本文主要是介绍Elasticsearch-Suggest API,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
什么是搜索建议
Elasticsearch Suggester API
Term Suggester
Phrase Suggester
The Complete Suggester
使用Completion Suggester的一些步骤
Context Suggester
实现Context Suggester
精准度和召回率
什么是搜索建议
-
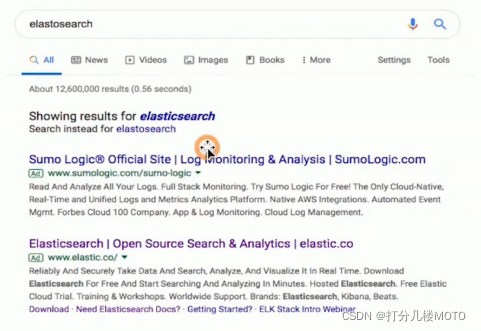
现代的搜索引擎,一般会提供一个Suggest as you type 功能
-
帮助用户在输入搜索的工程中,进行自动补全或者纠错.通过协助用户输入更加精确的关键词,提高后续搜索阶段文档匹配的长度
-
在google上搜索,一开始会自动补全.当输入到一定长度,如果因为单词拼写错误无法补全,就会开始提示相似的词或者句子
Elasticsearch Suggester API
-
搜索引擎中类似的功能,在ES中是通过Suggester API实现的
-
原理:将输入的文本分解为Token,然后在索引的字典里查找相似的Term并返回
-
根据不同的场景,ES设计了四种类别的Suggesters
-
Term & Phrase Suggester
-
Complete & Context Suggester
-
Term Suggester
-
Suggester就是一种特殊类型的搜索,"text"里是调用时候提供的文本,通常来自于用户界面上用户输入的内容
-
用户输入的"lucen"是一个错误的拼写
-
会到指定的字段"body"上搜索,当无法搜索到结果时(missing),返回建议的词
POST /atricles/_bulk
{"index":{}}
{"body":"lucene is very cool"}
{"index":{}}
{"body":"ES builds on top of lucene"}
{"index":{}}
{"body":"ES rocks"}
{"index":{}}
{"body":"es is the company behind ELK stack"}
{"index":{}}
{"body":"ELK stack rocks"}
{"index":{}}
{"body":"es is rock solid"}POST /atricles/_search
{
"size":1,
"query": {
"match": {
"body": "lucen rock"
}
},
"suggest": {
"term-suggestion": {
"text": "lucen rock",
"term": {
"suggest_mode": "missing",
"field":"body"
}
}
}
}
-
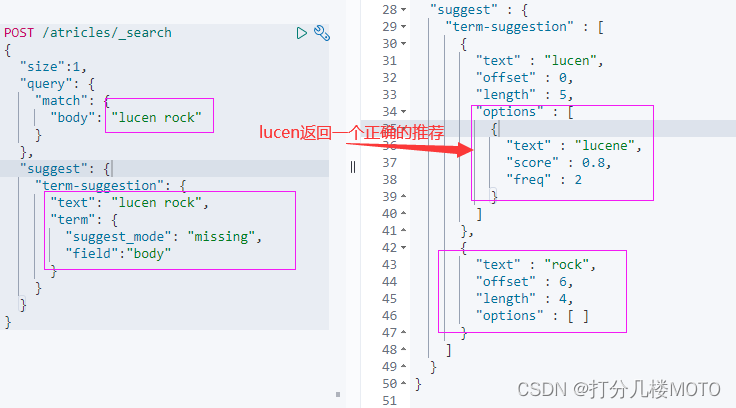
搜索"lucen rock"
-
每个建议都包含了一个算分,相似性是通过Levenshtein Edit Distance的算法来实现的.核心思想就是一个词改动多少字符就可以和另外一个词一致.提供了很多可选参数来控制相似性的模糊度.例如"max_edits"
-
-
几种Suggestion Mode
-
Missing -- 如果索引中已经存在,就不提供建议(上面的rock就已经存在了,不会提供建议)
-
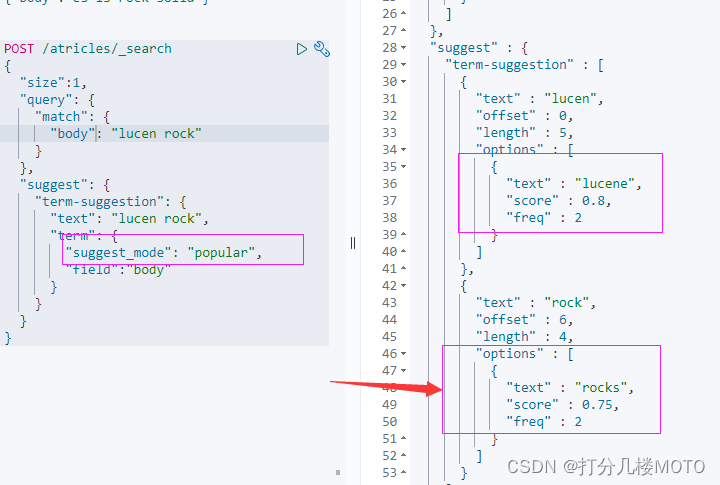
Polular -- 推荐出现频率更高的词
-
Always -- 无论是否存在,都提供建议
-
POST /atricles/_search
{
"size":1,
"query": {
"match": {
"body": "lucen rock"
}
},
"suggest": {
"term-suggestion": {
"text": "lucen rock",
"term": {
"suggest_mode": "popular",
"field":"body"
}
}
}
}
POST /atricles/_search
{
"size":1,
"query": {
"match": {
"body": "lucen rock"
}
},
"suggest": {
"term-suggestion": {
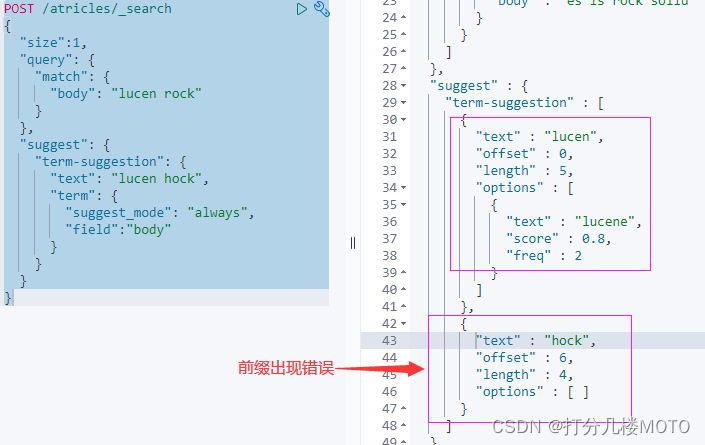
"text": "lucen hock",
"term": {
"suggest_mode": "always",
"field":"body"
}
}
}
}
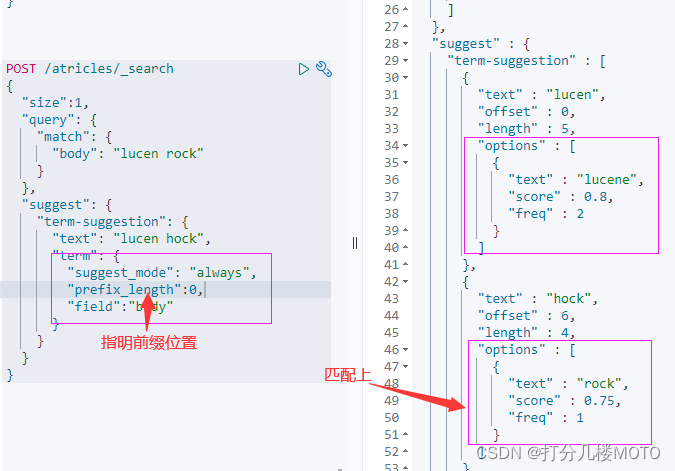
POST /atricles/_search
{
"size":1,
"query": {
"match": {
"body": "lucen rock"
}
},
"suggest": {
"term-suggestion": {
"text": "lucen hock",
"term": {
"suggest_mode": "always",
"prefix_length":0,
"field":"body"
}
}
}
}
Phrase Suggester
-
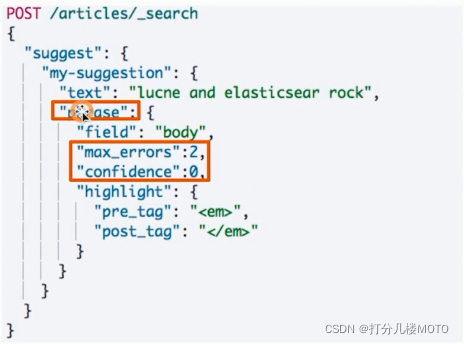
Phrase Suggester在Term Suggester上增加了一些额外的逻辑
-
一些参数
-
Suggest Mode : missing,popular,always
-
Max Errors : 最多可以拼错的Terms数
-
Confidence : 限制返回结果数,默认为1
-
- 自定义高亮
"highlight":{
"pre_tag":"<b id='d1' class='t1' style='color:red;font-size:18px;'>",
"post_tag":"</b>"
}
参考文档
-
Elasticsearch - phrase suggester - 听雨危楼 - 博客园 (cnblogs.com)
-
(31条消息) 09.phrase_suggester_寒夜-CSDN博客
The Complete Suggester
-
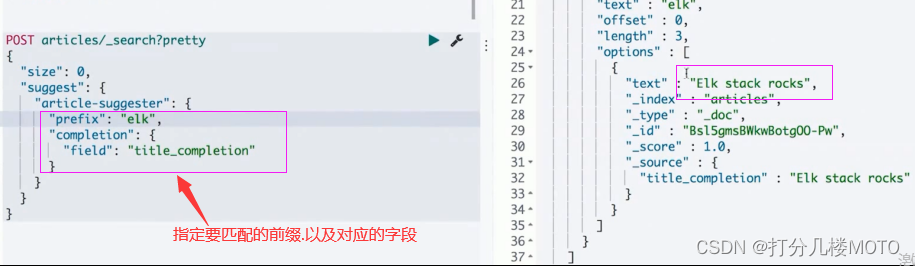
Completion Suggester提供了"自动完成"(Auto Complete)的功能,用户每输入一个字符,就需要及时发送一个查询请求到后台查找匹配项
-
对性能要求比较苛刻,ElasticSearch采用了不同的数据结构,并非通过倒排索引来完成.而是将Analyze的数据编码成FST和索引放在一起存放.FST会被ES整个加载进内存,速度很快
-
FST只能用于前缀查找
使用Completion Suggester的一些步骤
- 定义Mapping,使用"completion"type(针对某个字段)

- 索引数据

-
运行"suggest"查询,得到搜索建议
-
在任意的查询字符串中增加
pretty参数,会让Elasticsearch美化输出(pretty-print)JSON响应以便更加容易阅读。_source 字段不会被美化,它的样子与我们输入的一致。
-
Context Suggester
-
Completion Suggester的扩展
-
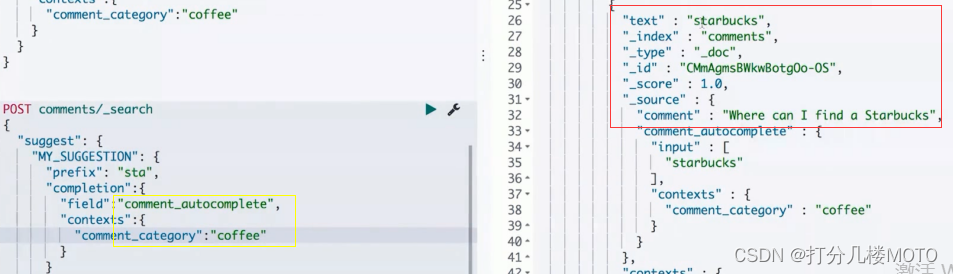
可以在搜索中加入更多的上下文信息,例如"star"
-
咖啡相关 : 建议"Starbucks"
-
电影相关 : "star wars"
-
实现Context Suggester
-
可以定义两种类型的Context
-
Category --任意的字符串
-
GEO -- 地理位置信息
-
- 实现Context Suggester的具体步骤
- 定制一个 Mapping

- 索引数据,并且为每个文档加入Context信息 如果 comment属于movies的上下文的时候就给他推荐"star wars";如果 comment属于coffee的上下文的时候就给他推荐"starbucks"

- 结合Context进行Suggestion
精准度和召回率
-
精确度
-
Completion > Phrase > Term
-
-
召回率
-
Term > Phrase > Completion
-
-
性能
-
Completion > Phrase > Term
-
这篇关于Elasticsearch-Suggest API的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





