本文主要是介绍如何降低 Cache 失效率,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
看了酷壳上 @我的上铺叫路遥 投稿的"七个示例科普CPU Cache",收获比较多。建议阅读。
另外,我重新翻阅了下《计算机系统结构》的书,把 Cache 那章再阅读了下!对这块知识点的理解有了新的感受。这里简单整理了部分降低 Cache 失效率的方法,也算复习下。
降低 Cache 失效率的方法
许多相关 Cache 的研究都致力于降低 Cache 的失效率。
按照产生失效的原因不同,可以把失效分为以下3类(简称为"3C"):
(1). 强制性失效 (Compulsory miss): 当第一次访问一个块时,该块不在 Cache 中,需从下一级存储中调入 Cache,这就是强制性失效。这种失效也称为冷启动失效,或首次访问失效。// 增加块大小,预取
(2). 容量失效(Capacity miss):如果程序执行时所需的块不能全部调入 Cache 中,则当某些块被替换后,若又重新被访问,就会发生失效。这种失效称为容量失效。// 增加容量,会有抖动现象。
(3). 冲突失效(Conflict miss):在组相联或直接映像 Cache 中,若太多的块映像到同一组(块)中,则会出现改组中某个块被别的块替换、然后又被重新访问的情况。这就是发生了冲突失效。这种失效也称为碰撞失效(collision)或干扰失效 (interference)。// 提高相联度
SPEC92 基础测试程序给出了这三种失效在不同容量不同相联度下的失效率情况略。总结的情况如下:
- 相联度越高,冲突失效就越少。
- 强制性失效和容量失效不受相联度的影响。
- 强制性生效不受 Cache 容量的影响,但容量失效却随着容量的增加而减少。
- 表中的数据符合 2:1 的 Cache 经验规则,即大小为N的直接映像 Cache 的失效率约等于大小为 N/2 的 2 路组相联 Cache 的失效率
编译器优化
前面所介绍的技术(增加块大小、增加 Cache 容量、提高相联度、伪相联、硬件预取以及预取指令等)都需要改变或者增加硬件。下面介绍的方法,无需对硬件做任何改动就可以降低失效率。或许,这也是能对我们的程序效率有帮助的地方!
我们能很容易地重新组织程序而不影响程序的正确性。例如,把一个程序中的几个过程重新排序,就可能会减少冲突失效,从而降低指令失效率。McFarling 研究了如何使用记录信息来判断指令组之间可能发生的冲突,并将指令重新排序以减少失效。他发现,这样可将容量为 2KB、块大小为 4KB 的直接映像指令 Cache 的失效率降低 50%;对于容量为 8KB 的 Cache,可将失效率降低75%。他还发现当能够是某些指令根本就不进入 Cache 时,可以得到最佳性能。但即使不这么做,优化后的程序在直接映像 Cache 中的失效率也低于未优化程序在同样大小的 8 路组相联映像 Cache 中的失效率。
数据对存储位置的限制比指令对存储位置的限制还要少,因此更便于调整顺序。我们对数据进行变换的目的是改善数据的空间局部性和时间局部性。例如,可以把对数据的运算改为对存放在同一 Cache 块中的所有数据进行操作,而不是按照程序员原来随意书写的顺序访问数组元素。
1. 数组合并 ( merging arrays )
这种技术通过提高空间局部性来减少失效次数。有些程序同时用相同的索引来访问若干数组中的同一维。这些访问可能会相互干扰,导致冲突失效。我们可以这样来消除这种危险:将这些相互独立的数组合并成为一个复合数组,使得一个 Cache 块中能包含全部所需的元素。
/* 修改前 */
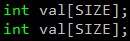
/* 修改后 */
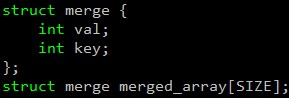
这个例子有一个有趣的特点:如果程序员能正确地使用记录数组,他就能获得与本优化相同的益处。
2. 内外循环交换 ( loop interchange )
有些程序中含有嵌套循环,程序没有按照数据在存储器中存储的顺序进行访问。在这种情况下,只要简单地交换循环的嵌套关系,就能使程序按数据在存储器中存储的顺序进行访问。和前一个例子一样,这种技术也是通过提高空间局部性来减少失效次数,重新排列访问顺序使得在一个 Cache 块被替换之前,能最大限度地利用块中的数据。
/* 修改前 */

/* 修改后 */

修改前程序以100个字的跨距访问存储器,而修改后的程序顺序地访问一个 Cache 块中的元素,然后再访问下一块中的元素。这种优化技术在不改变执行的指令条数的前提下,提高了 Cache 的性能。
简单测试:
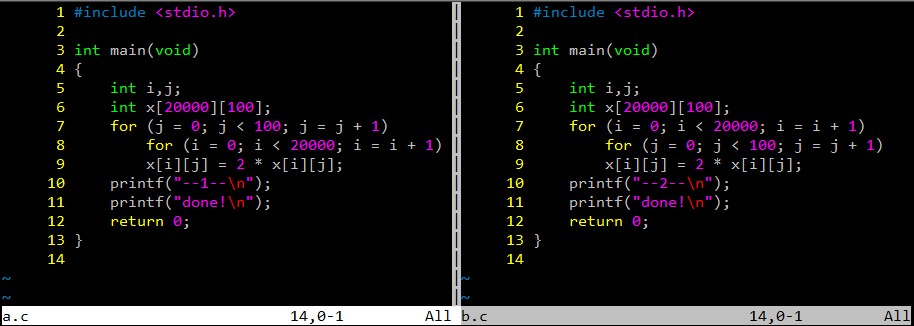
PS: 可以编译执行下,有 0.02 秒的差异。
3. 循环融合 ( loop fusion )
有些程序含有几部分独立的程序段,它们用相同的循环访问同样的数组,对相同的数据做不同的运算。通过将它们融合为单一的循环,能使读入 Cache 的数据在被替换出去之前,得到反复的使用。和前面的两种技术不同,这种优化的目标是通过改进时间局部性来减少失效次数。
/* 修改前 */
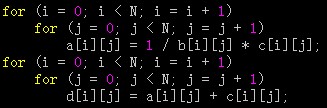
/* 修改后 */
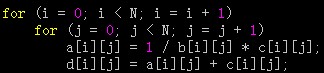
修改前的程序在两个地方访问数组 a 和 c,一次是在第一个循环里,另一次是在第二个循环里。两次循环分隔较远,可能会产生重复失效,即在第一个循环中访问某个元素失效之后,虽已将相应块调入 Cache,但在第二个循环中再次访问该元素时,还可能产生失效。而在修改后的程序中,第二条语句直接利用了第一条语句访问 Cache 的结果,无需再到存储器去取。
4. 分块
这种优化可能是 Cache 优化技术中最著名的一种,它也是通过改进时间局部性来减少时效。下面仍考虑对多个数组的访问,有些数组是按行访问,而有些规则是按列访问。无论数组是按行优先还是按列优先存储,都不能解决问题,因为在每一次循环中既有按行访问也有按列访问。这种正交的访问意味着前面的变换方法,如内外循环交换,对此均无能为力。
分块算法不是对数组的整行或整列进行访问,而是对子矩阵或块进行操作。其目的仍然是使一个 Cache 块在被替换之前,对它的访问次数达到最多。下面这个矩阵乘法程序有助于我们理解为什么要采用这种优化技术。(此略)
... More
这篇关于如何降低 Cache 失效率的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[项目][CMP][Thread Cache]详细讲解](https://i-blog.csdnimg.cn/direct/9b45402cc79244b08d14c60f1767084e.png)
![[项目][CMP][Central Cache]详细讲解](https://i-blog.csdnimg.cn/direct/69b6f4cebe024adb8138522b95b1571d.png)