本文主要是介绍使用unordered_write调优RocksDB写性能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在使用rocksdb存储的服务中,我们发现QPS在4w/s就怎么调整都上不去了,写性能受到了某种限制。为什么呢?下图描述了rocksdb写入的流程。我们发现 unordered_write = true可以提高写入吞吐量。

- rocksdb的数据正常写入流程是,多个线程形成一个queue(也叫write_group),不在这个queue线程的或者后面来的线程就等待,等待上一个queue所有所有数据写入完成了后,后面的线程也会组织成一个新的queue接着写入
- 一个queue的写入分二步,写wal和写mem,默认都统一由当时queue的lead 线程来完成,并且这二步是串行的。因为非当前queue的其它写入线程要一直等待当前queue的全部写入完成才开始执行,导致吞吐量上不去。
- unordered_write= true 的优化思路是当前queue的leader写入wal完成后,不用接着写mem而是首先通知当前queue的其它线程让它们自行写入mem,然后通知非当前queue的其它线程,这样其它线程会立马形成新的queue继续写入,新的queue就节省了等待上一个queue写mem的时间!这里做的好处当然可以大大提高吞吐量,但坏处是以前数据的一致性试图就无法保证。因为当前queue的返回了,这个时候mem才开始写,并没有写入完成,这个时候来读就可能读到老的数据。 简单地将unordered_write改为true,我们发现很QPS迅速飙升到10w/s+。这给了我们很大的惊喜。
unordered_write改为true为什么有效
我们对比两个参数的堆栈来看看到底有什么魔法:下图是我在相关函数加入跟踪代码,不同参数下的堆栈:
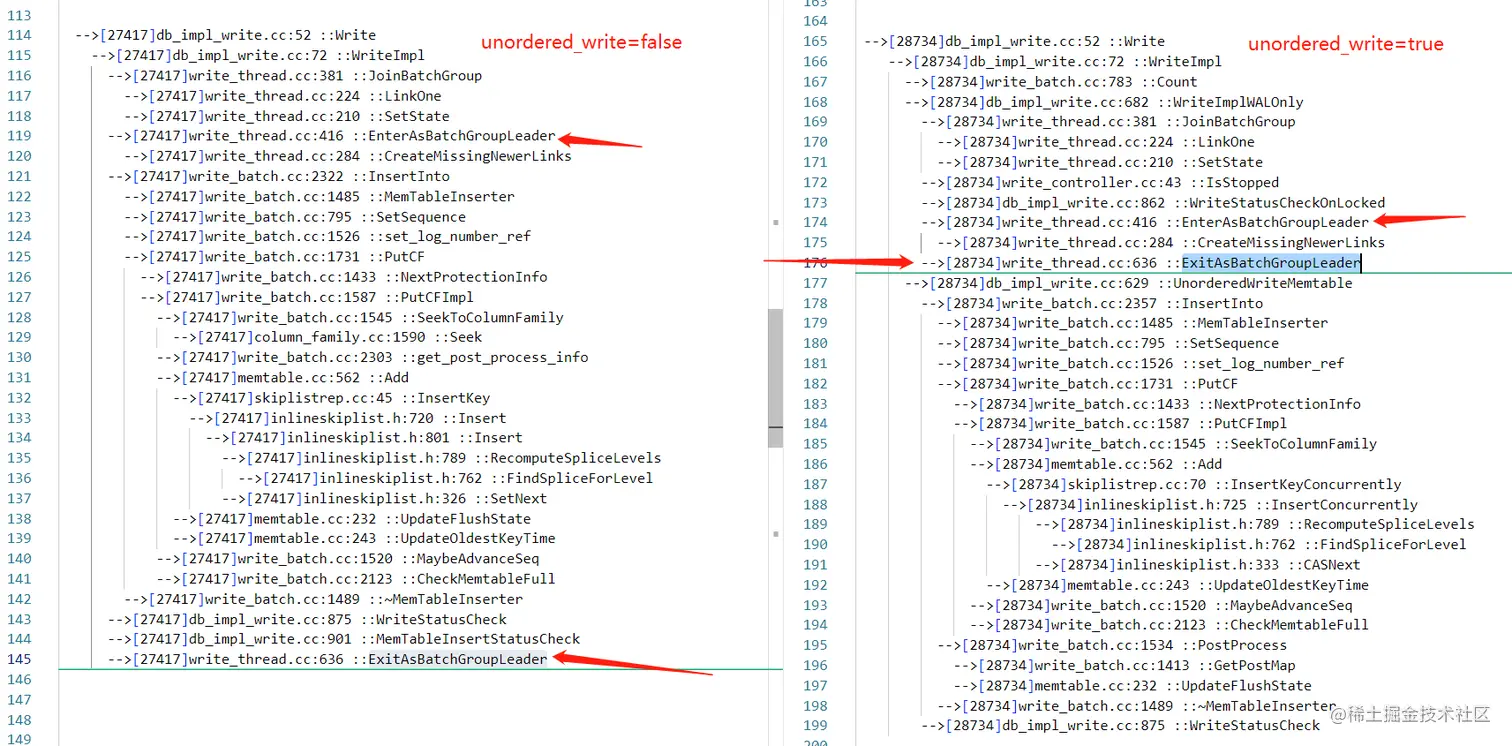
我们发现在unordered_write改为true后,write_thread.cc:636 ::ExitAsBatchGroupLeader被及早地调用,此时写memtable是其他线程都可以去写,注意,此时rocksdb的memtable是并发skiplist,在unordered_write改为true后调用的自选CAS版本的skiplist,效果显著。 我们进一步使用pref来看看调用CPU耗损:
unordered_write为false

unordered_write为true

我们看到基于提早释放,write_thread.cc:636 ::ExitAsBatchGroupLeader的效果:unordered_write = true的CPU耗损,对比下一张图,CPU占比减少了1倍之多,而还获取了4倍的写入性能。
这篇关于使用unordered_write调优RocksDB写性能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







