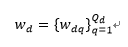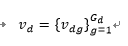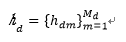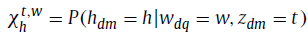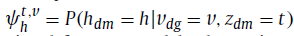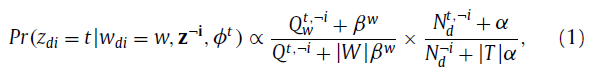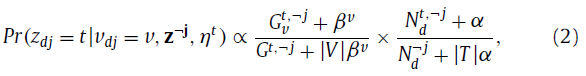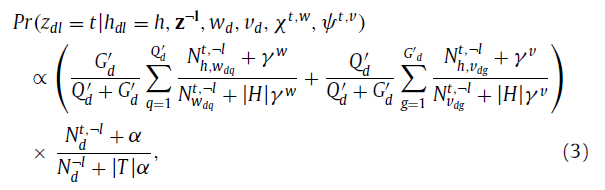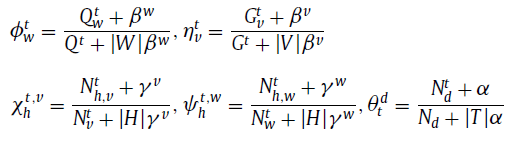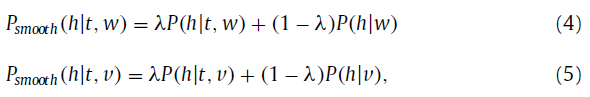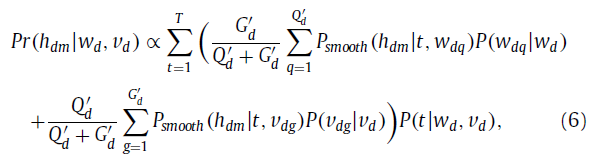本文主要是介绍论文笔记:Hashtag recommendation for multimodal microblog posts,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
感想
这篇论文是18年的最新发表的论文,我看它的一个原因,是因为它很新,同时利用了新浪微博的微文,并且利用了微博和图片的信息来进行推荐,不过有点遗憾的是,它们采取的方法是传统的方法,比较的算法也是传统的NB,SVM等算法,没有用到深度学习,不知道作者有没有意向把数据集贡献一下,好让大家也做相关的研究,不过工作量还是有的,还是值得肯定的。
1 介绍
随着社交媒体的迅速增长,大约72%的成人互联网用户是至少一个社交网络的成员。在过去的几年里,在众多社交媒体中微博已成为最流行的服务之一。因此,微博已经被广泛用于舆论分析,预测,声望管理和许多其他应用的数据源。除了内容中的有限字符,微博也包含一种形式的元数据,hashtag,它是一串用#标记的字符。Hashtags用于标记一个微博的主题或者关键字。他们可以出现在微博的任意位置,起始,中间或者结尾。Hashtags在许多应用中被证明是有用的,包括微博检索,查询展开,情感分析。可是只有很少的微博会被用户打上hashtags。因此,自动推荐hashtags已成为一个重要的研究话题,并且在最近几年也受到了广泛的关注。
尽管在这个任务上已经有了一些研究,但是大多数的研究仅仅关注的是文本信息的使用,用的是判别模型或者生成模型。可是,从新浪微博爬取的2.822亿微博数据集来看,我们发现超过34.4%的posts不仅包含文本也包含图片。大量有图片的微博不包含与图片相关的文本。因此,仅仅利用文本信息来正确推荐hashtags不那么容易。

如上图1,显示的是一个用hashtag#superBowl标记的微博,我们可以看到,仅仅利用文本信息,我们很难推荐正确的hashtags.
针对图片的tag推荐任务和这个任务相关,并且已经从不同的方面研究了很多。大多数工作都是关注用户通过社交媒体标注的tags,例如Flickr, Zooomr等等。这些服务中tag标注跟标签一样,添加到图片使得图片很容易能找到。先前的工作主要集中在推荐标签,使得标签能够很好的描述图片,而hashtags通常涉及到更抽象的概念。通常Flickr上基于内容的tags(例如sky, water, car等等)很少会出现在微博的hashtag中。这表明前面使用视觉信息的工作不能直接用于这个任务。
为了克服这些问题,在这个工作中,我们提出了一个生成模型,把文本和视觉信息结合在一起,为了限制微博的长度,hashtags甚至可能没有出现在微博的文本内容里,受解决词汇差距问题(vocabularygap problem)的方法的启发,这些方法用于关键词提取(keyphrase extraction)和hashtag建议(hashtag suggestion)。我们假设微博中的hashtags,文本内容,和视觉单词是用不同语言对同事物的并行描述,因此,我们把hashtagsuggestion任务作为一个转移问题。我们用bag-of-words(BoW)框架来表示图片,基于视觉单词集合,我们提取并量化了布局不变图像描述(Localinvariant image descriptors,例如SIFT)。为了对文档主题建模,在这篇文章中,我们也提出使用话题转移模型(topical translation model)来优化转移过程,特定话题的词触发是图片视觉单词和hashtags的桥梁。为了证明我们的模型的有效性,我们在从微博服务上筹集的大数据集做实验。实验结果证明,我们的模型可以取的更好的性能,比现在只使用文本或视觉信息的方法好。
2 贡献
这个工作的主要贡献总结如下:
1. 我们提出并研究了多模态微博posts的推荐hashtags的任务。据我们所知,在这个任务上,这是第一个工作。现有在hashtag推荐任务上的工作通常只关注文本信息。
2. 我们提出了一个新颖的话题转移模型,模型结合了文本和视觉信息。我们认为这个模型可以很容易用于其它的多模态任务。
3. 我们构造了一个大的多模态微博集合,微博来自真实的微博服务,其中所有的微博都包含文本内容,图片和用户标注的hashtags. 使用这个多模态社交媒介数据,可以使得其它研究者也可以在相同任务和其它话题上受益。
3 提出的方法
3.1 生成过程
给定一个语料库D,第d个微博由一串文本单词(w_d),视觉特征(v_d)和hashtags h_d.
w_d表示第d个微博post的文本单词的集合,Q_d表示文本单词的数量。
视觉特征的集合用v_d表示
其中,G_d表示第d个微博post的视觉特征的数量。
Hashtags的集合用h_d表示
其中,M_d表示第d个微博的hashtag的数量。
所有的文本单词组成了一个词汇表,词汇表的大小为|W|,表示为
W={w_1,w_2…,w_(|W|)},
第d个微博的第q个文本单词和一个话题z_dq关联,视觉特征
V={v_1,v_2,…, v_(|V|)},
其中|V|为视觉特征的大小,第d个微博的第g个特征与一个话题z_dg关联。
每个hashtag来自词汇表,词汇表表示为H={h_1,h_2,…,h_(|H|)}
第d个微博的第m个hashtag和一个话题z_dm相关联。
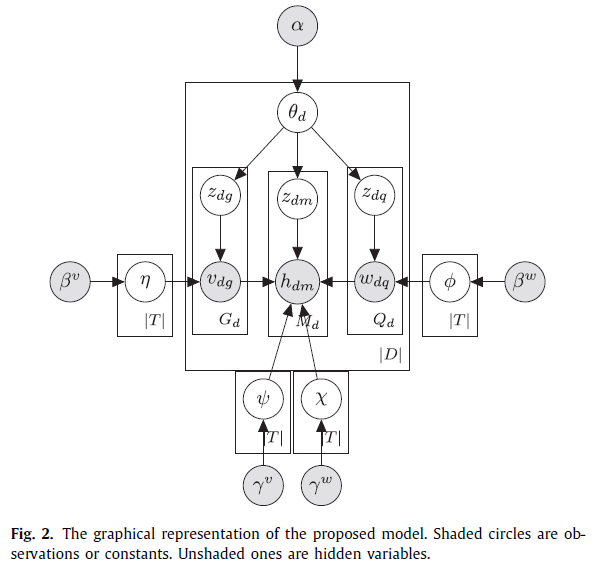
上图表示生成过程的图形化表示,生成故事(generative story)如下:
转移概率X_h^(t,w)和ψ_h^(t,v)是关键参数。X_h^(t,w)是在话题t下从文本单词w转移到hashtag h的转移概率,例如:
X_h^(t,w)是在话题t下,从视觉特征t到hashtag h的转移概率,例如:
给定微博集合中的观察文本单词,视觉特征和hashtags,我们的任务是计算潜在话题指派z的后验概率,每个微博的话题混合θ_d,每个话题t中的单词文本单词Ф^t的分布,每个话题t中视觉特征η^t的分布,每个话题和文本单词的hashtag X^(t,w)的分布,以及每个话题和视觉特征的hashtag ψ^(t,v)的分布。
3.2 模型推理(model inference)
我们使用collapsed Gibbs sampling来得到隐式变量指派的样本,从这些样本中估计模型的参数。
在文本单词的方面,Z_di=t的概率的计算公式如下:
其中,Q_w^(t,¬i)是在话题t下的文本单词w的数量,Q^(t,-i)是在文本单词中话题t共现的数量(the number of t occurrences in the text words),N_d^(t,¬i)是在第d个微博中所有话题共现的数量,所有数量计算的时候,当前的单词W_di排除在外。
在视觉特征方面,z_dj=t的概率计算公式如下:
其中,G_v^(t,¬j)是话题t下的数据特征v的数量,G^(t,-j)是视觉特征中t共现的数量。所有的数量计算时,当前的单词v_dj排除在外。
在hashtag方面,问题就更复杂了。z_dj=t的概率用如下的公式计算:
其中,G_d^'和Q_d^'分别代表话题t下视觉特征和文本单词的索引集合,N_(h,w_dq)^(t,¬l)是在话题t下hashtag h和语料库中文本单词w_dq共现的数量,N_(h,v_dg)^(t,¬l)是语料库中的话题t下hashtag h和视觉特征v_dg的数量。所有的数量的计算都把当前的单词h_dl排除在外。
经过足够的采样迭代之后,形成了马尔科夫链,∅^t,η^t,X^(t,v),ψ^(t,w)和θ用下面的公式进行估计:
从这个模型,我们可以观察到X和ψ对齐概率的潜在大小分别为|H|x|V|x|T|和|H|x|W|x|T|。视觉单词和文本单词的的词汇量大小为几千个。数据稀疏性可能比topic-free单词对
齐情况造成的问题严重得多。因此,为了克服数据稀疏性问题,我们利用线性差值法和topic-free单词对齐概率。下面的方程用于平滑转移概率:
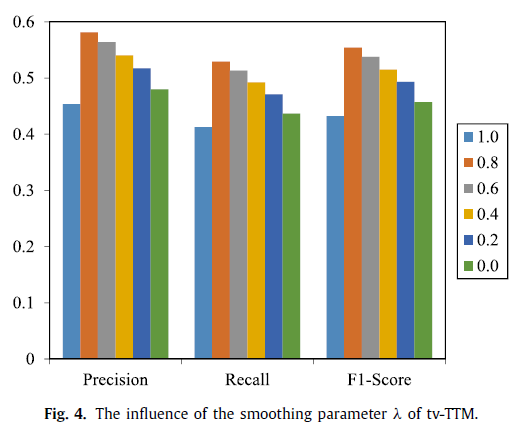
其中P(h|w)是一个在文本单词w和hashtag h中的topic-free单词对齐概率,P(h|v)是视觉特征v和hashtag h的topict-free单词对齐概率,这里,我们利用IBM model-1,它被广泛用于单词对齐模型,来获得P(h|w),P(h,t)。P(h|t,w)等同于ψ_h^(t,w),P(h|t,v)等同于X_h^(t,v)。参数λ是两个概率的折衷,范围为[0.0,1.0].当λ设置为0.0的时候,P_smooth (h|t,w)和P_smooth (h|t,v)将会减少至tpic-free单词对齐概率。当λ设置为1.0的时候,P_smooth (h|t,w)和P_smooth (h|t,v)将没有平滑。
3.3 Hashtag extraction
假设我们有一个数据集,但是没有用hashtag进行标记,我们使用collapsed Gibbs sampling来估计每个微博中所有单词的话题。
在估计每个单词的隐式话题以后,就变得稳定了,我们可以对第d个微博在未标记的数据上进行排序,计算分数如下:
其中,P(W_dq |W_d)为微博中文本单词W_dq的权重,P(V_dg |V_d)为视觉特征的权重V_dg,这可以用单词的IDF分数来估计。P(t|W_d,V_d)等同于θ_t^d.根据排序分数,我们可以对用户的微博推荐top-ranked hashtags。
4 实验
4.1 数据收集
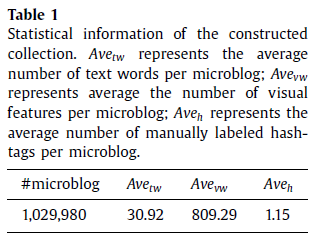
我们开始用Sina Weibo的API从随机选择的用户中来筹集公共微博。这个集合包含2.822亿条微博,由110万用户产生。从这些微博中,我们抽取了那些既包含图片又包含hashtags的微博。在这一步中,我们抽取了269万微博,但有些hashtag很少出现,我们过滤掉了语料库中出现频率小于100的hashtags。最后,我们构建的集合包含103万微博,微博包含图片和高频的hashtags。详细统计如表1。
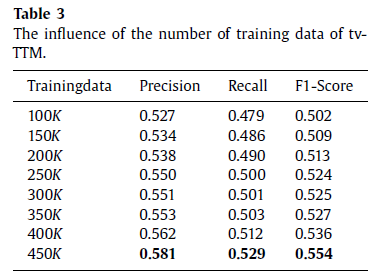
从这些数据集中,我们随机选择了50 000微博作为测试集合。语料库中特定数量的hashtags为3204.那些由用户标注的hashtags被当做黄金标准。为了构造训练集,我们随机从其中选择450 000条微博。
对于文本单词,我们过滤掉了消停词和低频词。构造的单词词汇表包含470 000个存在的单词。对于视觉特征,我们采用了标准的基于SIFT描述器的bag-of-words表示,它使用包含10 000个密语的电报密码本(codebook of 10,0 0 0 codewords),这些密语在一个SIFT描述器的样本集合中利用k-means聚类产生的。所有的大图片都按比例减少到400个像素,然后进行SIFT抽取,原来的纵横比保留了。
4.2 实验设置
我们使用Precision(P),recall(R)和F1-score(F1)来评估其性能。Precision是基于“hashtags truly assigned” 在“hashtags assigned by the system”的比例来计算的。Recall是基于“hashtags truly assigned”在“hashtags manually assigned”的比例计算的,F1-score是precision和recall的调和平均值(harmonic mean)。我们利用gibbs sampling把模型运行了500次,经过尝试了不同数量的主题以后,我们经验的把话题设置为10.其它的超参数设置如下:α=0.5,β^w=0.1, β^v=0.1, ℽ^w=0.1, ℽ^w=0.1,平滑参数λ设置为0.8.为了在没有话题信息的情况下估计转移概率,我们使用GIZA++ 1.07。
对于baselines,我们把我们的模型和下面的baseline模型进行对比:
l Naive Bayes(NB):hashtag推荐任务也可以定义为一个分类任务。因此,在给定微博的文本和视觉信息的情况下,我们应用NB来对每个hashtag的后验概率进行建模。
l Support Vector Machine (SVM) :我们把tagrecommendation问题转换为一个分类问题,使用SVM来对其进行建模。
l Neighbor Voting (NV):我们基于从视觉邻居进行投票来推荐标签。
l The Topical Word Trigger Model (TWTM):TWTM用于关键句提取,它只使用文本信息,我们实现这个模型并且使用它来完成任务。
4.3 实验结果
我们从下面的视角来评估提出的模型:
1) 使用真实世界数据集来跟最好的方法比较
2) 识别参数的影响
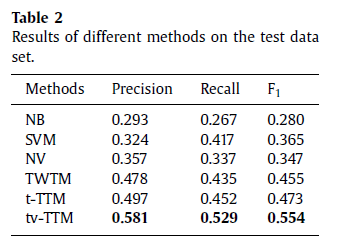
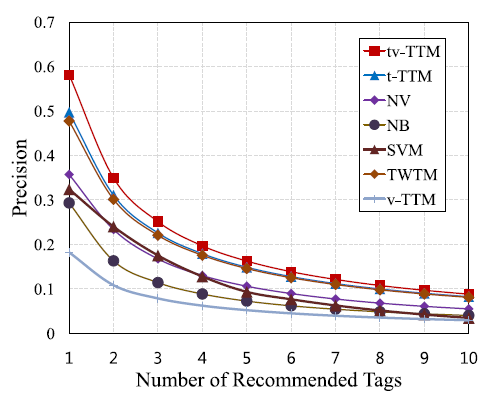
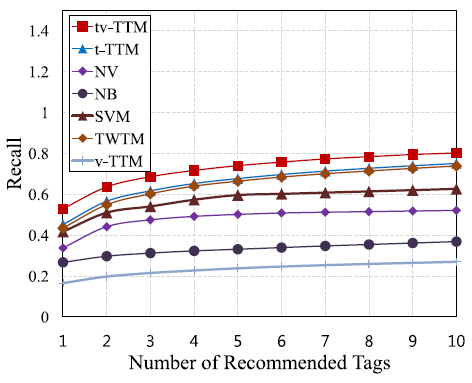
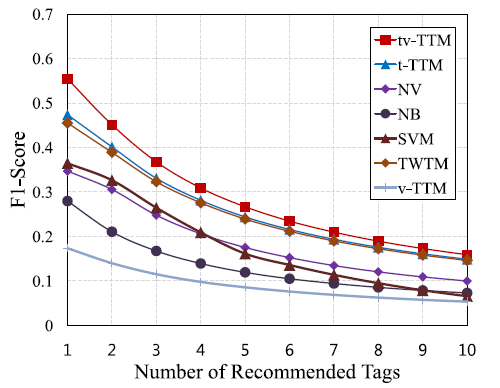
图3显示的是NB,SVM, NV, T WT W, t-TTM, 和 tv-TTM在评估集合上的 Precision, Recall和 F1-Score的曲线,曲线上的每个点表示提取的不同数量的hashtags,范围为1到10.曲线的最高点表示最佳的性能。从结果中,我们可以了解tv-TTM的性能是所有方法中最好的。这也意味着我们提出的方法比现在最好的方法要好。
表3显示的是训练数据元素数量的影响,根据结果,我们发现tv-TTM比其他只有100 000则训练数据方法要好,结果也证明tv-TTM的性能随着训练数据集的增加而增加。
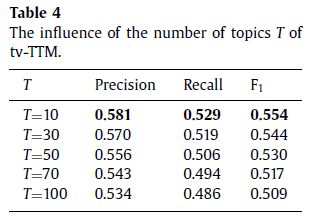
基于对于所提出的方法的描述,tv-TTM有一些超参数,为了评估他们的影响,我们评估了两个关键的参数:topics的数量和平滑因子λ。表4显示的是topics的数量的影响。
在这幅图中,我们观察到当T设置为10的时候,提出的方法达到了最佳的性能。我们相信数据稀疏性可能是主要原因之一。随着话题数量的增加,当估计topic-specific转移概率的时候,数据稀疏性问题就会越严重。
图4显示的是转移概率平滑参数λ的影响,当λ设置为0.0的时候,意味着话题信息被忽略了,从λ为0和其它值的比较结果来看,我们观察到话题信息能够提升性能;当λ设置为1.0的时候,代表这个方法没有平滑。结果表明有必要通过平滑来解决稀疏性问题。
文章提出的算法如下:

参考文献
[1]. YeyunGong, Qi Zhang, Xuanjing Huang: Hashtag recommendation for multimodal microblogposts. Neurocomputing 272: 170-177 (2018)
这篇关于论文笔记:Hashtag recommendation for multimodal microblog posts的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!