本文主要是介绍widows定时开启任务crontab(参数讲解)hadoop案例(模拟生成新能源车辆数据)总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 概要
- 1、案例需求
- 2、Linux定时运行任务
- 2.1 crontab简介
- 2.2 参数说明
- 2,3 定时运行程序
- 3 windows下定时运行
- 4 将案例打包成.exe执行文件
- 3.1pyInstaller简介
- 3.1.2 常用指令
- 3.2 实现过程
- 5、在Linux上下载Wine
- 4.1 安装win
- 总结
概要
openAI 的 GPT 大模型的发展历程。
1、案例需求
模拟生成新能源车辆数据
编写一个程序,每天凌晨3点模拟生成当天的新能源车辆数据(字段信息必须包含:车架号、行驶总里程、车速、车辆状态、充电状态、剩余电量SOC、SOC低报警、数据生成时间等)。
要求:
1、最终部署时,要将这些数据写到第一题的HDFS中。(如果有多个组做第一题,则任选一个HDFS即可);
2、车辆数据要按天存储,数据格式是JSON格式,另外如果数据文件大于100M,则另起一个文件存。每天的数据总量不少于300M。比如假设程序是2023-01-1 03点运行,那么就将当前模拟生成的数据写入到HDFS的/can_data/2023-01-01文件夹的can-2023-01-01.json文件中,写满100M,则继续写到can-2023-01-01.json.2文件中,依次类推;
3、每天模拟生成的车辆数据中,必须至少包含20辆车的数据,即要含有20个车架号(一个车架号表示一辆车,用字符串表示);
4、每天生成的数据中要有少量(20条左右)重复数据(所有字段都相同的两条数据则认为是重复数据),且同一辆车的两条数据的数据生成时间间隔两秒;
5、每天生成的数据中要混有少量前几天的数据(即数据生成时间不是当天,而是前几天的)。
生成数据可看模拟生成新能源车辆数据,
链接: 模拟生成新能源车辆数据
本次博客主要讲解如果在Linux每天凌晨3点定时启动运行程序。
下面是模拟新能源汽车数据的源码:
// 模拟生成新能源汽车数据
import random
import datetime
import jsondef get_vin(number: int) -> list:"""用来生成指定数量的车架号param:number 生成多少量车的数据return: 返回一个列表"""vin_set = set() # 创建一个空集合for i in range(number):vin = ''.join(random.choices('0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ', k=17)) # 车架号if vin not in vin_set:vin_set.add(vin)return list(vin_set)class GenerationData:def __init__(self, vin):self.vin = vinself.mileage = round(random.uniform(200, 50000), 2) # 行驶总里程# 随机初始化电量self.soc = round(random.uniform(10, 100), 2) # 剩余电量SOC# 需要混入少量前几天的数据(让其在今天和前几天中选择,但被选中的几率极低)self.now_day = random.choices([(datetime.datetime.now() - datetime.timedelta(days=random.randint(1, 3))),datetime.datetime.now()], weights=[0.05, 0.95])[0]# 随机选取司机用车时间(或充电的时间)self.use_car_time = \random.choices([self.get_random_date(0, 23), self.get_random_date(8, 11), self.get_random_date(16, 22)],weights=[0.2, 0.4, 0.4])[0] # 模拟这个时间段用车的人较多# 低点预警self.soc_low_alarm = '电量正常' if self.soc >= 30 else '电量低于30%'# 用于保证数据为当天的数据self.time_compare = datetime.datetime.combine(self.now_day.date(), datetime.time(23, 59, 50))@staticmethoddef get_random_speed():"""用来随机获取车速"""speed1 = random.randint(0, 60)speed2 = random.randint(61, 90)speed3 = random.randint(91, 120)speed = random.choices([speed1, speed2, speed3], weights=[0.6, 0.3, 0.1])[0]return speeddef get_random_date(self, start: int, end: int):"""用来生成当天的随机时间param:start 起始时间(小时)param:end 结束时间(小时)return: 当天的随机时间"""# 生成随机的小时数、分钟数和秒数,并构造时间对象random_time = datetime.time(random.randint(start, end), random.randint(0, 59), random.randint(0, 59))# 构造完整的时间对象,包含日期和时间random_datetime = datetime.datetime.combine(self.now_day.date(), random_time)return random_datetime@staticmethoddef get_travel_time():"""随机获取一个随机时间(利用随机权重来设置)"""random_hour_list = [0, 1, 2, random.randint(3, 5), random.randint(5, 8), random.randint(8, 10),random.randint(10, 15), random.randint(15, 23)]random_hour = random.choices(random_hour_list, weights=[0.7, 0.3, 0.2, 0.15, 0.1, 0.05, 0.03, 0.01])[0]random_time = datetime.time(random_hour, random.randint(0, 59), random.randint(0, 59))return random_timedef if_not_charge(self, choose_charge_or_not):data_list = []steer_time = self.get_travel_time() # 随机获取一个驾驶时间print("司机本次开车", steer_time)seconds = (steer_time.hour * 60 + steer_time.minute) * 60 + steer_time.second # 将驾驶时间转换为秒数flag = 0 # 立一个旗帜来判断是否达到驾驶时间print("司机的用车时间为:", self.use_car_time)while flag <= seconds:speed = self.get_random_speed() # 随机生成0-130的车速,但侧重于0-60的车速if speed == 0: # 模拟行驶中可能会停住status = '停车中' # 设置车辆状态for i in range(random.randint(0, 50)): # 模拟停车self.use_car_time += datetime.timedelta(seconds=2) # 每两秒更新一次时间if self.use_car_time > self.time_compare: # 保证生成的是今天的数据breakdata = {'车架号': self.vin,'行驶总里程': self.mileage,'车速': speed,'车辆状态': status,'充电状态': choose_charge_or_not,'剩余电量SOC': self.soc,'SOC低报警': self.soc_low_alarm,'数据生成时间': self.use_car_time.strftime('%Y-%m-%d %H:%M:%S')}data_list.append(data)flag += 2else:status = '行驶中'# 假设每两秒随机跑10-60米run_mileage = random.uniform(0.01, 0.06) # 因为速度是随机生成的,计算起来会不符合逻辑,那么这两秒跑了远也随机吧self.mileage += run_mileage # 更新行驶里程consume = run_mileage * 0.1 # 消耗电量self.soc -= consume # 更新剩余电量if self.soc <= 10: # 电量小于10停止行驶breakself.soc_low_alarm = '电量正常' if self.soc > 30 else '电量低于30%' # 低电提示# 加上时间差2秒self.use_car_time += datetime.timedelta(seconds=2)if self.use_car_time > self.time_compare: # 保证生成的是今天的数据breakdata = {'车架号': self.vin,'行驶总里程': self.mileage,'车速': speed,'车辆状态': status,'充电状态': choose_charge_or_not,'剩余电量SOC': self.soc,'SOC低报警': self.soc_low_alarm,'数据生成时间': self.use_car_time.strftime('%Y-%m-%d %H:%M:%S')}data_list.append(data)flag += 2print("本次用完车后的时间:", self.use_car_time)return data_listdef if_charge(self, choose_charge_or_not):data_list = []status = '停车中' # 默认停车中speed = 0 # 车速=0# 这时候就要考虑车主要充多电多久(随机生成充电时间)charge_timme = self.get_travel_time()print("司机本次充电时间", charge_timme)seconds = (charge_timme.hour * 60 + charge_timme.minute) * 60 + charge_timme.second # 将充电时间转换为秒数flag = 0print("司机开始充电时间为:", self.use_car_time)print("未充电前电量为:", self.soc)if self.soc < 90: # 如果此时车的电量是大于90的,那么就没有充电的必要了while flag <= seconds:if self.soc < 100: # 确保电量不会超过100self.soc_low_alarm = '电量正常' if self.soc > 30 else '电量低于30%' # 低电提示self.soc += 2 * (1 / 60) # 充电效率跟充电桩有一定因素,暂不考虑太多,就假设1分钟充1%的电self.use_car_time += datetime.timedelta(seconds=2) # 每两秒更新一次时间if self.use_car_time > self.time_compare: # 保证生成的是今天的数据breakdata = {'车架号': self.vin,'行驶总里程': self.mileage,'车速': speed,'车辆状态': status,'充电状态': choose_charge_or_not,'剩余电量SOC': self.soc,'SOC低报警': self.soc_low_alarm,'数据生成时间': self.use_car_time.strftime('%Y-%m-%d %H:%M:%S')}data_list.append(data)flag += 2else:breakprint("司机结束充电时间为:", self.use_car_time)print("充电结束后电量为:", self.soc)return data_listdef choose_whether_charge(self):charging = ['未充电', '充电中']if self.soc < 30:choose_charge_or_not = random.choices(charging, weights=[0.2, 0.8])[0] # 如果电量小于30,则选择充电的就有80%的几率选择充电else:choose_charge_or_not = random.choices(charging, weights=[0.8, 0.2])[0] # 反之就有80%选择不充电return choose_charge_or_notdef generation_data(self):data_list = []# 选择是充电choose_charge_or_not = self.choose_whether_charge()while True:if self.use_car_time > self.time_compare: # 保证生成的是今天的数据breakif choose_charge_or_not == '未充电':list1 = self.if_not_charge(choose_charge_or_not)data_list.append(list1) # 将列表合并# 退出循环即熄火,熄火之后又面临后续是否还需要用车# 有三种可能:在随机时间后用车,在随机时间后充电,今天不在用车if self.soc < 30:weights = [0.1, 0.5, 0.4]else:weights = [0.5, 0.1, 0.4]choose_may = random.choices(['随机时间后用车', '随机时间后充电', '今天不在用车'], weights=weights)[0]if choose_may == '随机时间后用车': # 随机时间后用车,就将司机上次用完车后的时间+上随机时间random_time = self.get_travel_time()print(random_time, "后用车")seconds = (random_time.hour * 60 + random_time.minute) * 60 + random_time.secondself.use_car_time += datetime.timedelta(seconds=seconds) # 更新下次用车时间continue # 结束本次循环,等待下次用车elif choose_may == '随机时间后充电':choose_charge_or_not = '充电中' # 修改充电状态random_time = random.randint(10, 500)print(random_time, "后用充电")self.use_car_time += datetime.timedelta(seconds=random_time) # 更新下次用车时间if self.use_car_time > self.time_compare: # 保证生成的是今天的数据breakcontinue # 结束本次循环,等待下次用车else:print("今天不再用车")breakelse: # 这种情况:车在充电list2 = self.if_charge(choose_charge_or_not)data_list.append(list2) # 将列表合并# 充好电后,之后又面临后续是否还需要用车# 有两种可能:随机时间后用车,今天不在用车choose_may = random.choices(['随机时间后用车', '今天不在用车'], weights=[0.7, 0.3])[0]if choose_may == '随机时间后用车': # 随机时间后用车,就将司机上次用完车后的时间+上随机时间choose_charge_or_not = '未充电' # 修改充电状态random_time = self.get_travel_time()print(random_time, "后用车")seconds = (random_time.hour * 60 + random_time.minute) * 60 + random_time.secondself.use_car_time += datetime.timedelta(seconds=seconds) # 更新下次用车时间if self.use_car_time > self.time_compare: # 保证生成的是今天的数据breakcontinue # 结束本次循环,等待下次用车else:print("今天不在用车")breakreturn data_listif __name__ == '__main__':vins_list = get_vin(1) # 生成50辆车的数据vin1 = vins_list.pop() # 随机取出一辆,先模拟一辆车gd = GenerationData(vin1)data_li = gd.generation_data()print(data_li)将数据写入hdfs的源码:
from time import sleepfrom hdfs import InsecureClient
from generation_data import GenerationData
import random
import json
import datetimedef get_vin(number: int) -> list:"""用来生成指定数量的车架号:param:number 生成多少量车的数据:return: 返回一个列表"""vin_set = set() # 创建一个空集合for i in range(number):vins = ''.join(random.choices('0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ', k=17)) # 车架号if vins not in vin_set:vin_set.add(vins)return list(vin_set)def create_folder_if_not_exists(file_path):"""判断文件是否存在,不存在则创建:param file_path:文件位置:return:"""if client.status(file_path, strict=False) is None:client.makedirs(file_path, permission=755) # 创建目录并将数据修改权限为755print(f"目录{file_path}创建成功!")else:print("目录已存在")def add_repeating_data(data_list: list):"""用于向列表中添加重复数据随机添加5-15条不等列表内的数据需要是字典:param data_list: 需要添加重复数据的列表:return:无返回值,对传进来的数据进行隐形操作"""# sample()函数从0到列表总长度之间随机选择random.randint(20,100)整数作为重复的数据下标try:repeat_indices = random.sample(range(len(data_list)), random.randint(1, 5))print(repeat_indices)for i in repeat_indices:# 返回字典中所有键值对的元素,以便同时访问字典中所有键和它们对应的值repeat_data = {k: v for k, v in data_list[i].items()}print(data_list[i], "下面添加了:", repeat_data)data_list.insert(i + 1, repeat_data) # 将数据插入原数据的下一行except Exception as e:print("添加失败:", e)def split_data(one_vin_data, null_list: list) -> list:"""并随机添加行程重复数据拆分传入的列表数据,将列表数据拆分为,5个数据为一个子列表:param:one_vin_data:一辆车架号的列表数据:param:null_list:一个空列表:return: 二维列表(每个列表5个数据)"""n = 5 # 每个子列表包含10个元素for tmp_list in one_vin_data:"""随机选择本次行程是否会出现重复数据,出现:添加5-20条数据用于选择是否出现重复数据,出现的概率为3%出现返回True不出现返回False"""flag = random.choices([True, False], weights=[0.05, 0.95])[0]if flag: # 出现:添加5-15条数据add_repeating_data(tmp_list)# 将数据拆分为10个数据为一个小列表for i in range(0, len(tmp_list), n):null_list.append(tmp_list[i:i + n])return null_listif __name__ == '__main__':client = InsecureClient('http://192.168.88.129:50070', user='root')NOW_DATA_STR = datetime.datetime.now().date().strftime('%Y-%m-%d') # 当天日期FILE_PATH = f'/car_data/{NOW_DATA_STR}' # 需要的目录# threshold = 100 * 1024 * 1024 # 文件大小阈值为100MBthreshold = 100 * 1024 # 设置文件阈值index = 2 # 文件后缀# 创建文件夹create_folder_if_not_exists(FILE_PATH)data_path = FILE_PATH + f'/car-{NOW_DATA_STR}.json' # 初始化文件地址# 生成车架号vin = get_vin(1)# 循环写入数据 -> 5条数据5条数据的写for i in range(len(vin)):tmp_list = [] # 用一个临时列表来临时存储数据# 生成数据gd = GenerationData(vin[i])one_vin_data_list = gd.generation_data() # 生成一辆车的数据# 随机添加重复数据,并切割数据列表,所有的子列表中有5个数据data_list = split_data(one_vin_data_list, tmp_list) # -> 二维列表# 循环子列表for son_list in data_list: # 一个列表一个列表的写入# 判断文件是否存在,不存在则返回Noneif client.status(data_path, strict=False):# 文件存在,追加内容with client.write(data_path, append=True, encoding='utf-8') as writer:# client.set_permission(data_path, permission='777') # 修改文件权限for data in son_list:# 转为json数据data = json.dumps(data, ensure_ascii=False)# 将编码后的字符串写入文件中,并添加换行符writer.write(data + '\n')writer.flush() # 立即将缓存的数据全部写入文件file_info = client.content(data_path) # 获取文件信息file_size = file_info['length'] # 获取文件大小# print(file_size)if file_size > threshold: # 如果文件大于阈值则更新文件地址data_path = FILE_PATH + f'/car-{NOW_DATA_STR}.json.{index}'index += 1else: # 不存在则开一个新的文件with client.write(data_path, encoding='utf-8') as writer:for data in son_list:# 转为json数据data = json.dumps(data, ensure_ascii=False)# 将编码后的字符串写入文件中,并添加换行符writer.write(data + '\n')writer.flush() # 立即将缓存的数据全部写入文件2、Linux定时运行任务
2.1 crontab简介
crontab是一个用于在Linux或类Unix系统上执行定期任务的命令行工具。它使用一个特定的语法定义任务的执行计划,可以让用户定期运行脚本或程序。
2.2 参数说明
当使用命令crontab时,可以使用多个参数来管理和控制定时任务。以下是一些常用参数的详细说明:
-e:编辑当前用户的crontab文件。如果还没有crontab文件,会新建一个。-l:列出当前用户的crontab文件中所有的定时任务。-r:删除当前用户的crontab文件。-u:在执行操作时指定要操作的用户名,而不是当前用户。例如,可以使用-u root来操作root用户的crontab文件。
下面是用于指定任务执行计划的时间参数含义:
*:通配符,表示不限制这个位置的取值,例如* * * * *表示每分钟都执行。,:逗号用于分隔多个时间值,例如0 1,3,5 * * *表示每天的1点、3点和5点执行。-:横杠用于定义一个时间范围,例如0 2-4 * * *表示每天的2点、3点和4点执行。/:斜线表示时间间隔,例如*/5 * * * *表示每5分钟执行一次。
时间参数有5个位置,分别代表分钟、小时、日、月和星期。每个位置的取值范围如下:
- 分钟:0~59。
- 小时:0~23。
- 日:1~31。
- 月:1~12。
- 星期:0~7(0和7都代表周日)。
例如,0 1 * * 1-5表示每周一到周五的1点执行该任务。
2,3 定时运行程序
我已经将生成数据的python文件打包成了.exe的可执行文件,并上传到了linux,如果有不会的小伙伴可以看一看后面的内容在回来写这一步。
感兴趣的小伙伴可以了解一下,因为需要安装很多的插件,这里不在演示,主要讲解如果在windows下定时运行
3 windows下定时运行
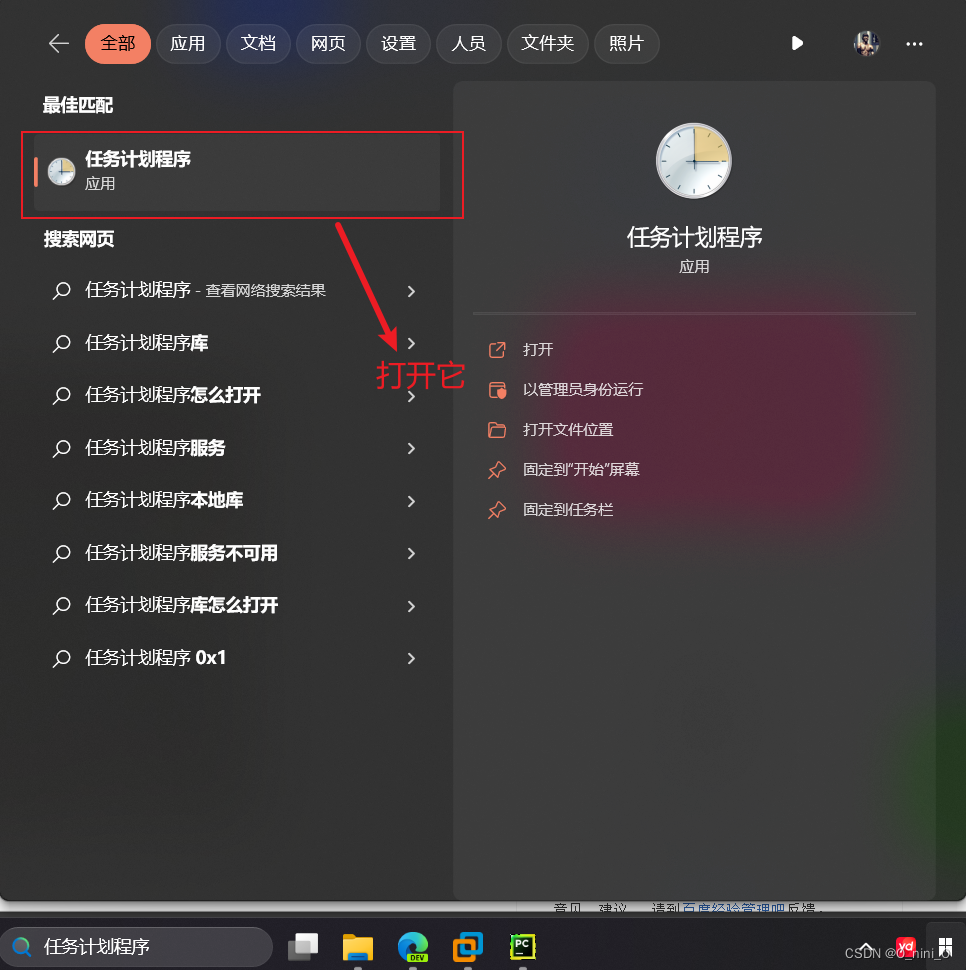
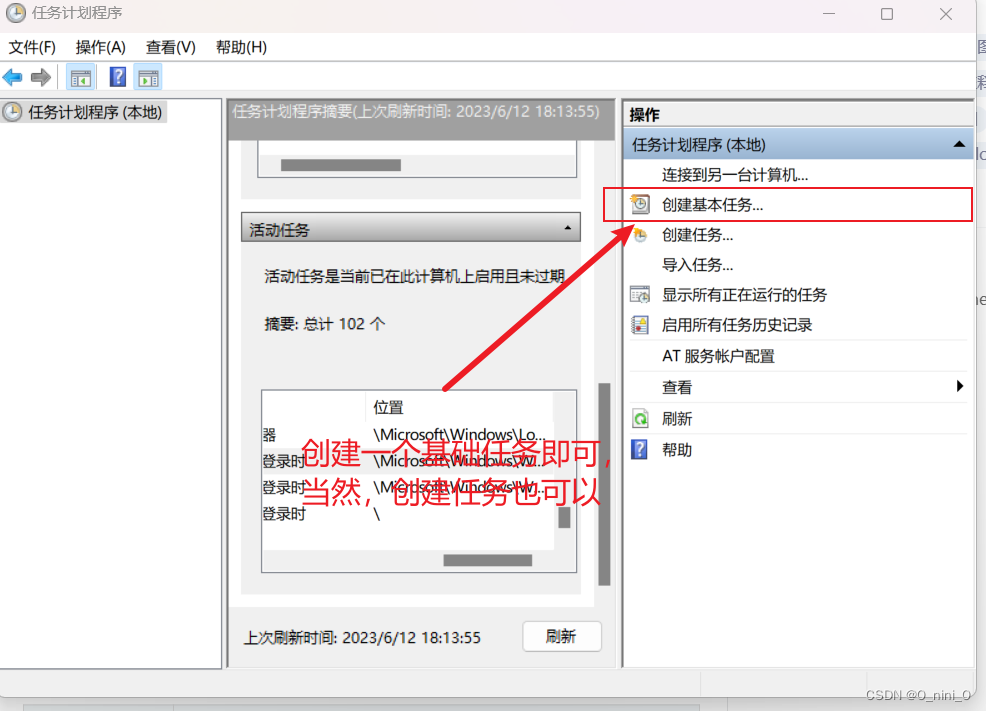
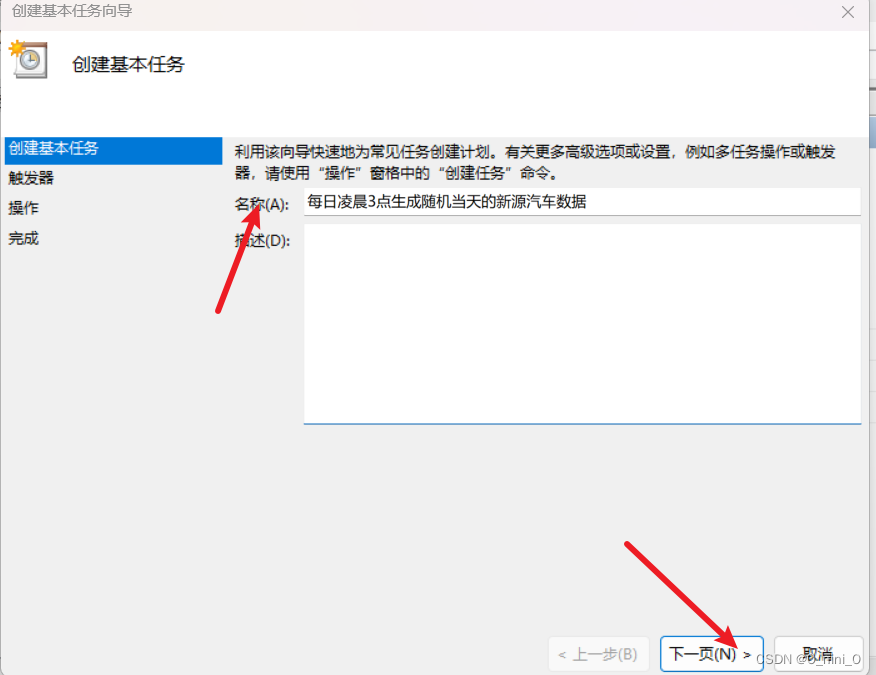
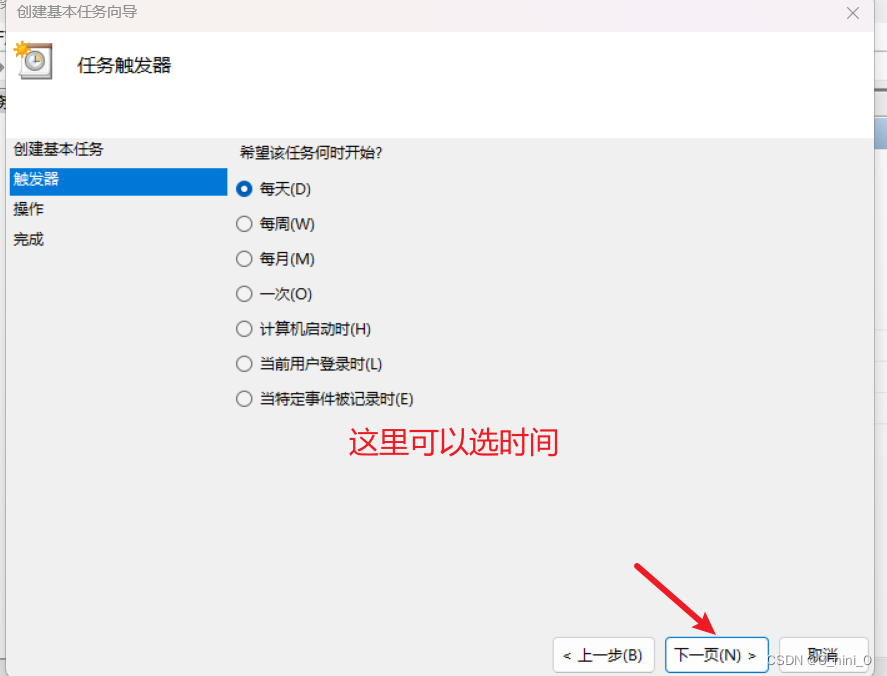
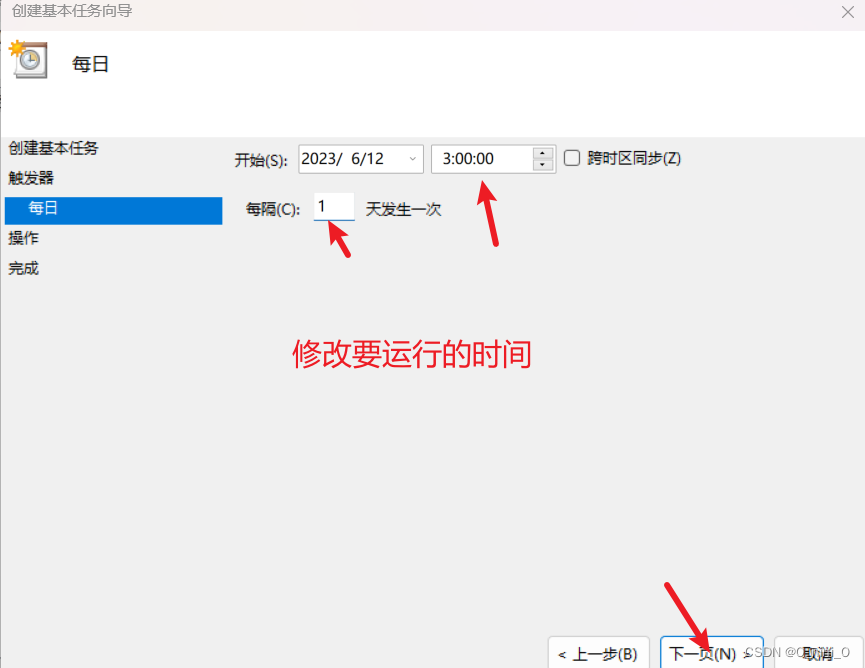
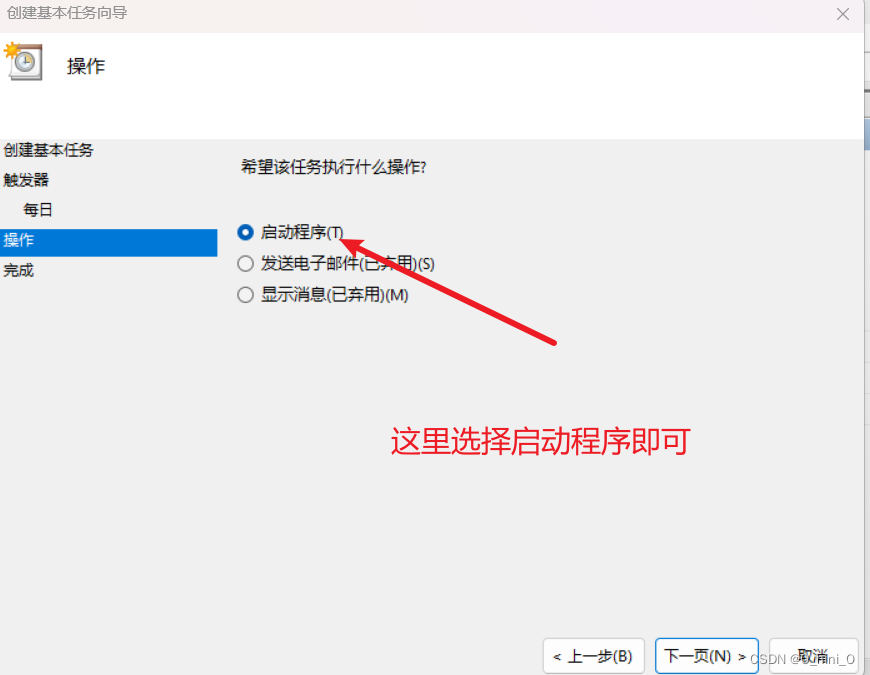
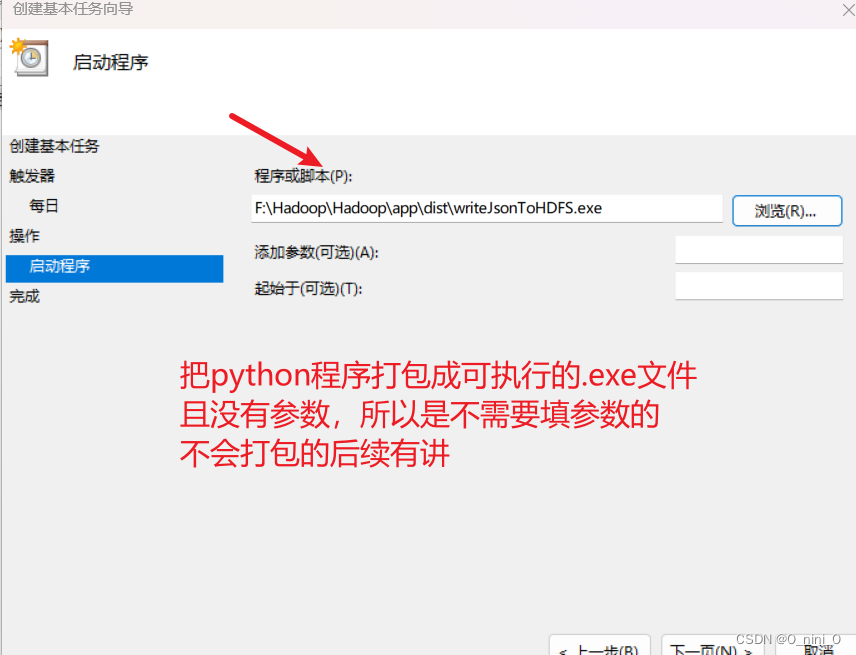
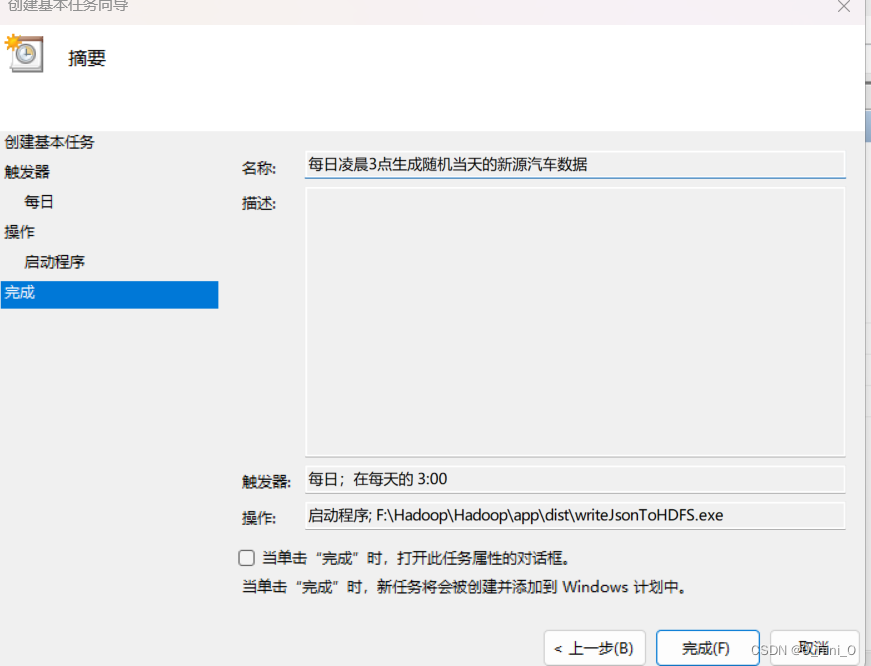
确认无误就可以点完成啦
测试的时候我们可以改一下时间。
到此项目就完成了,后面讲一下如何讲python文件打包成可执行的.exe
4 将案例打包成.exe执行文件
3.1pyInstaller简介
PyInstaller是一个用于将Python代码打包为独立可执行文件的工具,可以将Python脚本转换为单个可执行文件,无需Python解释器安装。使用PyInstaller能够更方便地进行Python程序的部署和共享,而不需要担心环境问题。
3.1.2 常用指令
| 指令 | 作用 |
|---|---|
| -F,-onefile | 产生单个的可执行文件 |
| -D,–onedir | 产生一个目录(包含多个文件)作为可执行程序件 |
3.2 实现过程
- 安装pyinstaller
pip install pyinstaller
- 进入需要打包的文件夹目录执行cmd
- 执行命令
pyinstaller -F main.py
温馨提示,main为你需要打包得主函数。我这里得主函数是writeJsonToHDFS.py,所以我打包这个即可
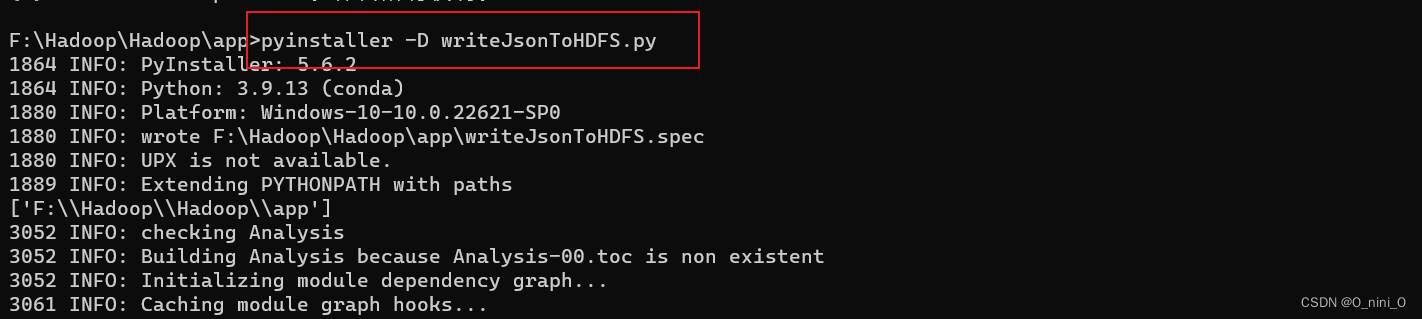

然后你就可以在文件夹看到
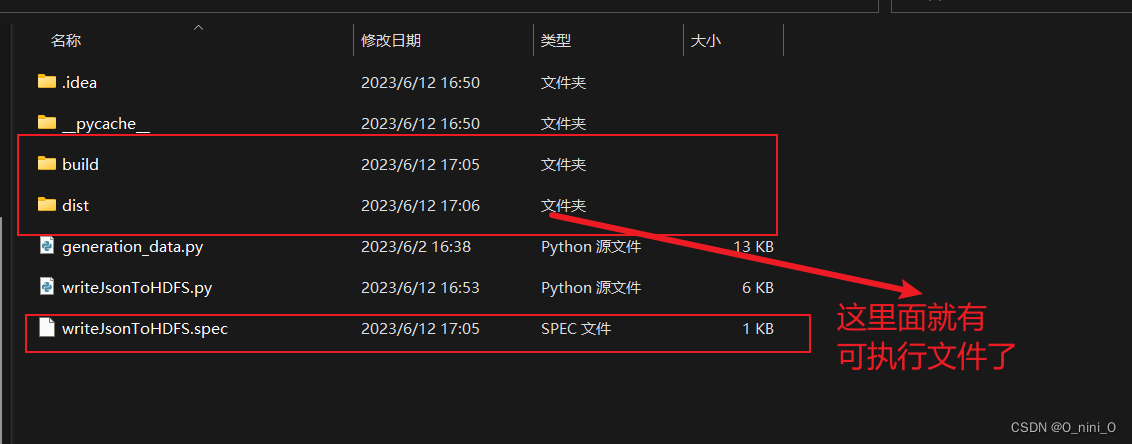

如果没有执行文件,就说明打包失败了
5、在Linux上下载Wine
因为我们打包的是exe文件,想要在linux下运行exe文件我们就可以通过Wine来完成,当然还有其他方法,比如:
1、使用Qemu:Qemu是一款模拟器,可以模拟出一个虚拟的Windows环境,用户可以在这个虚拟的Windows环境中安装并运行exe文件,从而在Linux系统上实现exe文件的运行。
2、使用VirtualBox:VirtualBox是一款虚拟机软件,它可以在Linux系统中安装Windows系统,用户可以在这个Windows系统中安装并运行exe文件,从而在Linux系统上实现exe文件的运行。
这里只讲解用wine来实现:
是一款可在其他操作系统平台(如Linux,MAC,BSD等待)运行windows程序的兼容软件,有人也把它称为Windows模拟器,可以完美运行众多在Windows系统下的软件。
4.1 安装win
不会安装的可以看一看这里
链接: win安装教程
这里建议选择离线安装,因为会比较快点。
离线安装可能出现的问题:
在解压过程中可能会出现这样的报错,那是因为没有安装dpkg命令
这是安装教程:
链接: 安装dpkg命令

总结
主要讲解了如何将python程序打包成.exe的可执行文件,并且讲解如何实现定时运行程序。
这篇关于widows定时开启任务crontab(参数讲解)hadoop案例(模拟生成新能源车辆数据)总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





