本文主要是介绍golang常用库之- encoding/binary包 | 字节转换成整形、整形转换成字节、“大字端” 和 “小字端”,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- golang常用库之- encoding/binary包 | 字节转换成整形、整形转换成字节、“大字端” 和 “小字端”
- 背景和使用场景
- go语言socket通信中大小端转换问题
- encoding/binary包
- Go语言自定义二进制文件的读写操作
- 字节转换成整形、整形转换成字节
- 代码demo
- 小字端” 和 “大字端”
- 计算机字节序和网络字节序
- 对于网络传输,使用的就是大字端。为什么?
golang常用库之- encoding/binary包 | 字节转换成整形、整形转换成字节、“大字端” 和 “小字端”
背景和使用场景
Go编程的三十六个套路: int与[]byte互转用于数据传输
参考URL: https://blog.frognew.com/2016/03/go-guide-encoding-binary.html
在用Go进行数据传输的场景下,例如文件传输或文件存储时,需要将Go的数据例如int转换为[]byte。 得到的[]byte可以进一步在网络上传输或写入到文件中。这个场景需要借助go标准库中的encoding/binary包来实现。
变长值是使用一到多个字节编码整数的方法,绝对值较小的数字会占用较少的字节数。这个在ProtocolBuffer的编码文档中有详细说明。
encoding/binary包相对于效率更注重简单。 如果需要高效的序列化,特别是数据结构较复杂的,可以选择更高级的解决方案, 例如encoding/gob包(Go语言自带的数据编码解码工具包),或者采用ProtocolBuffer(跨语言)。
使用encoding/binary包可以实现序列化和反序列化功能:
- binary.Write这个函数可以将数据序列化成字节流
- binary.Read这个函数可以将字节流反序列化为数据结构
使用encoding/binary包的优缺点:
- 优点: 简单、高效
- 缺点: 如果编码的结构中有不确定长度的类型,会报错
如果是go语言之间的序列化和反序列化推荐使用encoding/gob包,跨语言的序列化和反序列化可以使用protobuf,使用protobuf的化我们就不用考虑socket接受大小端的事情,protobuf数据里面就做了这种事情。
go语言socket通信中大小端转换问题
一般来说网络传输的字节序,可能是大端序或者小端序,取决于软件开始时通讯双方的协议规定。TCP/IP协议RFC1700规定使用“大端”字节序为网络字节序,开发的时候需要遵守这一规则。默认golang是使用大端序。详情见golang中包encoding/binary已提供了大、小端序的使用。
在内存中这些字节是按照从大到小的地址空间存储还是从小到大。发送接收双方事先约定好,否则就会不同的顺寻着对接收数据的解析顺序不同出错。发送端和解析端必须一致!
encoding/binary包
官方:https://pkg.go.dev/encoding/binary
golang的binary包简单实现了数字(number)到字节序(byte sequences)的转换,以及64位整型(varint)的编码与解码。
Go语言自定义二进制文件的读写操作
Go语言自定义二进制文件的读写操作
参考URL: http://c.biancheng.net/view/4570.html
Go语言的 encoding/binary 包中的 binary.Write() 函数使得以二进制格式写数据非常简单,函数原型如下:
func Write(w io.Writer, order ByteOrder, data interface{}) error
Write 函数可以将参数 data 的 binary 编码格式写入参数 w 中,参数 data 必须是定长值、定长值的切片、定长值的指针。参数 order 指定写入数据的字节序,写入结构体时,名字中有_的字段会置为 0。
package mainimport ("bytes""encoding/binary""fmt""os"
)type Website struct {Url int32
}func main() {file, err := os.Create("output.bin")for i := 1; i <= 10; i++ {info := Website{int32(i),}if err != nil {fmt.Println("文件创建失败 ", err.Error())return}defer file.Close()var bin_buf bytes.Bufferbinary.Write(&bin_buf, binary.LittleEndian, info)b := bin_buf.Bytes()_, err = file.Write(b)if err != nil {fmt.Println("编码失败", err.Error())return}}fmt.Println("编码成功")
}
运行上面的程序会在当前目录下生成 output.bin 文件,文件内容如下:
0100 0000 0200 0000 0300 0000 0400 0000
0500 0000 0600 0000 0700 0000 0800 0000
0900 0000 0a00 0000
字节转换成整形、整形转换成字节
使用 Go 语言中 binary 这个标准包,该包实现了数字与字节之间的转化。
下来我们将数字 0x22334455 转化为大字端字节存储。
buffer := new(bytes.Buffer)
binary.Write(buffer, binary.BigEndian, int32(0x22334455))
binary.BigEndian 常量,表示大字端。binary.LittleEndian 常量,表示小字端。
代码demo
package mainimport ("bytes""encoding/binary""fmt"
)//字节转换成整形
func BytesToInt(b []byte) int {bytesBuffer := bytes.NewBuffer(b)var x int32binary.Read(bytesBuffer, binary.BigEndian, &x) //转换有两种不同的方式,也就是大端和小端。大端就是内存中低地址对应着整数的高位。return int(x)
}//整形转换成字节
func IntToBytes(n int) []byte {x := int32(n)bytesBuffer := bytes.NewBuffer([]byte{})binary.Write(bytesBuffer, binary.BigEndian, x)return bytesBuffer.Bytes()
}func main() {fmt.Println(IntToBytes(2))fmt.Println(len(IntToBytes(2)))}
小字端” 和 “大字端”
计算机字节序和网络字节序
字节序 就是多字节数据类型 (int, float 等)在内存中的存储顺序。可分为大端序,低地址端存放高位字节;小端序与之相反,低地址端存放低位字节。
- 小端字节序(Little Endian): 低位字节排放在内存的低地址端,高位字节排放在内存的高地址端
- 大端字节序(Big Endian): 高位字节排放在内存的低地址端,低位字节排放在内存的高地址端
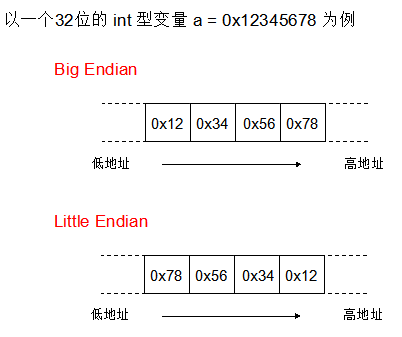
使用小端序时不移动字节就能改变 number 占内存的大小而不需内存地址起始位。比如我想把四字节的 int32 类型的整型转变为八字节的 int64 整型,只需在小端序末端加零即可。
44 33 22 11
44 33 22 11 00 00 00 00
上述扩展或缩小整型变量操作在编译器层面非常有用,但在网络协议层非也。
例如,对于一个加法器,选择的是小字端。为什么?
因为,加法是从低位到高位开始加,一旦有进位,就直接送到下一位,设计就很简单。
在进行数据传输时需要先考虑一下字节序,因为不同处理器的架构体系会使用不同的存储字节序,而对于TCP/IP网络传输的字节序则固定采用的是大端字节序。
对于网络传输,使用的就是大字端。为什么?
因为,早年设备的缓存很小,先接收高字节能快速的判断报文信息:包长度(需要准备多大缓存)、地址范围(IP地址是从前到后匹配的)。
在性能不是很好的设备上,高字节在先确实是会更快一些。
TCP/IP协议RFC1700规定使用“大端”字节序为网络字节序,开发的时候需要遵守这一规则~
在网络协议层操作二进制数字时约定使用大端序,大端序是网络字节传输采用的方式。
这篇关于golang常用库之- encoding/binary包 | 字节转换成整形、整形转换成字节、“大字端” 和 “小字端”的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





