本文主要是介绍【小白学Java】D23 》》》Set集合 HashSet集合 哈希值 LinkedHashSet集合 TreeSet集合可变参数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【友情链接】———–—>Java中的各种集合大汇总,学习整理
【友情链接】————–> Collection集合
【友情链接】————–> ArrayList集合及其常用功能
【友情链接】————–> ArrayList应用<两大案例的数据分组聚合>
【友情链接】———–—> Iterator迭代器
【友情链接】———–—>List集合 & LinkedList集合 & Vector集合
【友情链接】———–—>set集合 & HashSet集合 & 哈希值& LinkedHashSet集合 &TreeSet集合&可变参数
【友情链接】———–—>Map集合 & HashMap集合 & LinkedHashMap集合&HashTable集合
【友情链接】———–—>Collections类集合工具类
了解Set集合
Set接口和List接口一样,都是在java.util包下,它们都是继承自Collection接口,Set接口中的方法与Collection接口中的方法基本上是一致的。Set集合并没有对collection 接口进行功能上的扩充,它只是比 Collection 接口更加的严格了些。Set接口与List接口不同点,在于Set 接口中的元素数据是无序的,而且会以某种规则来保证存储的元素数据不会出现重复。
Set集合有多个子类,其中包括有HashSet 、和LinkedHashSet,这两个集合使用的较多。
因为Set集合是无序的,没有索引也没有带索引的方法,所以要取出Set集合中的元素数据,可以使用迭代器或者增强for循环的方式,而不能使用普通的for循环。
所以做总结道Set集合的两大特点:
- 1.Set集合中不允许存储重复的元素
- 2.Set集合没有紊引,也没有带素引的方法,不能使用昔通的for循环遍历
HashSet集合
Hashset集合也是java.util包下的,它实现了(impLements) Set接口
HashSet集合的特点:
- 1.HashSet集合中不允许存储重复的元素数据
- 2.HashSet集合没有素引,同时也没有带索引的方法,不能使用昔通的for循环进行遍历
- 3.HashSet集合是一个无序的集合,它的存储元素和取出元素的操作的顺序可能会不一致
- 4.HashSet集合的底层为哈希表结构,哈希表的特点就是查找的速度非常的快。
//创建一个set集合,使用多态
Set<String> set=new HashSet<>();
//向集合中添加元素
set.add("a");
set.add("b");
set.add("c");
set.add("d");
set.add("e");
set.add("b");
//打印set集合
System.out.println(set);
//打印结果为:[a, b, c, d, e] set集合不存储重复的元素
哈希值
概述:
哈希值为十进制整数,由系统随机给出的。哈希值指就是对象的地址值,是逻辑地址,是一个模拟出来的地址而不是数据元素实际存储时的物理地址。
那么如何获取哈希值呢?
在java.lang.0bject类有一个方法,可以获取对象的哈希值,如下图:
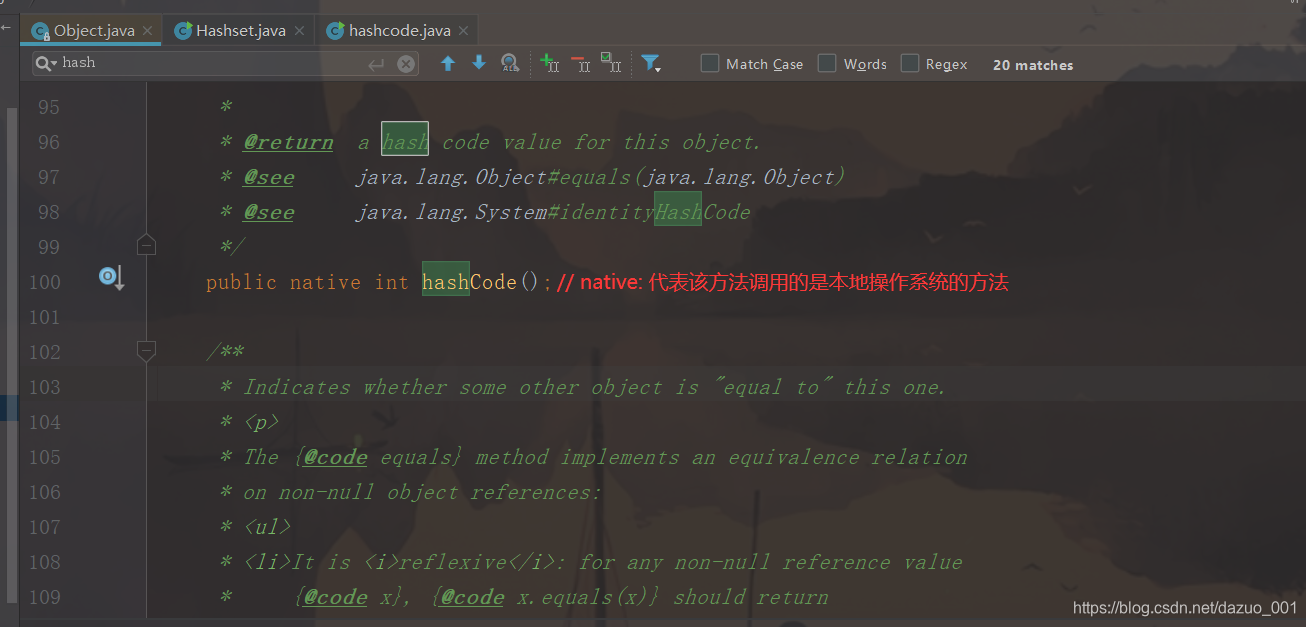
通过以下代码来了解下哈希值:
//创建一个person类
class people {private String name;private int age;private String sex;private double high;
}
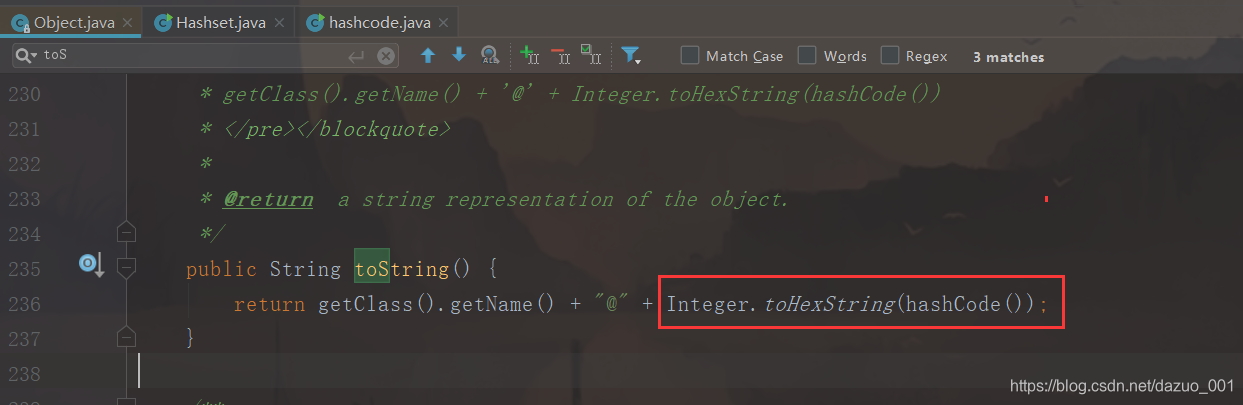
public class hashcode{public static void main(String[] args) {//new一个对象,获取其hashcode,打印people people1 = new people();int hashCode1 = people1.hashCode();System.out.println(hashCode1);//1163157884people people2 = new people();int hashCode2 = people2.hashCode();System.out.println(hashCode2);//1956725890/*java.lang.Object类的toString()方法
* public String toString() {return getClass().getName() + "@" + Integer.toHexString(hashCode());}
* *///打印两个对象的地址值System.out.println(people1);//com.sj.javabase.Set.person@4554617cSystem.out.println(people2);//com.sj.javabase.Set.person@74a14482}}

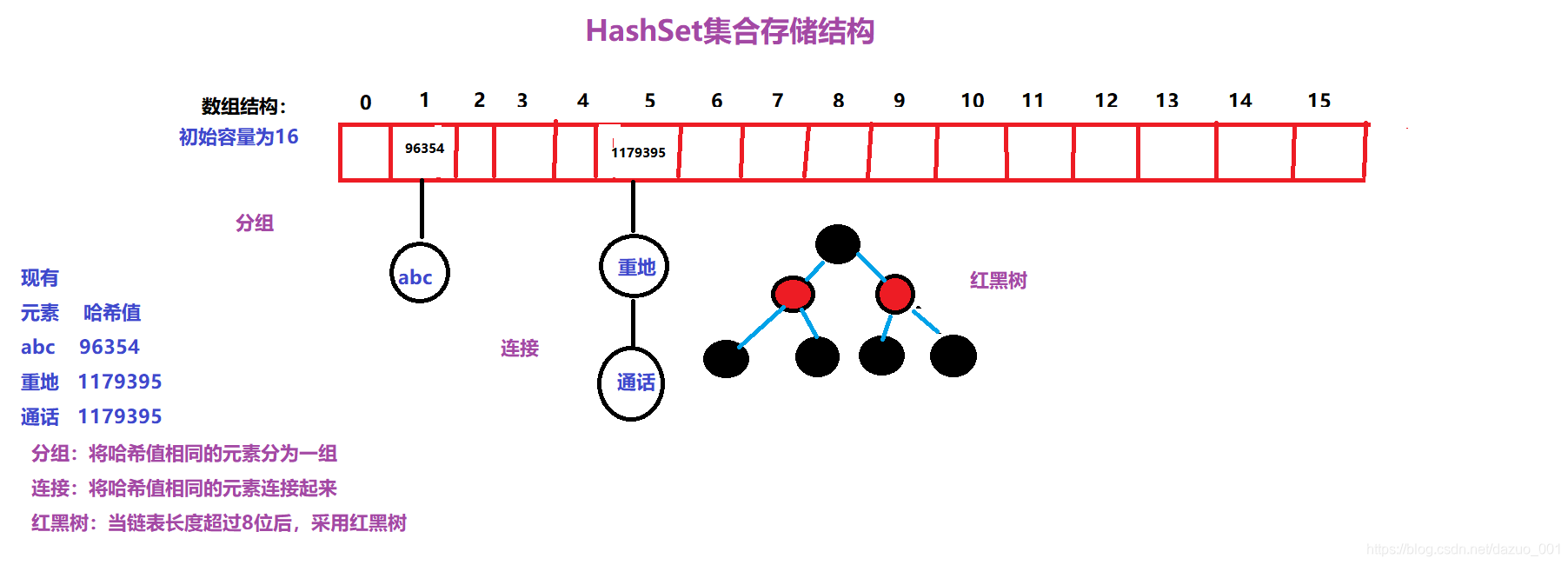
详细了解HashSet集合存储数据的结构
Hashcode(哈希值)的作用其实就是用来表示对象的地址,那么HashSet集合是如何存储元素的呢?
首先,HashSct集合存储数据的结构是哈希表(哈希表的特点就是速度快)。在JDK1.8版本之前,哈希表是由数组加链表组成的;而在,JDK1.8版本之后,哈希表是由数组加上链表或者是由数组加上红黑树组成的(红黑树的作用就是提高查询的速度,红黑树采用折半查找,查找元素非常的快)。哈希表采用数组结构的目的就是分组,把哈希值相同的元素分为一组;使用链表的目的就是连接,把哈希值相同的元素连接起来;当链表的长度超过了8位,那么就会采用红黑树,其目的就是为了提高查找速度。
详细解析Set集合为什么不允许存储重复的元素数据
看一个例子:
import java.lang.String;
import java.util.HashSet;public class demohashset {public static void main(String[] args) {//创建一个hashset集合HashSet<String> set = new HashSet<>();//new两个字符串,并打印哈希值String s1 =new String("abc") ;int hashCode1 = s1.hashCode();System.out.println("s1:hashcode\t"+hashCode1);String s2 =new String("abc") ;int hashCode2 = s2.hashCode();System.out.println("s1:hashcode\t"+hashCode2);//打印”重地“”通话“”abc“三个元素的字符串int hashCode3 = "重地".hashCode();System.out.println("重地:hashcode\t"+hashCode3);int hashCode4 = "通话".hashCode();System.out.println("通话:hashcode\t"+hashCode4);int hashCode5 = "abc".hashCode();System.out.println("abc:hashcode\t"+hashCode5);//将上面元素添加到集合中去set.add(s1);set.add(s2);set.add("重地");set.add("通话");set.add("abc");//打印集合System.out.println(set);//打印结果[重地, 通话, abc] //发现:集合存入和取出顺序不一致,不允许存储重复元素}
}运行结果截图:

现在我们来分析下Set集合不允许存储重复元素的原理:
有个小前提:
Set集合中存储的元素必须要重写hashcode()方法和equals()方法
原理
Set集合在调用add()方法向集合中添加元素时,会调用hashcode()方法来计算所要添加元素的哈希值,其次还可能调用equals()方法来判断相同的哈希值的元素数据的值是否相等
下面根据上面例子,详细的分析下Set集合存储元素的运行过程:
第一步先看s1;
Set集合中的add()方法,首先,会调用s1的hashcod()方法,来计算s1的字符串 “abc” 的哈希值,得到哈希值为96354,随后,在集合中查找有没有96354这个哈希值的元素,发现集合中没有,那么,就会把sl的字符串存储到集合中。
第二步看s2;
Set集合中的add()方法,首先,会调用s2的hashcod()方法,来计算s2的字符串 “abc” 的哈希值,得到哈希值为96354,随后,在集合中查找有没有哈希值为96354的元素,发现有,那么,就会在调用equals()方法来与哈希值相同的元素进行比较,方法返回值为true,那么就会认定这两个元素相同,最终,就不会把s2的字符串存储到集合中。
第三步看”重地“;
Set集合中的add()方法,首先,会调用”重地“的hashcod()方法,计算字符串 ”重地“ 的哈希值,得到哈希值为1179395,随后,在集合中查找有没有哈希值为1179395的元素,发现没有,就会把”重地“存储到集合中。
第四步看”通话“;
Set集合中的add()方法,首先,会调用”通话“的hashcod()方法,来计算字符串 ”通话“的哈希值,得到哈希值为1179395,随后,在集合中查找有没有哈希值为1179395的元素,发现有,那么,就会再调用equals()方法来与哈希值相同的元素进行比较,方法返回值为false,那么就会认定这两个元素不相同,最终就会把”通话存储到集合中。
注意:若是要使用HashSet集合来存储自定义的元素数据(例如,自定义的类的对象等),那么就一定要重写hashcode()方法和equals()方法
LinkedHashSet集合
LinkedHashSett集合也是java.util包下的,不过它是继承了HashSet集合。
LinkedHashSet集合特点:
LinkedHashSet集合的底层是一个哈希表加上一个链表组成,也就是说LinkedHashSet集合比HashSet集合多了一条链表用来记录元素的存储顺序的链表,从而保证了元素有序性。
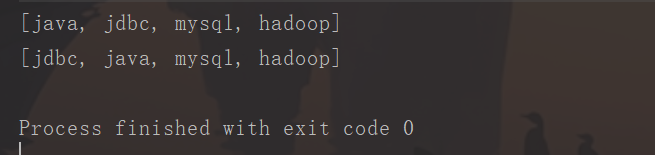
//创建一个HashSet集合
HashSet<String> set = new HashSet<>();
set.add("jdbc");
set.add("java");
set.add("mysql");
set.add("java");
set.add("hadoop");
System.out.println(set);//创建一个LinkedHashSet集合
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add("jdbc");
linkedHashSet.add("java");
linkedHashSet.add("mysql");
linkedHashSet.add("java");
linkedHashSet.add("hadoop");
System.out.println(linkedHashSet);
可变参数
可变参数是JDK1.5之后出现的新的特性,它的底层是一个数组,数组的容量会根据传递的参数的个数来创建不同长度的数组,传递的参数个数可以是0个参数(不传递参数),或者是多个参数。
使用可变参数的前提:
当方法的参数列表中,参数的数据类型确定但参数的个数不确定时,方可使用可变参数。
使用格式:修饰符 返回值类型 方法名(数据类型...变量名);//在定义方法的时候使用
注意:
- 1.一个方法的参数列表,只能有一个可变参数
- 2.如果方法的参数有多个,那么可变参数必须写在参数列表的未尾
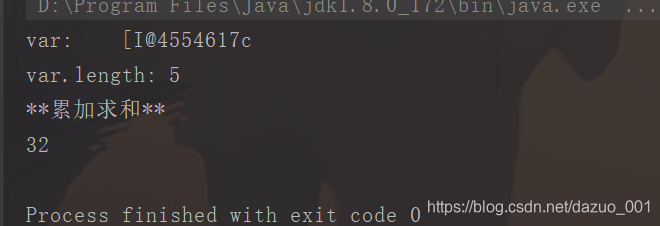
public static void main(String[] args) {//调用方法sumint a = sum(3,5,6,8,10);System.out.println(a);}
public static int sum(int...var){System.out.println("var:\t"+var);//打印的为[I@4554617c 数组的地址值,底层为一个数组System.out.println("var.length:\t"+var.length);//打印数组长度System.out.println("**累加求和**");int s = 0;for (int i: var){s+=i;}return s;
}
TreeSet集合
概述:
TreeSet集合是一个可以对元素进行排序的容器,它的底层实际上是一个TreeMap,它的内部维持了一个简化的TreeMap,通过 key来存储Set的元素数据。TreeSet集合中的存储的元素数据是有序的,有序不是指存储或取出元素有序,而是按照一定的规则进行排序,排序方式取决于构造方法,所以需要给定排序规则。
- TreeSet():根据元素的自然排序进行排序
- TreeSet(Comparator comparator):根据指定的比较器比较
TreeSet集合存储元秦特点:
- 1、不允许存储重复的元素,
- 2、存储的元素可以自动按照大小顺序排序(也就是自然排序)。
- 3、存储元素和取出元素的顺序可能不一致(因为其存入的元素会自然排序)
//创建一个TreeSet集合
TreeSet<String> treeSet = new TreeSet<>();
//添加元素
treeSet.add("d");
treeSet.add("a");
treeSet.add("b");
treeSet.add("c");
treeSet.add("c");
treeSet.add("e");
//输出集合
System.out.println(treeSet);
//打印[a, b, c, d, e],无重复,自然排序规则排序,存入取出顺序不一致
TreeSet集合通过元素自身实现比较规则
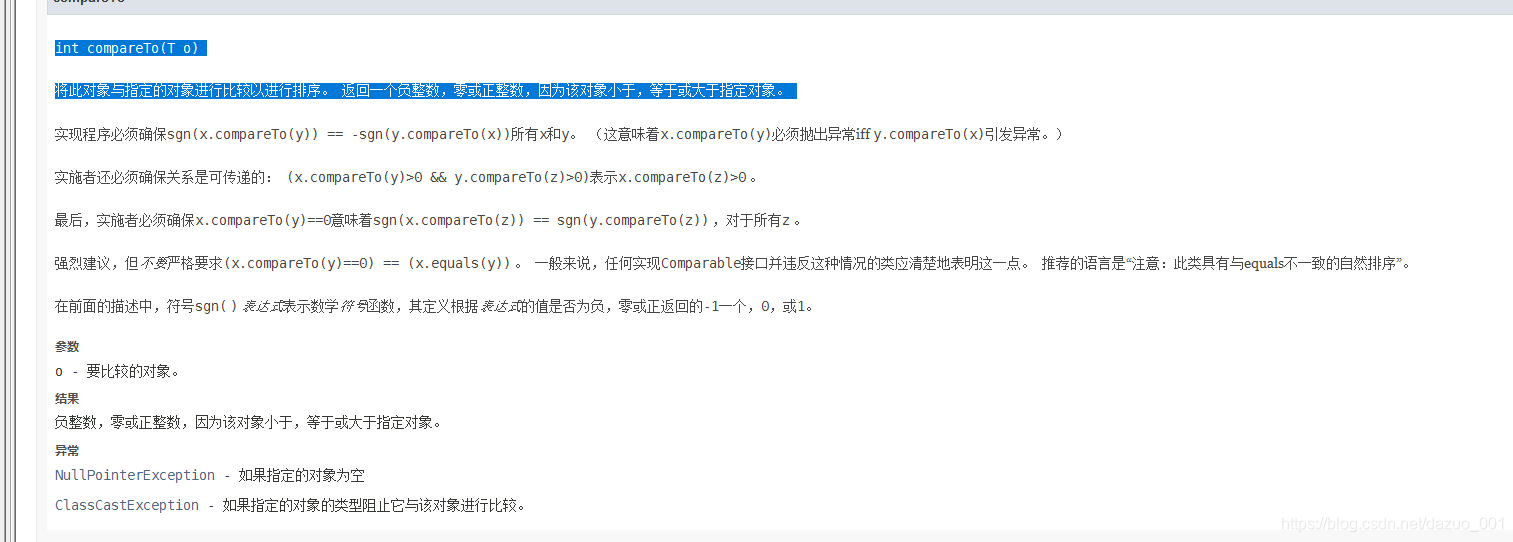
- 在通过元素自身来实现比较的规则时,需要实现Comparable接口中的compareTo()方法,在该方法中用来定义比较的规则。
- Treeset集合 通过调用该方法来实现对元素的排序处理。
了解Comparable接口:
- public interface Comparable < T > 该接口对实现它的每个类的对象强加一个整体排序。 这个排序被称为类的自然排序 ,类的compareTo方法被称为其自然比较方法 。
看个例子,来实现compareTo()方法定义比较规则:
//创建一个学生类 属性:name \ age 实现Comparable接口
//重写toString()方法 和 compareTo()方法定义比较规则
public class Student implements Comparable<Student>{private String name;private int age;public Student() {}public Student(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +'}';}public void setAge(int age) {this.age = age;}//重写Comparable接口中的 int compareTo()方法//int compareTo(T o):将此对象与指定的对象进行比较以进行排序。// 返回一个负整数,零或正整数,因为该对象小于,等于或大于指定对象。// 自定义比较规则: 正数表示大, 负数表示小, 0表示相等@Overridepublic int compareTo(Student o) {//根据年龄来判断排序if(this.age > o.getAge()){//调用该方法的对象的age大于对象o的age,//可以通过修改判断条件,来决定排序是由大到小还是由小到大return 1;//返回正整数}//当年龄相同时,根据姓名来排序if (this.age == o.getAge()){//Sting类中已经实现了Comparable接口中的compareTo()方法的重写,可以直接调用return this.name.compareTo(o.getName());}return -1;//调用该方法的对象的age小于对象o的age}
}
测试定义的规则:
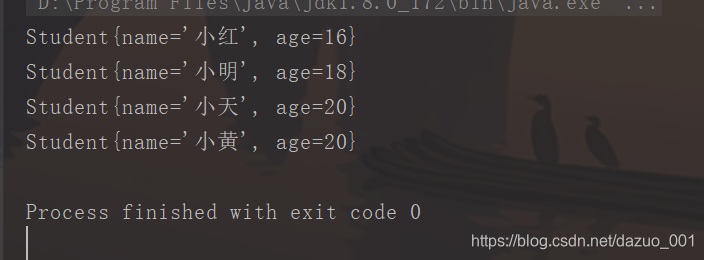
import java.util.TreeSet;public class demotest {public static void main(String[] args) {//创建一个TreeSet集合,存储元素为Student类型TreeSet<Student> treeSet = new TreeSet<>();//new student对象元素Student student1 = new Student("小明",18);Student student2 = new Student("小红",16);Student student3 = new Student("小天",20);Student student4 = new Student("小黄",20);//添加对象元素到treesettreeSet.add(student1);treeSet.add(student2);treeSet.add(student3);treeSet.add(student4);//遍历treesetfor (Student student :treeSet) {System.out.println(student);}}
}
遍历结果截图:
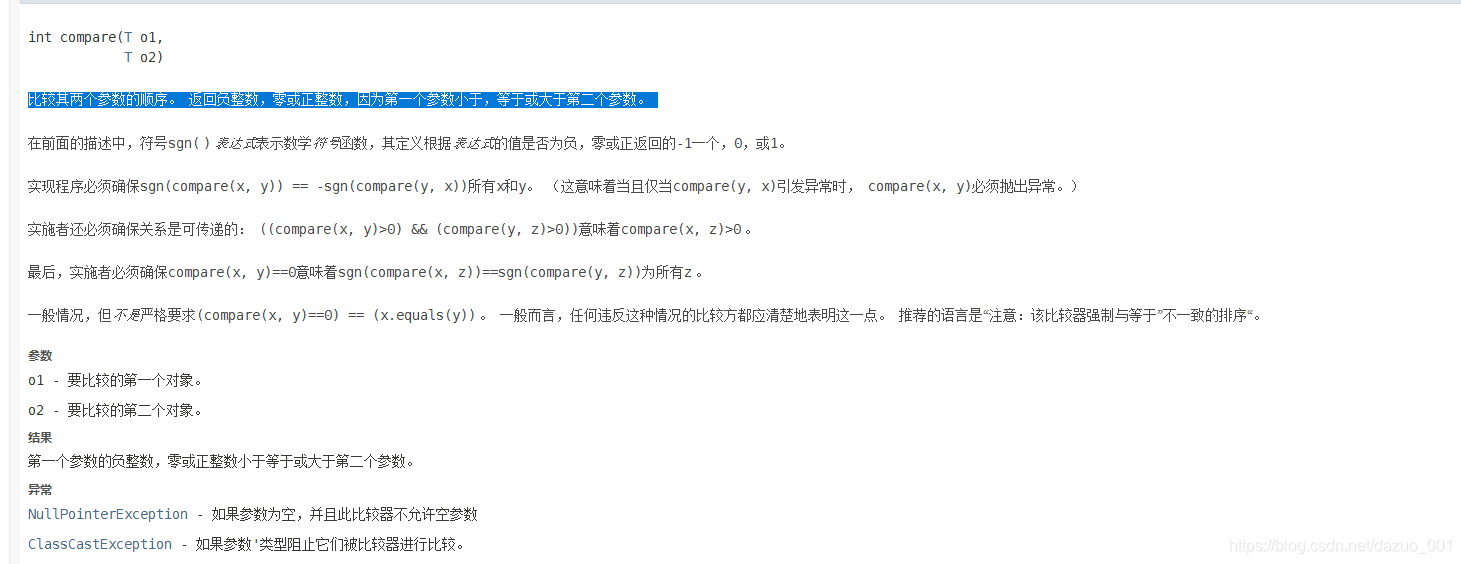
TreeSet集合通过比较器实现比较规则
实现Interface Comparator < T >接口(T - 可比较此比较器的对象类型)
重写compare()方法;
通过比较器定义比较规则时,需要单独创建一个比较器,而这个比较器需要实现Comparator接口中的compare()方法来定义比较规则。 并且在实例化TreeSet 时,将比较器对象交给TreeSet来完成元素的排序。那么这时候,元素自己就不需要实现比较规则了。
看一个例子:
//创建一个Teacher类,属性:name,age,high;
//重写toString方法public class Teacher {private String name;private int age;private int high;@Overridepublic String toString() {return "Teacher{" +"name='" + name + '\'' +", age=" + age +", high=" + high +'}';}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public int getHigh() {return high;}public void setHigh(int high) {this.high = high;}public Teacher() {}public Teacher(String name, int age, int high) {this.name = name;this.age = age;this.high = high;}
}//创建TeacherComparator类实现Comparator接口
//重写compare()方法,定义比较规则import java.util.Comparator;public class TeacherComparator implements Comparator<Teacher> {@Overridepublic int compare(Teacher o1, Teacher o2) {//比较年龄,由小到大排序if (o1.getAge() > o2.getAge()){return 1;}//年龄相等,比较姓名if (o1.getAge() == o2.getAge()){//年龄相等,姓名相同,比较身高if ( o1.getName()==o2.getName()){//Integer.toString(o1.getHigh()):类型转换,将int high转换为Stringreturn (Integer.toString(o1.getHigh())).compareTo((Integer.toString(o2.getHigh())));}return o1.getName().compareTo(o2.getName());}return -1;}
}******* 测试*********
//创建测试类,测试TreeSet集合通过比较器实现比较规则
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
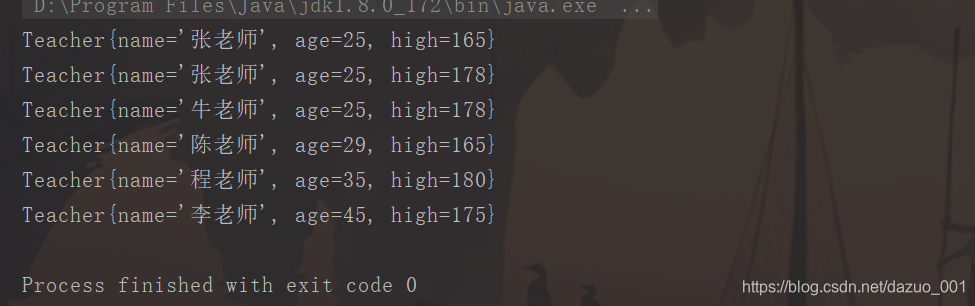
public class demoComparatorTest {public static void main(String[] args) {//创建一个TreeSet集合,通过new TeacherComparator()构造方法将比较规则传递给TreeSetSet<Teacher> treeSet1 = new TreeSet<>(new TeacherComparator());//或者通过构造匿名类来实现eacherComparator()构造方法将比较规则传递给TreeSetSet<Teacher> treeSet2 = new TreeSet<>(new Comparator<Teacher>() {@Overridepublic int compare(Teacher o1, Teacher o2) {//比较年龄,由小到大排序if (o1.getAge() > o2.getAge()){return 1;}//年龄相等,比较姓名if (o1.getAge() == o2.getAge()){//年龄相等,姓名相同,比较身高if ( o1.getName()==o2.getName()){//Integer.toString(o1.getHigh()):类型转换,将int high转换为Stringreturn (Integer.toString(o1.getHigh())).compareTo((Integer.toString(o2.getHigh())));}return o1.getName().compareTo(o2.getName());}return -1;}});//创建对象Teacher teacher1 = new Teacher("张老师",25,178);Teacher teacher2 = new Teacher("李老师",45,175);Teacher teacher3 = new Teacher("程老师",35,180);Teacher teacher4 = new Teacher("陈老师",29,165);Teacher teacher5 = new Teacher("牛老师",25,178);Teacher teacher6 = new Teacher("张老师",25,165);//添加元素treeSet2.add(teacher1);treeSet2.add(teacher2);treeSet2.add(teacher3);treeSet2.add(teacher4);treeSet2.add(teacher5);treeSet2.add(teacher6);//遍历TreeSet集合for (Teacher teacher : treeSet2) {System.out.println(teacher);}}
}测试结果截图;
制作不易,各位友友们,大佬们给点鼓励!
点赞👍 收藏+关注 一键三联走起!
这篇关于【小白学Java】D23 》》》Set集合 HashSet集合 哈希值 LinkedHashSet集合 TreeSet集合可变参数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






