数,可能是无限的。幸运的是,在所有的方程中,这个函数只以点积的形式出现。根据超出本文讨论范围的核Hilbert空间[17]的再生理论,定义一个核函数为:

核变换的这一显著特征使支持向量机能够在不影响处理时间的情况下对多维数据进行操作。的确,在线性情况下,处理时间大致是对Hessian矩阵进行逆运算所需要的时间,该矩阵为O(n3),其中n为训练点的个数。由于从线性到非线性的转换是通过简单的核变换来实现的,因此Hessian矩阵的维数没有改变,因此处理时间是相同的,因此它在多维数据中的适用性和高性能。
B.功能包
特征袋技术类似于自然语言处理中使用的词汇袋技术。一个8 x 8的窗口从上到下扫描整个图像,以寻找特征。这个过程是在整个训练集上进行的。一旦完成这个过程,就会生成一个不同特征的词汇表。因此,每个图像都由一个与词汇表大小相同长度的向量来描述,向量中的每个元素都显示相应特征在该图像中出现的次数。为了减少特征的数量,词汇集中只保留前80%的词汇。然后使用K-means[18]算法将相似的特征聚类在一起。最后,这些特征被简化为K-means找到的K个簇的K个质心。所以现在每一幅图像都被简化为一个k维向量,并被馈给支持向量机进行训练。K的值以及在我们的训练集中发现的特征的数量将在下一节中显示。
四、仿真和实验
A.训练软件
像AlexNet这样的巨大网络,甚至是训练集很大的SVM,都不能在树莓派上进行训练。它必须脱机完成,生成的模型将在pi上实现。为了培训,我们使用了一台惠普笔记本电脑,配备了Intel i7处理器和NVIDIA 740 M GPU, GPU专用内存为2gb。CNN的训练软件我们使用的是NVIDIA DIGITS,即安装在Ubuntu 14.04系统上的交互式深度学习GPU训练系统。机器学习库“Caffe”[19]被用于创建网络并在数字中使用。对于SVM,我们使用的Matlab 2016a也安装在Ubuntu 14.04上。对于这两个模型,计算并从所有图像中减去训练集中所有图像的平均图像。这个平均归一化步骤对应于亮度归一化。因此,两幅相同但亮度不同的图像将被认为是同一幅图像。这将提高检测的准确性。
B.结果与讨论
我们现在展示了AlexNet和SVM的结果。1) AlexNet:为了优化网络的权值,使用了小批量梯度下降反向传播算法。每次权重更新都是在整个批处理发送到网络后进行的,批处理的错误会向后传播到权重中以更新它们。本研究使用的批数为100。通常,高批量的结果更好的准确性和更好的收敛性。然而,批处理的大小受到GPU上可用内存量的限制。所以在GPU内存耗尽之前,100是我们可以在批处理中使用的最大图像数。每个权值都按与误差成比例的一小部分进行更新。该比例因子称为学习速率α,在本实验中设置为0.01。大的学习速率会导致算法发散,小的学习速率会使收敛非常缓慢。图4显示了训练和验证集的收敛结果。它显示了验证集的精度的变化,训练集和验证集的均方误差损失与时代的数目有关。结果表明,该算法在验证集上的训练准确率最高,达到89%。从图中可以看出,验证数据的训练误差和损失相差甚远。训练数据的损失为0.1,验证数据的损失为0.3。这是一种过拟合的迹象,可以通过向数据集中添加更多的图像来解决,或者通过添加更多的特征来保持图像的256 x 256,而不是将其压缩到32 x 32。然而,由于硬件的限制,这是不可能的。这个问题是我们研究的一个不足之处,我们将在今后的工作中加以解决。我们的团队将获取更多的图像,我们还将获得一个更大的NVIDIA Tesla GPU, 12GB内存,这将减少过拟合,提高预测精度。最后在测试机上对最佳模型进行了测试,纸的检测率为89%,塑料的检测率为84%,金属的检测率为76%,准确率为83%。
2)支持向量机:为了得到训练支持向量机所需的特征包,我们使用Matlab中的bagfeatures函数。该方法以训练集和K-means的聚类数作为参数。K通常有500但是我们改变了K值在400 - 600年间10步,计算准确性的验证集。K了,精度最高是500,是用于测试集。一旦完成了包的特性进行支持向量机训练使用“trainImageCategoryClassifier”功能。这个函数返回一个可以通过使用函数“evaluate”应用到测试集的支持向量机模型。该测试装置的准确度为94.8%,其中纸张的检测率为99%,塑料的检测率为96%,金属的检测率为90%。因此,两种模型均获得了较好的精度,其中支持向量机(SVM)获得了迄今为止的最佳精度。但是,在未来,更多的图像和更多的GPU内存将有利于CNN,因为它将减少我们所观察到的过拟合的影响。由于SVM模型获得了更好的精度,我们在下一节中描述的树莓派3上实现了这个模型。
7、硬件实现
上述SVM模型在树莓pi 3上实现,并连接高清晰度pi摄像机。首先,在Matlab中获取树莓派的硬件支持包,并在pi上下载安装专用的pi固件。在训练过程中,将单词结构袋与分类器一起保存在a中。垫”文件。文件大小为114 kb,完全可以放在pie上。编写了一个Matlab脚本等待按钮被按下,然后捕捉图像。一旦按下按钮,相机就会对垃圾进行快照,并将其保存为256 * 256色无损png文件。图像被发送到预加载的分类器进行分类,分类以LED的形式输出。每一个类都由一个LED来表示,它会根据这个决定打开。图像分类速度较快,平均分类时间为0.1秒,标准差为0.005s。
8、结论与未来工作
在本研究中,我们对深度学习和支持向量机在垃圾分类方面进行了比较。AlexNet的分类准确率为83%,SVM的分类准确率为94.8%。SVM模型在树莓派上实现,证明了仅通过树莓派的图像对废弃物进行分类的能力。我们研究的缺点是训练集中的图像数量较少,以后我们会增加图像的数量和种类。另一个技术缺点是本研究可用的GPU内存较低。2GB的GPU内存迫使我们将图像大小从原来的256 * 256缩小到32 * 32。这种减少也导致了更多的过拟合问题。这个问题将在未来得到一个专门的机器学习服务器,每个有2个特斯拉12GB内存的gpu。这些gpu将使我们能够使用256 x 256的分辨率,同时保持100张图像作为批处理大小。最后,实现的模型在树莓派3上的平均执行时间非常低(0.1s)。
这篇关于论文翻译——Comparing Deep Learning And Support V ector Machines for Autonomous Waste Sorting的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
