本文主要是介绍论文阅读——Stock Movement Prediction from Tweets and Historical Prices,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文阅读——Stock Movement Prediction from Tweets and Historical Prices
- 出处
- 摘要
- 动机
- 介绍
- 模型
出处
摘要
股票走势预测是一个具有挑战性的问题:市场是高度随机的,并且要根据混乱的数据做出与时间相关的预测。这篇文章处理这三种复杂性,并提出一个新颖的深度生成模型,共同利用文本和价格信号来完成这项任务。与判别式或主题建模不同,这篇文章引入了递归的、连续的潜在变量以更好地处理随机性,并使用神经变分推理来解决难以处理的后验推理,还提供了一个带有时间辅助的混合目标以灵活地捕捉预测依赖关系
动机
- 生成主题模型不是仅使用确定性特征,而是扩展为共同学习任务的主题和情感。与判别模型相比,生成模型在描述从市场信息到股票信号的生成过程和引入随机性方面具有天然优势。然而,大多数模型用词袋来表示混乱的社交文本,并使用简单的离散潜在变量。
- 现有的NLP研究没有解决移动预测之间时间依赖性的重要性。举个例子:当一家公司在交易日d1遭遇重大丑闻时,一般情况下,其股价将在接下来的交易日内呈下降趋势,直至 d2 日,即 [d1,d2].2 如果股票预测者能够识别这一点下降模式,它可能有利于 [d1,d2] 期间的所有运动预测。否则,可能会损害此区间的准确性。This
predictive dependency is a result of the fact that public information, e.g. a company scandal, needs time to be absorbed into movements over time , and thus is largely
shared across temporally-close predictions。 - 旨在解决市场高随机性、混乱市场信息和时间依赖预测方面的空白研究。
介绍
为了更好地结合随机因素,本文从潜在驱动因子中生成股票运动,该因子以递归的、连续的潜在变量为模型。受变分自动编码器(VAE)的启发,本文提出了一种具有变分架构的新型解码器,并未端到端训练推到出循环变分下限。StockNet是第一个用于股票走势预测的深度生成模型。
为了充分利用市场信息,StockNet直接从数据中学习,没有预先提取结构化事件。本文通过参考基本信息来建立市场源,eg:tweets,techincal features。为了准确描绘预测依赖性,假设股票的运动预测可以受益于学习预测其在滞后窗口中的历史运动。本文将交易日对齐作为框架基础,并进一步提供一个新颖的多任务学习目标。
模型
我们先找到样本中提到的所有T个合格的交易日,换句话说,存在于时间区间[d-🔺d+1,d]。为清楚起见,用t∈[1,T]对上述提到的交易日进行索引,并且它们中的每一个都映射到一个实际(绝对)交易日dt。然后实施交易日对齐:通过将推文语料和历史价格与这些T个交易日对齐来重新组织输入。具体来说,在第t个交易日,我们识别来自[d(t-1),dt)的语料库和d(t-1)上的历史价格pt的市场信号,以预测yt在dt上的运动。样本中的每个单元都是一个交易日,我们可以预测一系列的移动y*=[y1,…,y(T-1),yT]。主目标是yT,其他是辅助目标。除了主要目标之外,还要使用这些辅助目标来提高预测准确性。
按照如下过程来建模生成过程。将观测到的市场信息编码位一个随机变量X=[x1,…xT],从中我们生成潜在驱动因子Z=[z1,…zT]用于我们的预测任务。对于多任务学习的目的,旨在建模条件概率分布: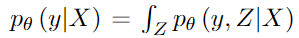
而不是:
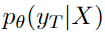

这篇关于论文阅读——Stock Movement Prediction from Tweets and Historical Prices的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)