本文主要是介绍Deep SVDD,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SVDD的基本原理是建立一个超球体去尽可能地包含所有数据,当数据在超球体外就将其作为异常点。
如图1所示:
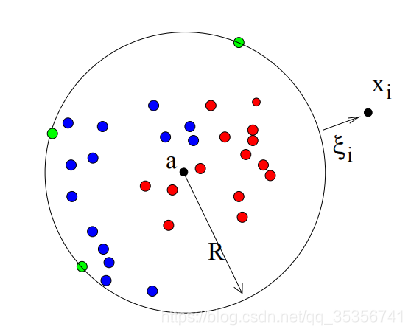
图1 SVDD原理示意图
在SVDD的原理(具体可参考上一篇博客)中,其优化过程如下:
(1)
通常,该优化问题求解与SVM的求解过程类似。在这里,我们可以通过神经网络去模拟这个过程,
具体地,可以建立如下性能函数(loss function/performance index):
 (2)
(2)
该性能函数被称为:Soft-boundary Deep SVDD。在该式中,第一项与(1)式相同,都是约束的超球体
的半径,即希望所建立的超球体体积尽可能地小。在第二项中,其最小化超球体外的所有异常点到超球体
中心c的距离和,这部分与式(1)中的第二项约束其经验风险不为0的操作精神是一致的。最后一项约束
是对神经网络本身的权重W的大小进行约束,类似于L2约束,可将该约束看作结构风险。
在(2)的基础上,还可以构建出另外一种loss函数,如下所示:
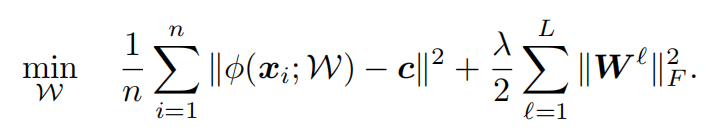 (3)
(3)
该性能函数称为:One Class Deep SVDD。与(2)相比,其差异仅在于第二项中,统计了所有样本点
到超球体中心的距离。
无论是(2)还是(3)都需要单独求解超球体中心,半径。对于超球体中心,一种操作方案是在神经网络
训练时,输入部分样本,这部分样本通过神经网络可转换至某一特征空间中,在该特征空间中计算这些样本
的一个平均值作为超球体中心,也就是说,指定一个超球体中心,通过神经网络将数据尽可能地映射至该
中心周围。对于超球体半径,在指定超球体中心的情况下,对于所有样本,可以计算出多个超球体半径,
合适的半径选择可通过线搜索的方法进行确定。同时,优化神经网络过程中,也可参考交替优化的策略,即
可以先固定R,优化几个EOPOCH的权重,之后固定权重,选择合适的R。具体可参考文献[1]的做法。
参考文献:
[1] Lukas Ruff, Deep One-Class Classification, 2018.
这篇关于Deep SVDD的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








