本文主要是介绍ThreadPoolTaskExecutor多线程跑任务时数据未跑完,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.问题描述:循环查数据,然后用多线程去更新查到的数据
代码如下:
建表语句
CREATE TABLE `tb_user` (`id` int NOT NULL AUTO_INCREMENT COMMENT 'id',`name` varchar(50) DEFAULT NULL COMMENT '名称',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
实体类
@Data
@TableName("tb_user")
public class TbUser {@TableId(type = IdType.AUTO)private int id;@TableField("name")private String name;
}
mapper
@Mapper
@Repository
public interface TbUserMapper extends BaseMapper<TbUser> {int updateByIds(List<TbUser> list);
}
xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.test.netty.mapper.TbUserMapper"><update id="updateByIds"><foreach collection="list" item="user" separator=";">update tb_user set name = #{user.name} where id = #{user.id}</foreach></update>
</mapper>service
package com.test.netty.service;import com.baomidou.mybatisplus.extension.service.IService;
import com.test.netty.pojo.TbUser;public interface UserService extends IService<TbUser> {void testThread();
}实现类
package com.test.netty.service.impl;import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.test.netty.mapper.TbUserMapper;
import com.test.netty.pojo.TbUser;
import com.test.netty.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.stereotype.Service;import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;import static com.baomidou.mybatisplus.extension.toolkit.Db.updateBatchById;@Service
@Slf4j
public class UserServiceImpl extends ServiceImpl<TbUserMapper, TbUser> implements UserService {@Resourceprivate TbUserMapper userMapper;@Autowired@Qualifier("taskExecutor")private ThreadPoolTaskExecutor taskExecutor;@Overridepublic void testThread() {log.info("开始批量更新流程");long start = System.currentTimeMillis();Long count = userMapper.selectCount(null);Integer pageSize = 500;int totalPages = count.intValue()/pageSize;if (count.intValue() % pageSize ==0){totalPages ++;}for (int i=1;i<totalPages;i++){Page<TbUser> page = userMapper.selectPage(new Page<TbUser>(i, 500), null);List<TbUser> list = page.getRecords();List<TbUser> users = new ArrayList<>();list.stream().forEach(user->{user.setName("test6");users.add(user);});int finalI = i;taskExecutor.execute(new Runnable() {@Overridepublic void run() {log.info("第{}次更新", finalI);updateBatchById(users,500);//userMapper.updateByIds(users);log.info("第{}次更新完成", finalI);}});}log.info("所有数据更新完成,耗时:{}",System.currentTimeMillis()-start);}
}线程池配置
package com.test.netty.config;import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;import java.util.Currency;
import java.util.concurrent.ThreadPoolExecutor;@Configuration
@Slf4j
public class TaskExecutorPoolConfig {private static final int workQueue = 5000;private static final int keepActiveTime = 30;private static final int CPU_COUNT = Runtime.getRuntime().availableProcessors();private static final int corePoolSize = 2 * CPU_COUNT;private static final int maxPoolSize = CPU_COUNT * 5;@Bean("taskExecutor")public ThreadPoolTaskExecutor myTaskExecutor(){ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setThreadNamePrefix("poolTest-");executor.setCorePoolSize(corePoolSize);executor.setMaxPoolSize(maxPoolSize);executor.setQueueCapacity(workQueue);executor.setKeepAliveSeconds(keepActiveTime);executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());executor.initialize();return executor;}
}mybatisPlus分页配置
package com.test.netty.config;import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class MybatisConfig {@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor(){MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new PaginationInnerInterceptor());return interceptor;}
}测试类
单元测试需要添加test依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency>
package com.test.netty.controller;import com.test.netty.mapper.DataMapper;
import com.test.netty.mapper.TbUserMapper;
import com.test.netty.pojo.DataDto;
import com.test.netty.pojo.TbUser;
import com.test.netty.service.DataService;
import com.test.netty.service.TestService;
import com.test.netty.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.util.ArrayList;
import java.util.List;import static org.junit.jupiter.api.Assertions.*;
@SpringBootTest
@Slf4j
class TestControllerTest {@Autowiredprivate TbUserMapper userMapper;@Autowiredprivate UserService userService;@Testvoid test1() {}@Testpublic void insertBatch(){for (int i=1;i<=10000;i++){TbUser user = new TbUser();user.setName(String.valueOf(i));userMapper.insert(user);log.info("第{}次插入",i);}}@Testpublic void test(){userService.testThread();}}
application配置文件
server:port: 8081
spring:application:name: netty-test-01datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/test?serverTimezone=Asia/Shanghai&characterEncoding=utf-8&allowMultiQueries=trueusername: rootpassword: root
步骤:
1.先运行测试类insertBatch方法,插入数据10000条。
2.运行test方法进行更新
问题
发现执行完成后更新的数据不完整,只有五千左右

然后自己写sql:
将实现类的方法注解放开
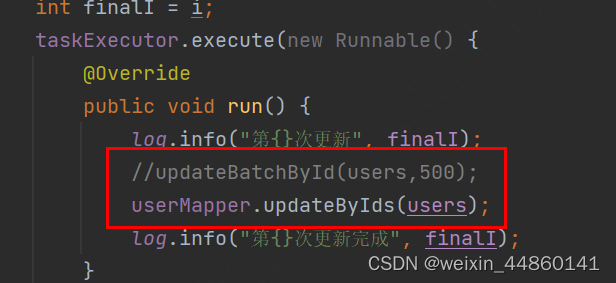
运行后发现数据全部更新完成
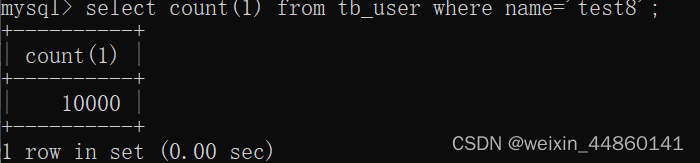
注意:test7或test8是我每次运行都会改一下修改的值,这个随便写,不用在意。
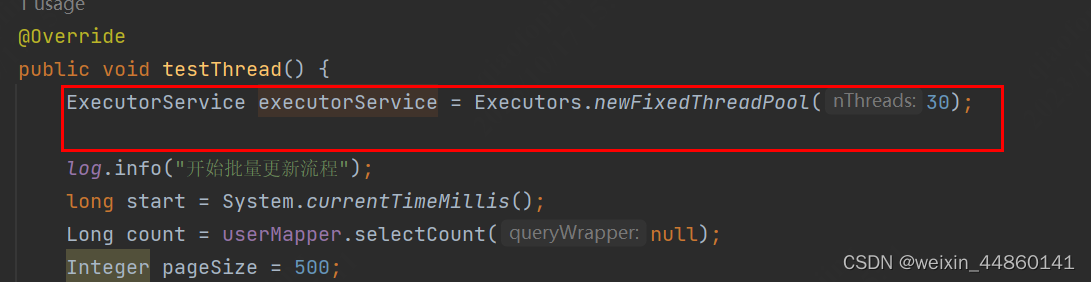
解决方法:使用ExecutorService线程池
未找到出现这个问题的原因,但是换了一个线程池后问题解决
在实现类中创建线程池
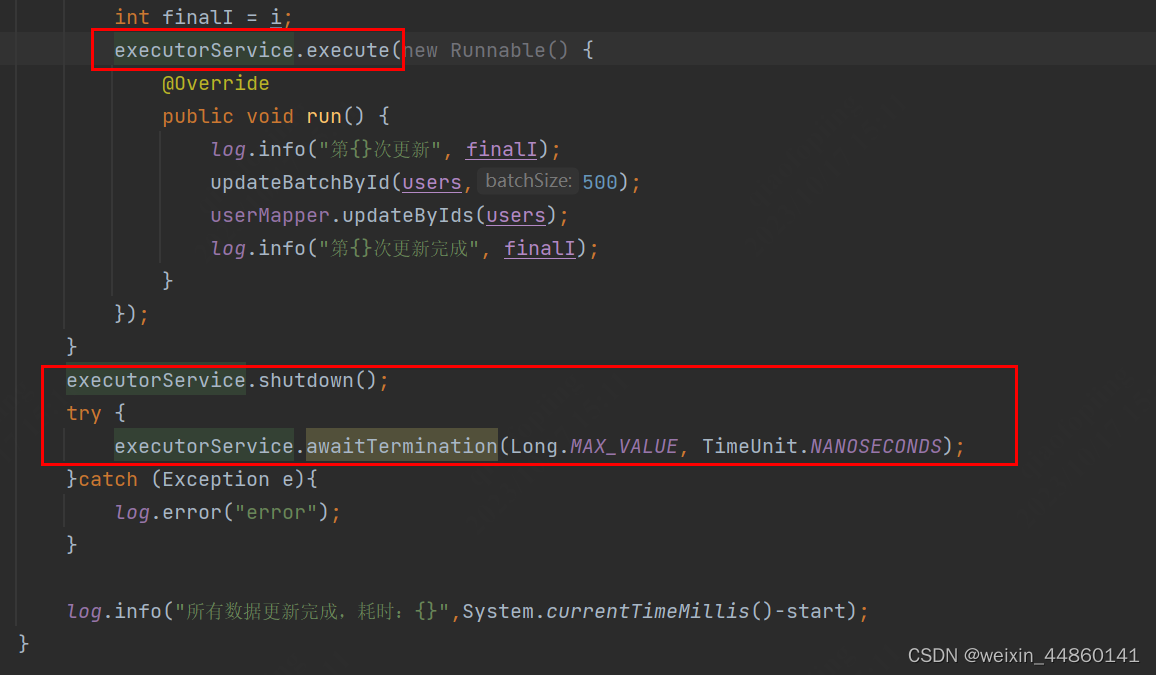
完成代码如下:
package com.test.netty.service.impl;import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.test.netty.mapper.TbUserMapper;
import com.test.netty.pojo.TbUser;
import com.test.netty.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.stereotype.Service;import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;import static com.baomidou.mybatisplus.extension.toolkit.Db.updateBatchById;@Service
@Slf4j
public class UserServiceImpl extends ServiceImpl<TbUserMapper, TbUser> implements UserService {@Resourceprivate TbUserMapper userMapper;@Autowired@Qualifier("taskExecutor")private ThreadPoolTaskExecutor taskExecutor;@Overridepublic void testThread() {ExecutorService executorService = Executors.newFixedThreadPool(30);log.info("开始批量更新流程");long start = System.currentTimeMillis();Long count = userMapper.selectCount(null);Integer pageSize = 500;int totalPages = count.intValue()/pageSize;if (count.intValue() % pageSize ==0){totalPages ++;}for (int i=1;i<totalPages;i++){Page<TbUser> page = userMapper.selectPage(new Page<TbUser>(i, 500), null);List<TbUser> list = page.getRecords();List<TbUser> users = new ArrayList<>();list.stream().forEach(user->{user.setName("test6");users.add(user);});int finalI = i;executorService.execute(new Runnable() {@Overridepublic void run() {log.info("第{}次更新", finalI);updateBatchById(users,500);userMapper.updateByIds(users);log.info("第{}次更新完成", finalI);}});}executorService.shutdown();try {executorService.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);}catch (Exception e){log.error("error");}log.info("所有数据更新完成,耗时:{}",System.currentTimeMillis()-start);}
}结果
无论使用哪一种方法,数据都能全部更新,ExecutorService会等待所有线程都结束后再去执行其他业务。
这篇关于ThreadPoolTaskExecutor多线程跑任务时数据未跑完的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





