本文主要是介绍爬取私募排排网历史净值和破解加密数值,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爬取私募排排网历史净值和破解加密数值
近期爬取了私募排排网上的历史净值,写一下爬取过程中的一些心得体会。
上面有很多的难点,例如直接利用selenium会被检测出反爬、爬取的数值被加密(页面上看到的和html中不一样,多了一些隐藏值)等等。爬取的方法主要就是selenium、正则、beautiful soup。这里先把这里使用的库导入。
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
import pandas
import time
import re
from lxml import html
from selenium.webdriver.common.action_chains import ActionChains # 导入鼠标事件库
总体流程:打开网页,然后登录,到达需要解析的页面,得到源码,然后破解加密,最后输出数据保存 在excel中。
一、开启网页
有的网站直接使用selenium就可以开启,例如
driver = webdriver.Chrome() # 启动驱动器
driver.get('https://www.simuwang.com/user/option') # 加载网站
但是在这里就会出现以下情况,那是因为如果直接开启网页,就会被发现是爬虫。
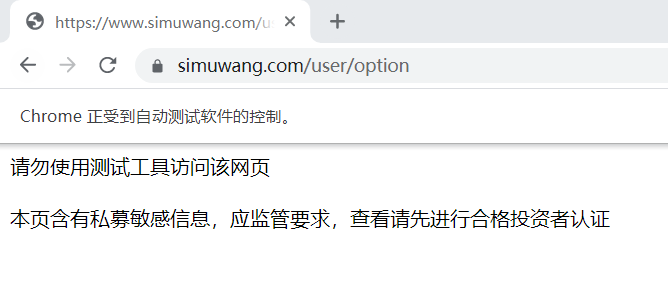
解决这个问题要使用以下代码
driver = webdriver.Chrome() # 启动驱动器# 谷歌浏览器 79和79版本后防止被检测
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""
})
driver.get('https://www.simuwang.com/user/option') # 加载网站
最后就能完美的开启网页了。
注意,这里设置开发者模式也是不可行的!
二、selenium定位元素解析网页
在进入网页之后,就开始元素定位。selenium定位一共有八个name,id,link_text,partial_link_text,class_name,xpath,css,tag_name。其中最少也要掌握xpath或者css一种方法(使用这两种方法基本上能解决所有的定位)。
详细用法,可以访问我的另一篇文章,也是关于selenium爬虫,里面详细介绍了selenium八大定位的用法。手把手Selenium安装使用及实战爬取前程无忧招聘网站(一)_Panda4u的博客-CSDN博客
在这里就讲讲selenium这里的用法,我使用的方法是xpath。
1. 输入账号和输入密码点击登录
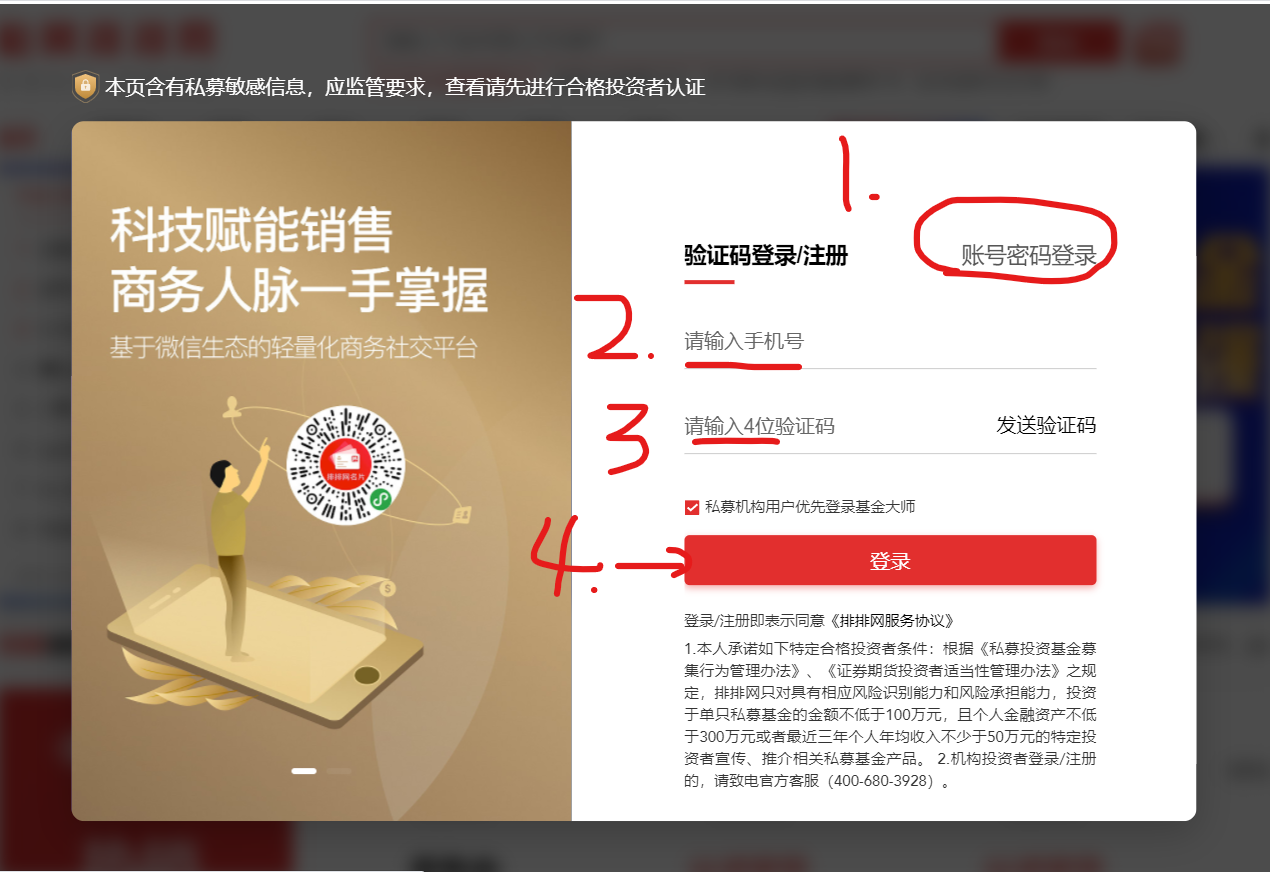
driver.find_element(By.XPATH,'//button[@class="comp-login-method comp-login-b2"]').click() #点击账号密码登录
driver.find_element(By.XPATH,'//input[@name="username"]').send_keys('xxxxxxxxxxxx') # 输入账号
driver.find_element(By.XPATH,'//input[@type="password"]').send_keys('xxxxxxxxxxxx') # 输入密码
driver.find_element(By.XPATH,'//button[@style="margin-top: 65px;"]').click() # 点击登录
补充:
(1). 以后使用定位最好都用By(也就是以上的方法),而driver.find_element_by_xpath(),因 为后面的这种不利于封装。
(2). 元素定位是做什么的?我们为什么要定位元素?有什么用呢?
元素定位就是在html中找到我们在网页中看到内容对应的元素。找到之后可以使用鼠标事 事件和键盘事件,对网页进行人工模拟操作。在这里就是简单的键盘事件send_keys和鼠标 事件click。
2. 叉掉广告,网页后退
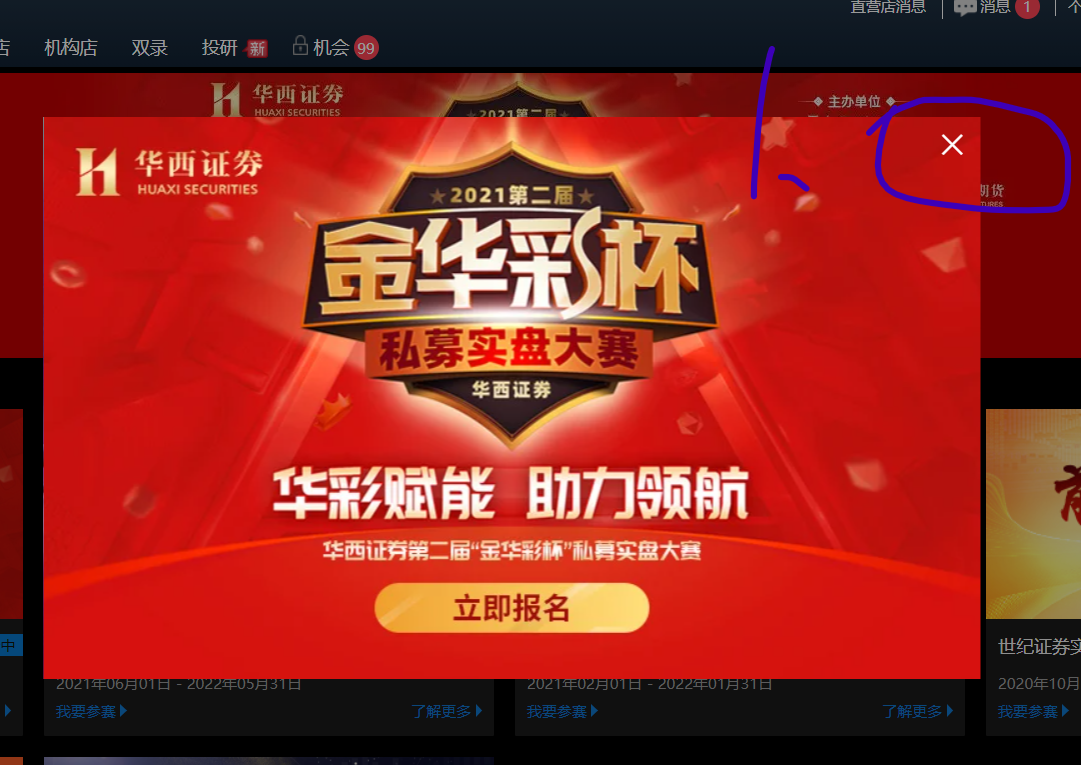
time.sleep(15) # 等待登录时间
driver.find_element(By.XPATH,'//span[@class="el-icon-close close-icon"]').click() # 叉掉广告
driver.back() # 网页后退
补充:
(1). 注意这里必须要sleep几秒。那是因为登录过程需要时间加载,不然会报错。
(2). driver.back()是将当前页面返回上一级。那么driver.forward()前进到上一级。
3. 鼠标悬停点击自选
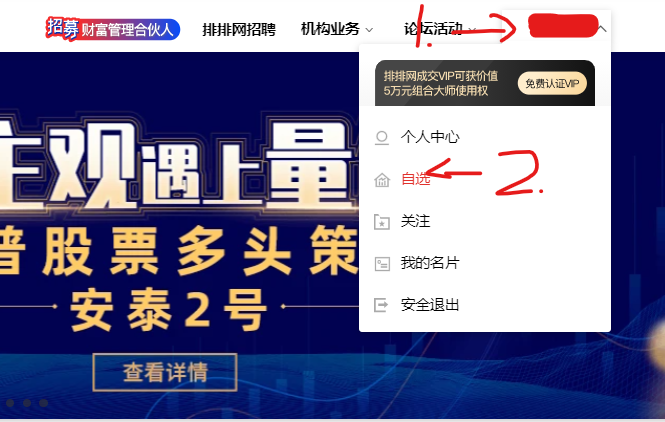
鼠标悬停在用户上,然后点击自选进入网页。
time.sleep(5) # 加载网页需要等待时间
mouse = driver.find_element(By.XPATH,'//div[@class="comp-header-nav-item fz14"]/div/span[@class="ellipsis"]')
ActionChains(driver).move_to_element(mouse).perform() # 悬停鼠标在名片
driver.find_element(By.XPATH,'//a[@class="comp-header-user-item icon-trade"]').click() # 点击自选
这里的悬停操作就是定位用户然后使用ActionChains进行悬停,在悬停中找到自选并点击。
4. 解析网页
经历以上的步骤就来到了我们需要爬取数据的页面了。我们需要的数据在每一个基金里面的历史净值。所以我们先要得到每一个基金的网址,然后进入网站里面进行处理。
# 解析网页
page = driver.page_source
soup = BeautifulSoup(page,'html.parser')list_url = [] # 用于保存目标网站
list_name = [] # 用于保存目标名称
url_a = soup.select('div:nth-child(2) > div.shortName > a') # 找到所爬取的网页
names = soup.select('div> div > div:nth-child(2) > div.shortName > a') # 找到名称
for u in url_a:url = u['href'] # 得到网站list_url.append(url)
for name in names:list_name.append(name.get_text())
这里使用了BeautifulSoup对page进行解析,然后使用select定位找到每个基金的网址和基金名称。
二、对每个基金处理
经过上一步解析网页之后,得到每个基金的网站。现在循环处理这些网址,爬取数据。
1. 解析每个基金网页
解析每个基金网页还是运用driver.get加载网页,利用page_source解析网页。
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""
})
for ind in range(len(list_name)):driver.get(list_url[ind]) # 加载网站
不过在page_source解析网页之前,有一个东西必须要注意!
那就是如果直接解析网页得到的历史净值只有一小部分,是因为历史净值是一个动态的,我们在解析之前需要利用selenium将历史净值这个内嵌框下滑到底,而且这个内嵌框是一个异步加载的(滑动完后,又会出来一段),使用需要多个滑动才能满足条件。

解决问题要点:首先得将历史净值点击,然后定位历史净值框。
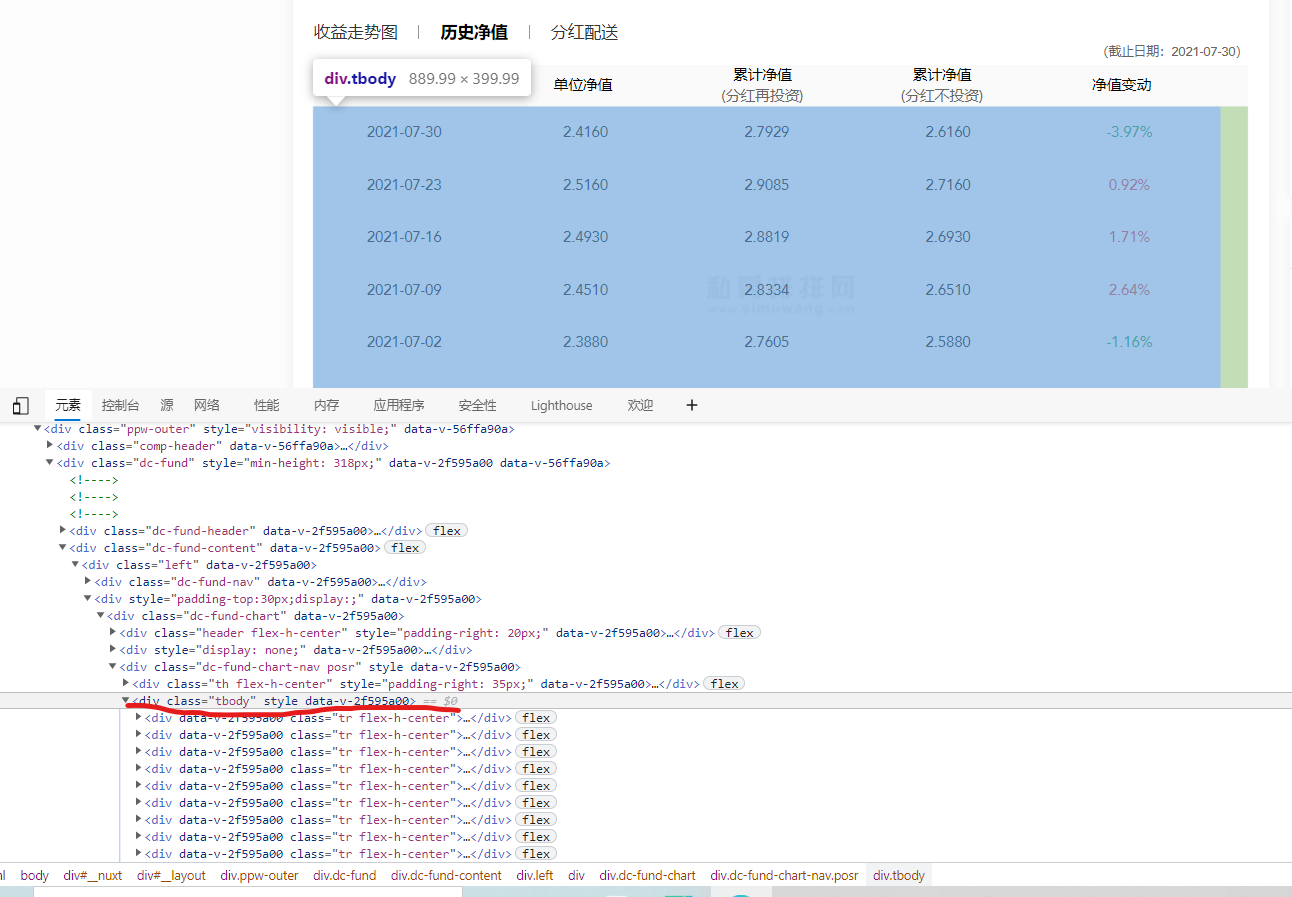
如图已经定位到了内嵌框,下面就开滑动
driver.find_element(By.XPATH,'//div/div[2]/div[2]/div[1]/div[2]/div[1]/div[1]/a[2]').click() # 点击历史净值for i in range(50):js = 'document.getElementsByClassName("tbody")[0].scrollTop=100000' # 在历史净值中滑动,这里滑动50应该是都够了的,如果不够加大就行driver.execute_script(js)time.sleep(0.1) # 防止滑动太快,没有读取到结果page_url = driver.page_source # 解析当前网页
注意 getElementsByClassName(“tbody”)[0] 这里是查找属性class的属性值为tbody,中的第一个元素(一定要带上后面这个0,因为返回的是一个集合。如果滑动的是4个元素就是后面就是3)
下面就是定位docment对象的方法,和css定位一样。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bDmkoTgO-1628908656748)(爬取私募排排网历史净值和破解加密数值.assets/image-20210808190751925.png)]
感兴趣可以看看JavaScript学习链接
http://www.runoob.com/jsref/dom-obj-document.html
2. 解密历史净值中的隐藏值
(1)隐藏值原理
经过上一步就得到了每个基金的网页,接下来就来开始解密。
在解密前我们先来看看它是怎么加密的吧!
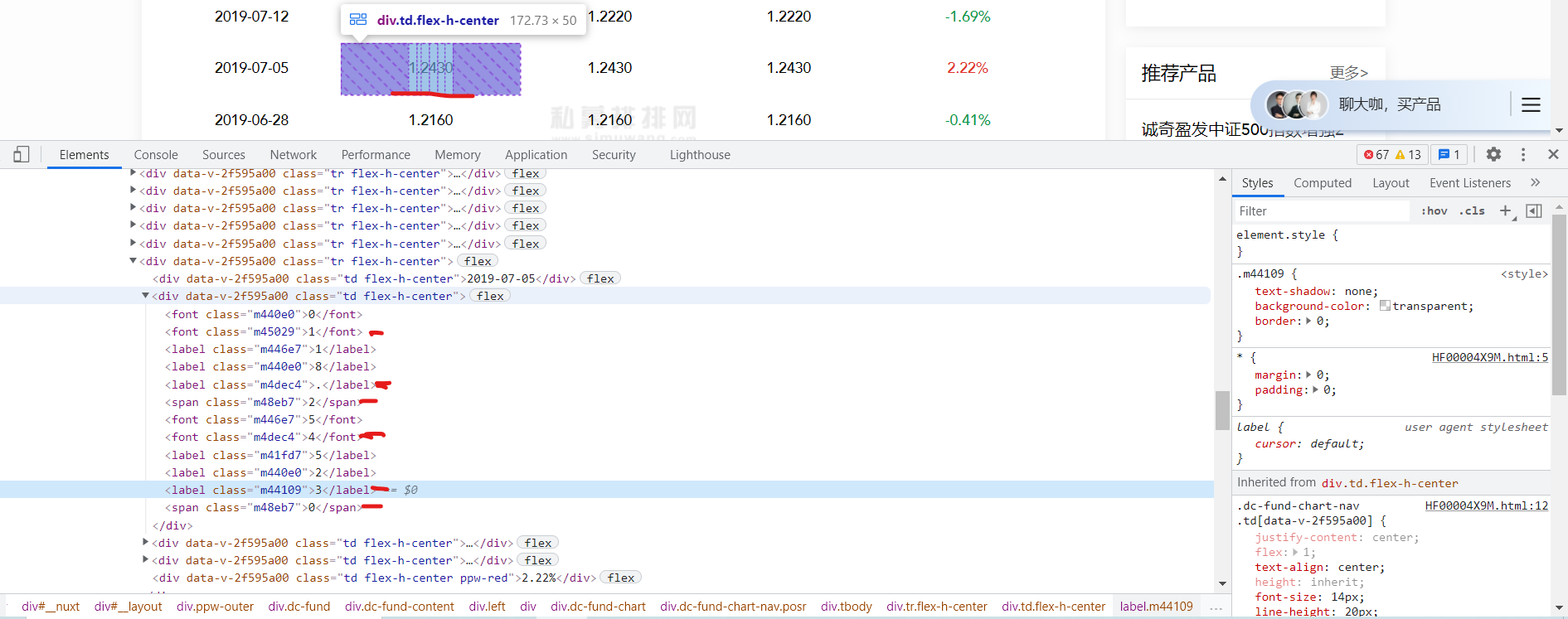
可以看到在html中存在着网页中没有的内容,这个就是加密。
说实话,在这里花费了不少的时间。我先来说说我的思路吧。
-
找规律
在开始尝试找规律,最开始规律就是每个值中的span一定是有用的,但是后来发现有的没有span,然后,然后就没有然后了,直接放弃这种想法了。
-
css偏移
然后就是css偏移就是利用css样式将网页中正常的值乱序。但是发现我们这里的值顺序是正常的,只是多了部分值,所以页排除这种想法。
-
存在隐藏值
最后发现了规律,
存在的值(网页上显示的值)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rRKScm8J-1628908656750)(爬取私募排排网历史净值和破解加密数值.assets/image-20210808200015651.png)]
不存在的值(网页上不显示的值)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PyfCiVCk-1628908656751)(爬取私募排排网历史净值和破解加密数值.assets/image-20210808200204943.png)]
会发现网页上面不存在的值多了 font: 0/0 a 这个值。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hFAoQWnu-1628908656752)(爬取私募排排网历史净值和破解加密数值.assets/image-20210808201653244.png)]
当把 font: 0/0 a 这个边框不勾选了,就会发现网页中会有很多的值中间是有空格的,那么可以得出结论html中多出来的值并不是多余的,它也是存在网页中的,但是它被隐藏了。
然后我们就抓住在这个特点继续找下去。
当我们发现 ENCODE_STYLE 对应的内容就是和找到的规律一样。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bZiFlEQr-1628908656753)(爬取私募排排网历史净值和破解加密数值.assets/image-20210808201017372.png)]
.m440e0{font: 0/0 a;color: transparent;text-shadow: none;background-color: transparent;border: 0;}.m446e7{font: 0/0 a;color: transparent;text-shadow: none;background-color: transparent;border: 0;}.m48eb7{text-shadow: none;background-color: transparent;border: 0;}.m45029{text-shadow: none;background-color: transparent;border: 0;}.m41fd7{font: 0/0 a;color: transparent;text-shadow: none;background-color: transparent;border: 0;}.m4dec4{text-shadow: none;background-color: transparent;border: 0;}.m44109{text-shadow: none;background-color: transparent;border: 0;}
可以去验证,以m440e0为属性值去找元素,可以发现全是隐藏值。同理,m48eb7为属性值去找元素全是真实值。
结论:html中多出来的值并不是多余的,它也是存在网页中的,但是它被隐藏了。这些隐藏值以及真实值在ENCODE_STYLE属性中。所以只需要在ENCODE_STYLE中找存在font: 0/0 a的属性值,即为隐藏值。
(2)代码实现
# 找到隐藏的属性值
def getHideIds(htmlEtree):encode_styles = "".join(htmlEtree.xpath('//div[@id="ENCODE_STYLE"]/style/text()')).replace("\n", "")# 清洗数据,去除连续的空格new_encode_styles = re.sub(" +", "", encode_styles)# 获取全部被隐藏的idhideIds1 = re.findall("\.(\w+) {font: 0/0 a;", new_encode_styles) # 格式化后的htmlhideIds2 = re.findall("\.(\w+){font: 0/0 a;", new_encode_styles) # 未格式化的htmlresult = set(hideIds1 + hideIds2)return result
定义一个函数,调用xpath解析的page_source,返回值为隐藏值的属性值。即类似于m440e0,m41fd7的值。
然后只需要将隐藏值对应的元素找出来就行了。
htmlEtree = etree.HTML(text=htmlData)# 获取被隐藏的id
hideIds = getHideIds(htmlEtree)# 处理数据
divList = htmlEtree.xpath('//div[@class="tr flex-h-center"]')
# print(divList)
tdDivs = []
for div in divList:nextDivs = div.xpath('./div[@class="td flex-h-center"]')for nextDiv in nextDivs:if nextDivs.index(nextDiv) == 0:continuetdDivs.append(nextDiv)resultList = []
for tdDiv in tdDivs:labels = tdDiv.xpath("./*")nowResultList = []for label in labels:classStr = label.xpath("./@class")[0]if classStr not in hideIds:nowResultList.append(label.xpath("./text()")[0])resultList.append("".join(nowResultList))# print(resultList)
# for reslut in resultList:
# print(reslut)
三、将所有数据写入excel
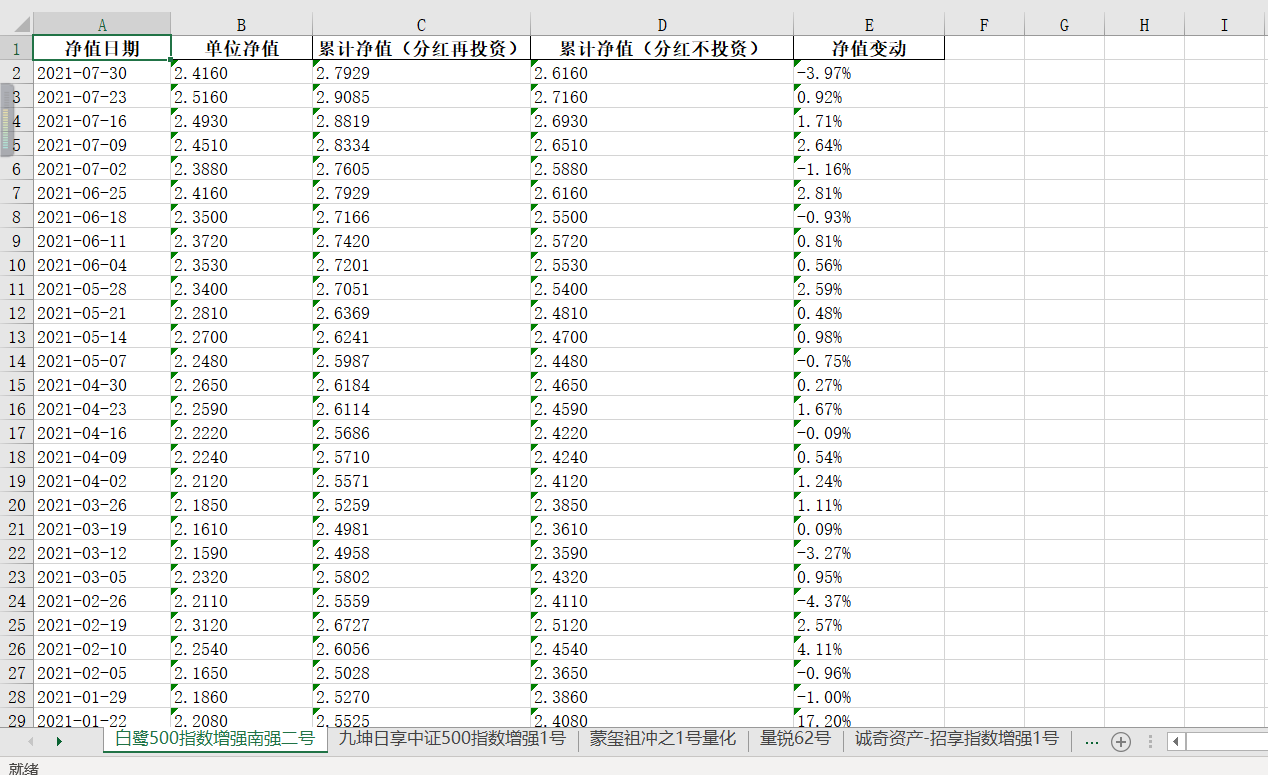
最后再将净值日期和净值变动找到(这两个没有掺杂隐藏值,很简单就能找到),然后利用pandas写入excel中。
write = pandas.ExcelWriter(r"C:\Users\86178\Desktop\私募排排网历史净值爬取.xlsx") # 新建xlsx文件。
list_info.append([list_date[index], resultList[i], resultList[i + 1], resultList[i + 2], list_net[index]]) # 分别对应净值日期,单位净值,累计净值,累计净值,净值变动pd = pandas.DataFrame(list_info, columns=['净值日期', '单位净值', '累计净值(分红再投资)', '累计净值(分红不投资)', '净值变动'])# print(pd)
pd.to_excel(write, sheet_name=list_name[ind], index=False)write.save() # 这里一定要保存
最后得到结果
四、总结
本文主要是讲的selenium的一些基本操作,例如鼠标事件、键盘事件和鼠标悬停。然后就是解密隐藏值。
我在这里遇见了很多的坑,思考了一个下午才把思路想到。我很庆幸在我最艰难的时候,没有说放弃,其实这次更大的收获是让自己对爬虫有更加深刻的见解。
这篇关于爬取私募排排网历史净值和破解加密数值的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







