本文主要是介绍Scholarly impact assessment:a survey of citation weighting solutions 2019翻译,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Scholarly impact assessment:a survey of citation weighting solutions
摘要
学术影响评价一直是一个热点问题。它在评价研究人员、科学论文、科学团队和科学机构方面发挥了重要作用。学术影响评估也用于解决基本问题,如奖励评估、资金分配、晋升和招聘决策。学者们普遍认为,使用加权引文来评估学术影响力更为合理。虽然大量研究者使用加权引文来获取学术影响力,但缺乏对引文加权方法的系统总结。为了填补这一空白,本文从文章、作者和期刊三个角度总结了现有经典的衡量学术影响力的指标和权重方法。总结了本文所涉及指标的重点和权重方法中所涉及的权重因素。最后,我们讨论了开放性问题,试图发现隐藏的趋势引文权重。通过本文,我们不仅可以对学术影响评价中的权重方法有一个更清晰的认识,而且可以对有待探讨的权重因素进行更深入的思考。
关键词
加权引文·学术影响评价·加权因子
1.介绍
学术影响力是指发表新的学术理论、方法或技术,或对原有成果进行开发、修改、改革和完善,从而影响相关领域的理论和实践(Van et al.2000;Kong et al.2018)。学术影响包括文章、作者、期刊、机构等的影响,学术影响评价在量化学术影响方面起着重要作用
研究人员、团队、机构和国家的科学贡献。它还用于解决以下基本问题,如奖励评估、资金分配、晋升和招聘决策(Bai等人,2017b)。
Bollen等人(2009)指出,科学是一种礼物经济。科学的价值是指一个人的思想对知识或他人思想的贡献。作者使用引文来确认影响他们工作的出版物。因此,学术影响力可以用出版物所收到的引文来衡量。传统上,一篇研究文章的重要性是通过引用来衡量的。这种方法招致了批评:如果我们将引用视为学术投票(davis2008),问题是,所有投票是否应该平等对待?在传统的引文分析中,引文是不加权的。平等对待所有引文忽略了引文发挥的各种功能(Zhu等人,2015)。例如,一篇被更具影响力的期刊引用的文章更有可能产生更高的实际影响。对于一个研究者来说,如果他/她的文章被更权威的研究者引用,他/她的研究就更有价值。期刊也是如此。此外,原始引用还有其他问题。例如,一篇文章或一篇期刊的引文会随着时间的推移而变化,旧的引文应该和新的引文一样对待吗?此外,作者倾向于引用自己的作品,一般来说,这些自我引用的价值较低。随着科学协作的发展,一篇文章可能由多个作者撰写,所有作者对这篇文章的贡献是否相等?研究还发现,不同研究领域的引文模式存在显著差异。因此,直接比较不同领域期刊的引文是不合理的(Vaccario et al.2017)。最后,但并非最不重要的是,存在负面引用(Cavalcanti et al.2011),它们可能会给上述所有场景带来额外的复杂性。
解决上述问题的关键是区别对待每一篇引文。这一目标可以通过将不同的权重与引文相关联来实现。排名越高,他们的学术影响力就越大。这是利用加权引文解决学术影响评价问题的基本原则。与原始引文相比,加权引文在学术影响评价中更为合理,因为它考虑了引文的一些潜在影响因素,并充分利用了这些因素。
关于引文权重的研究很多。许多评估学术影响的有效方法都使用加权引文。但对引文权重方法缺乏系统的总结。本文的贡献是总结现有的权重方法,解决学术影响的评估,以及发现隐藏的趋势和不足。
论文的其余部分组织如下。在经典学术影响评价指标部分,我们总结了学术影响评价领域的一些经典指标。在“学术影响评估的引文权重解决方案”一节中,我们总结了一些加权方法。在“公开问题”部分,我们提出了存在的问题和没有考虑到的问题。最后,在结语部分给出了本文的结论。
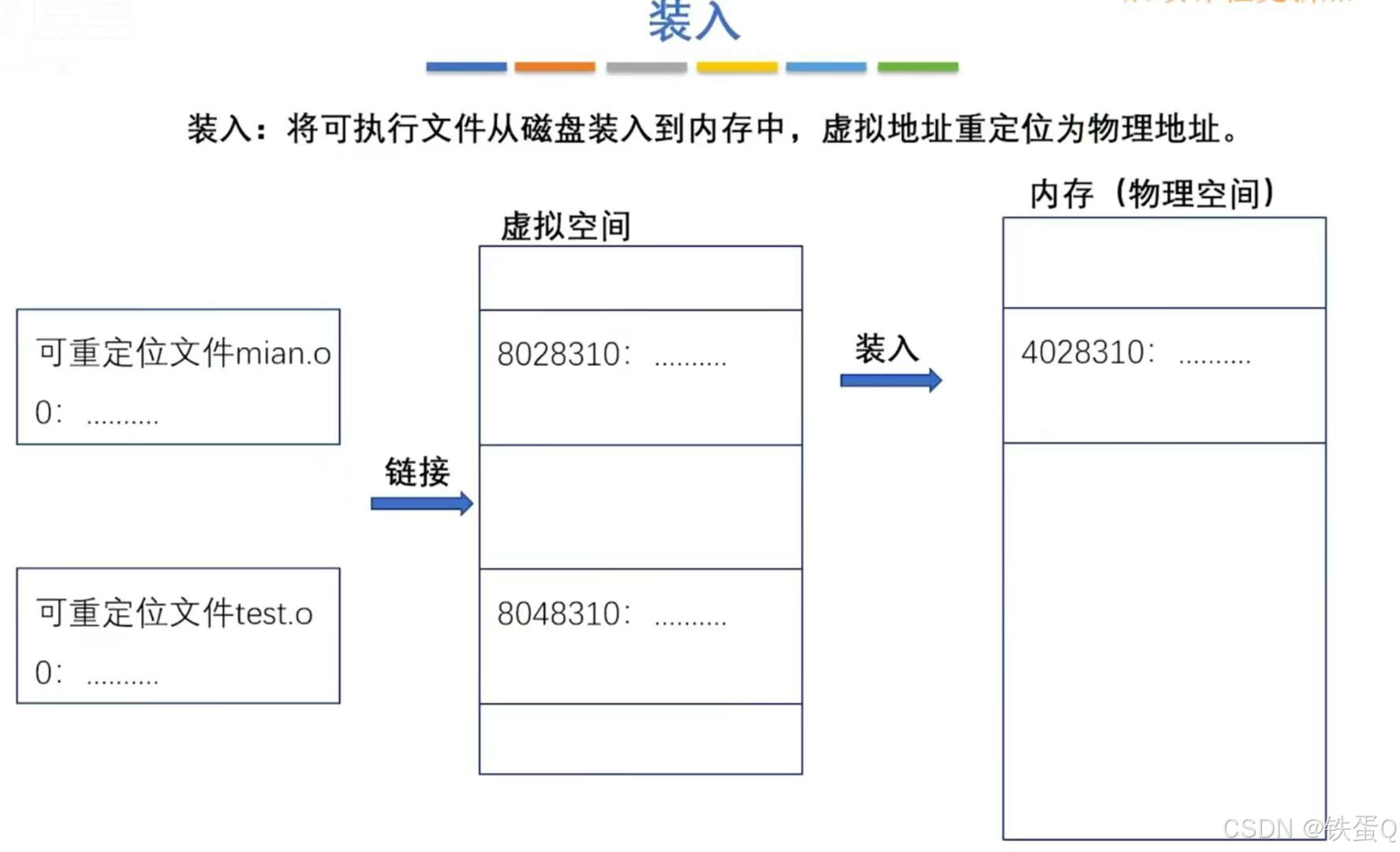
本文的总体结构如图1所示。

图****1学术影响评价的结构
表****1“经典学术影响评估指标”部分中的常见符号
2.经典学术影响评估指标
在科学研究评价中,我们经常使用一些指标来衡量学术影响力。在本节中,我们将讨论学术影响评估中常用的经典指标。我们在下表1中列出了常用的符号。
Indicators to evaluate authors
2.1评价H指数的指标
在评价学者影响的各种指标中,H指数(hirsch2005)是评价学者一生成就的最常用指标之一。可计算如下。学者的出版物按引文的数量按降序排列。如果有h篇论文被引用至少h次,则学者的h指数等于h,h指数是学者排名的第一个指标。但它的影响实际上远远不止于此。它也可以用来评估期刊和机构的影响。但是,它也有一些明显的缺点。
H指数的缺点是:(1)它强调长期观察,因为H指数需要时间积累;(2)它不能区分不同领域的普通科学家之间的差异;(3)由于没有引文的时间信息,它单调增加;(4) 除此之外,H-index还面临着基于引文的度量标准的典型问题,如:领域依赖性、自引、科学家识别、缺乏参考标准和全面的数据收集等(Costas和Bordons,2007;Jin等人,2007)。
2.2G‑指数
Egghe(2006)提出了G-指数,它对作者的第一个h出版物所收到的引文数量非常敏感。G指数不仅来源于H指数,而且是H指数的改进。它被定义为最高等级,这样收到的引文数量的累积和大于或等于这个等级的平方。G指数越高,说明学者的学术成就越高,其影响力越大。G指数很好地反映了高被引论文的影响力,克服了H指数的不足。
2.3Hg指数
阿隆索等人(2010)提出了一个新的指标来表征研究人员的科学产出,称为Hg指数,它是基于H指数和G指数计算的。它融合了前面两种措施的所有优点,并将它们的缺点最小化。研究者的hg指数计算为其H指数和G指数的几何平均值。汞指数有许多优点。例如,它不仅计算简单,而且比H-index和G-index粒度更大。此外,还考虑了高被引文章,弥补了H指数的不足。它还可以减少单个高被引论文的影响,弥补G指数的不足。
2.4A指数、R指数和AR指数
Jin(2006)提出了A-指数,它衡量了一位作者的第一篇h出版物的平均引用次数。A-索引简单地定义为美国好施公司核心出版物的平均引用次数(Jin等人,2007)。A指数达到了与G指数相同的目标。这两种方法都弥补了H指数对高被引论文不敏感的缺点。从数学上讲,A指数可以描述为

其中h表示作者的h-索引,表示引用次数按降序排列。然后他们提出了R指数(Jin et al.2007),该指数给出了美国好施公司核心中累积引文的平方根。后来他们提出AR指数(Jin et al.2007),将出版物的年代视为一个因素。这意味着,h-core中的出版物收到的引文数除以出版物的年代。在数学上,

2.5其他H型指数
为了解决H型指标的不足,优化其性能,提出了一系列其他H型指标,如-(Zhang 2009b),-(Wu 2010),()(Rousseau 2008),(Eck and Waltman 2008),(x),±(Wang 2013),这些指标都强调了高被引论文的价值。(Anderson等人,2008)考虑了所有论文的价值。研究者更关注被引用的新论文的贡献。(Batista et al.2006)和(Schreiber 2008)关注多作者影响分布。有很多
H型指数可以弥补H指数的一些不足,如-(Fiala 2014)。我们在表2中列出了一些H型指数的焦点。
评价期刊影响因子的指标
期刊影响因子(JIF)是科学信息研究所(ISI)为量化期刊影响而开发的一个指标。它因其简单而被广泛使用。假设总共有N个日志,第i个日志可以表示为。让(t,)表示t年中对时间窗口中发表的文章发出的引用数={t−1,−t}。(t,)指在本港发表的文章数目
. 那么在t年的JIF,时间窗t,可以描述为
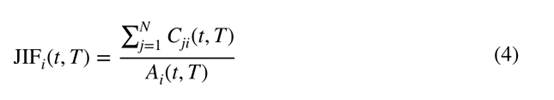
因此,如果一个期刊的JIF很大,那就意味着该期刊发表的文章频率更高,即该期刊的影响力更大。通常,时间窗口设置为两年。当选择一个较长的时间窗口时,JIF将考虑更多以前的出版物,因此结果将不那么直接(Garfield 2006)。例如,期刊引文报告(JCR)提供了5年影响因子作为替代。
随着JIF的广泛应用,人们对其进行了大量的讨论。首先,JIF不仅被广泛使用,而且被滥用,产生了扭曲和误导的结果。例如,JIF被错误地用于评估个人论文、作者、出版商和机构。这导致了功利主义甚至“影响因素狂热”(Hall和Page 2015;Casadevall和Fang 2014)。另一方面,JIF可能受到许多潜在因素的影响,如期刊的规模、类型、研究领域等(Dong等人,2005年;Elliott 2014年;Moustafa 2015年)。由于这些缺陷,越来越多的研究者,甚至出版商都呼吁反对JIF(Casadevall et al.2016;Callaway 2016)。
2.6即时索引
即时性指数是期刊一年内每篇文章的平均引用次数。更高的即时性指数表明该杂志的材料被引用和使用更快(Mathur等人,2009年)。因此,短小和快速出版的期刊在即时性指数上可能具有优势(Ha等人,2006年)。因此,即时性指标反映的是期刊的及时性,而不是期刊的质量。
2.7引用半衰期
引用的半衰期是JIF的有用补充,它衡量期刊的长期影响(Mathur等人,2009;Bornmann和Marx,2016)。一种时间长度,可以计算为一本期刊获得当前引用的50%的年数。Roldan的实验(Roldan Valadez et al.2018)表明,与JIF相比,引用的半衰期在特定领域提供了更准确的评估。
2.8日记账H‑索引
受H-index(Hirsch 2005)的启发,Braun等人(2006)提出了一个期刊H-index,如果一个期刊至少发表H篇论文并获得H篇引文,则等于H。由于期刊H指数能够同时反映期刊的质量和文章的数量,因此它比JIF更稳健、更均衡。Saad的实验(saad2006)表明,期刊H指数和JIF显著相关。因此,他们认为H指数可以作为JIF的替代品。Harzing和van der Wal(2009)声称,与JIF相比,H指数提供了更精确和全面的结果。
3学术影响评估的引文权重解决方案
迄今为止,许多学者和研究团体致力于利用引文权重研究学术影响力。在本节中,我们将分别从文章、作者和期刊的角度讨论学术影响评估中使用的加权方法。
表****3“文章评估的引用权重解决方案”部分中的常见符号
文章评价的引文权重解决方案。
由于本节中有很多公式,我们在下表3中列出了常用的符号。
用于文章评估的引文加权解决方案
3.1基于网络的加权方法
3.1.1CiteRank
学术文章影响力的评价在解决招聘决策、资金分配和晋升等问题上起着非常重要的作用。Walker等人(2007)提出了CiteRank,它更强调新文章。该模型指出,随机上网者最初是随着年龄呈指数分布的,这有利于最近的出版物。所以这些论文的学术价值应该更大。CiteRank模型基于PageRank算法。通过给新的发布分配一个更高的值,这种方法可以使新的发布通过随机浏览被发现的概率更大。然而,由于仅使用引文和时间信息,该方法仍然无法在最近的出版物之间获得合理的比较(Wang等人,2013)。
*3.1.2FutureRank*
我们希望找到一种新的方法,根据预测的未来引文对文章进行排名,因为这将帮助研究人员更容易找到高质量的文章。Sayyadi和Getoor(2009)提出了FutureRank,这是一种能够结合引用、作者和发表时间等信息,通过预测论文的未来排名,对科学文章进行有效排名的方法。该模型增加了一个个性化的时间向量,赋予最近发表的论文更多的权重。在这个模型中,作者身份的使用为最近出版物的排名提供了额外的信息。如果作者以前发表过许多有声望的文章,那么他/她的新出版物可能质量很好。右时间
3.1.3P-Rank
Ding和Yan(2010)提出了一个新的信息度量指标P-Rank,可以用来衡量论文、作者和期刊在异构引文网络中的地位。P-Rank可以区分引文的权重。换句话说,P-Rank可以区分每个引用的影响。就P-等级而言,一篇文章的影响力取决于四个因素:引用本文的作者、引用本文的期刊、引用本文的论文以及文章的发表时间。
*3.1.4MRFRank*
内容信息是衡量文章质量的重要指标,尤其是对于引用量较少的新文章。一般来说,一篇论文的创新性越强,其文本特征就越新颖。Wang等人(2016)首次提出了一种基于突发检测的文本特征创新度度量方法。他们提出了一个统一的模型MRFRank,它对文章和作者的未来影响进行排序,比如HITS算法。他们最大的贡献是利用文章内容信息来帮助识别潜在的有影响力的新文章。
*3.1.5Weighted quantum PageRank*
为了客观地衡量学术文章的影响,Bai等人(2017a)利用不同机构之间的地理距离和引文规律来加权quantum PageRank算法。他们认为,引文与院校之间的实际地理距离之间的关系是基于以下指数分布的。

其中z是引文,是初始值,x是实际地理距离,c是常数,t代表时间。根据引文规律,构造了加权量子PageRank算法。最后,他们发现与PageRank算法相比,这种加权量子PageRank算法能够更好地区分学术文章的影响。以机构间的地理距离作为权重因子是一种新的权重角度。它启发我们从不同的角度考虑问题。z0
*3.1.6EWPR*
Luo等人(2016)提出了一种称为集成启用加权PageRank(EWPR)的方法。该方法的具体过程如下所述。他们首先提出了时间加权PageRank,通过引入时间衰减因子来扩展PageRank。边缘上的冲击重量定义为
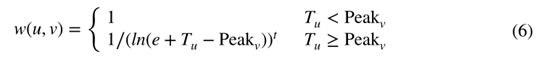
其中,是节点u上的时间信息,Peak是使用连接到v的所有节点的时间信息的节点v的峰值时间,t是衰减因子。然后采用一种集成方法对学术论文中涉及的异构实体的权威性进行集合。最后利用外部数据源进一步提高排名精度。他们的研究表明EWPR是一种很好的学术文章排名方法。
*3.1.7ALEF*
Wesley Smith等人(2016)提出了文章级特征因子(ALEF),这是一种新的基于引文的排名算法,可用于评估单个文章的影响。首先,他们使用ALEF计算每篇论文的引用分数。接下来,他们使用文章分数为每个作者生成分数。然后,他们将一篇论文的所有作者的分数结合起来,生成该论文的作者分数。最后,他们使用引文和作者分数来生成每篇论文的最终分数。
*3.1.8COIRank*
尽管基于引文的评价方法已经得到了广泛的应用,但异常引文的识别仍然是一个难题。在以往的研究中,研究者对引文背后的各种原因关注较少(Wang et al.2013;Zhou et al.2007),可能是因为难以识别异常引文。众所周知,在论文影响评价过程中,异常引用不可避免地会造成不公平和不准确。为了解决这一缺点,Bai等人(2016b)提出了一种基于正、负利益冲突(COI)的秩算法PNCOIRank,以获得正COI、负COI、正疑似COI和负疑似COI关系。它们利用利益冲突(COI)关系和团队关系来区分不同的引用权重。然后他们提出了COIRank(Bai et al.2016a),这是一种新的方法,不仅可以发现异常引文,而且可以分配低引用权重来削弱引文关系。与其他方法相比,COIRank方法有利于提高评价性能。
*3.1.9Neural network based weighted PageRank*
Fujimagari和Fujita(2015)提出了一种新的加权方法,可以基于神经网络自动为边缘分配权重。首先将引文网络划分为若干个簇,作为研究领域。然后对聚类中的每一条边计算四种加权因子。表示从第一篇到第j篇的引文数和从第一篇到第j篇的边的权重,分别表示第一篇的发表年份、参考文献集和作者集。那么权重因子可以表示为
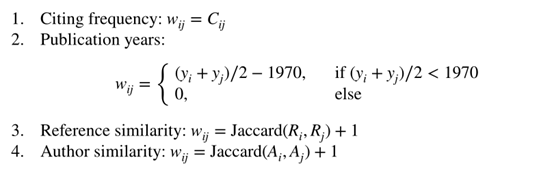
因此,每个边都有一个四维特征,然后输入神经网络。根据神经网络的输出更新各边的权值。
然后该过程再次从聚类开始,直到权重不再更新。理论上,这种加权方法可以找到上述四个因素的最佳组合。然而,在实际应用中,该模型并不总能找到最优值。
***3.1.10 Age‑and field‑rescaled PageRank
Vaccario et al.(2017)在引文z-score和其他相关工作的推动下,提出了年龄和领域重定标PageRank(p)。顾名思义,它考虑了字段差异和发布时间。他们还提出了年龄和领域重定标引文计数(c)。具体来说,如果表示第i篇文章并表示收到的引文数量,(c)of定义为

其中(c)和(c)是同一领域和同一年龄段的文章被引用次数的平均值和标准差。与之年龄相近的物品被定义为物品。它们是在同一时间出版的。
𝛥**c等于1000。(p) 可以通过将(c)中的引用数替换为的PageRank分数来计算。他们声称它比PageRank和按年龄加权的PageRank性能更好。
作者评价的引文权重解决方案
笔者认为,加权引文问题大致可以分为两大问题。一个问题是自引权重问题,另一个问题是合著者的贡献分配问题。
3.2基于引文的加权方法
*3.2.1自我引用解决方案*
在科学界,引文通常被视为奖励制度的一部分。但自我引用会扭曲这个体系。Kosmulski(2006)提出的-和Schreiber(2010)提出的-和Brown(2009)提出的-在计算引文数时都去掉了自引数。这相当于将自我引用的权重设置为零。我们将不讨论将自引权重设置为零是否合理。一个普遍认可的观点是,自引必须与其他参考文献区分开来,并且应该分配较少的权重。
舒伯特等人(2006)提出了一种分数方法来量化自引在合著者关系中的权重。首先,分数自引计数使用Jaccard索引来确定引文和引用文章之间的合著者重叠。如果引用作者与被引用作者之间的重叠较少,则它会赋予引用更大的权重。
***3.2.2****合作贡献分配方案*
一篇论文中有多个作者是很常见的,因此如何分配多个作者的贡献是一个不容忽视的问题。众所周知,H指数越来越多地被用来评价科学家个人的成就。但是,当我们使用总引文数或H指数来评估一位作者的学术影响力时,我们默认该作者对他的所有论文都有充分的评价。但这种假设对于多作者的论文来说显然是不合理的。Sekercioglu(2008)提出排名第k位的合著者被认为贡献了第一作者的1/k。但这种方法存在一些缺陷。首先,他没有仔细考虑通讯作者的贡献。事实上,通讯作者在论文中扮演着重要的角色,因此他/她的贡献不容忽视。此外,该方法的一个关键缺陷是作者权重最初衰减很快,但随后几乎保持不变。而理想情况下,他们应该遵循一个线性分布,即权重是成正比的作者排名。
张(2009a)提出了可以用来计算加权引文数和加权H指数的W指数。该方案的核心思想是对第一作者和对应作者设置相同的权重,其他作者的权重根据作者的排名线性下降。通过这种加权方案得到的加权引文和加权H指数可以更准确地评估作者的影响。
同样,Galam(2011)提出了基于裁剪的分配(TBA),第一作者和最后一作者(通常是对应作者)被赋予了很大的权重,而其他地方的作者在权重上也有所不同。以上两种方法都赋予第一作者和通讯作者较大的权重,更符合人们的主观认识。
Hagen(2010)提出了一种加权、谐波计数的方法。作者的名字排名越高,其权重就越大。每个协作者的权重随着协作者数量的增加而减小。然而,这种方法并没有给予相应作者具体的权重。解决合作者贡献的方法远远不止这些。
3.3基于网络的加权方法
*3.3.1 加权 PageRank*
事实上,论文之间的引用关系是一个巨大的网络,通过引用关系将所有的文章连接起来,形成一个引用网络(Fiala et al.2008)。因为一篇论文不可能引用一篇新发表的论文,所以这个网络是一个有向无环网络。受PageRank算法的启发,许多学者提出了加权PageRank算法,并将其应用于作者影响的评估(Nykl等人,2014、2015)。Yan和Ding(2011)利用加权PageRank算法来评估信息检索领域作者的学术影响力。它们将引用计数与网络拓扑结合到以下公式中:
式中(p)PRW**公司是作者p的加权PageRank,CC(p)是作者p收到的引文数,是网络中所有引文数,d是阻尼因子,(1−d)是将PageRank之和保留为1的系数,(pi)是的大纲行数。Ding和Yan(2010)将该算法扩展到非齐次引文网络。他们建议根据引用期刊的声望等因素对引用进行加权。
*3.3.2Author level eigenfactor*
West等人(2013年)建议使用作者水平特征因子度量来评估作者、机构和国家在社会科学研究网络(SSRN)社区中的影响。众所周知,特征因子得分最初是为学术期刊排名而设计的。West et al.(2013)提出,可以根据作者级引文数据对作者、机构和国家的学术产出进行排名。
*3.3.3TimeRank*
Franceschet和Colavizza(2018)提出了一种称为TimeRank的动态方法,用引文对作者进行评级。这种方法考虑了两位作者在被引用时的相对位置。它定义了引文奖励。的值介于0和1之间。如果引用作者的评分高于被引用作者的评分,则引用奖励接近1。相反,它倾向于为零。只有当被引用作者和被引用作者的评分相近时,被引用奖励才接近0.5。作者在时间t的评分由两部分决定:他们之前在时间−1的评分和引用作者在时间−1的评分。这种方法考虑了引文的动态性。
期刊评价的引文权重解决方案
由于本节中有很多公式,我们在下表4中列出了常用的符号。
表****4“期刊评价引文权重解决方案”部分中的常见符号
期刊评估的引文加权解决方案
3.4基于引文的加权方法
*3.4.1Weighted impact factors*
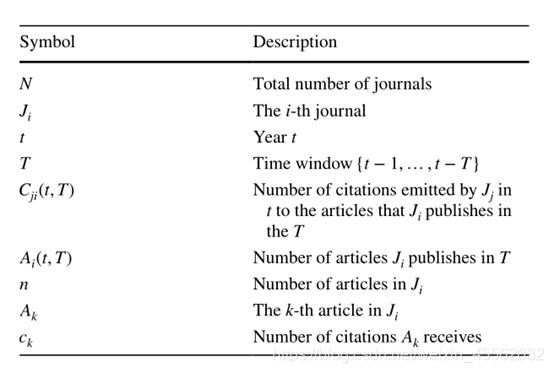
期刊的影响力是由两个方面决定的:一是统计引文,二是用引文的威信来衡量引文的权重。前者被称为受欢迎程度,后者被称为声望(Bollen等人,2006年;Franceschet,2010年)。由于JIF只能代表期刊的受欢迎程度(Bollen et al.2006),Habibzadeh和Yadollahie(2008)提出了加权影响因子(WIF),它考虑了期刊的相对声望。WIF的定义与JIF的定义相似。唯一的区别是JIF中的引文数量被加权引文所取代。具体来说,WIF定义为*
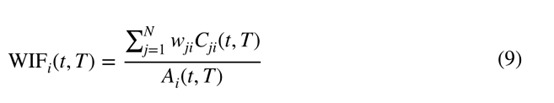
式中是(t,)的重量。显然,当加权因子等于1时,WIF等于JIF。
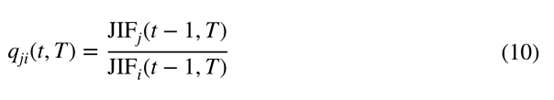
因为(t,)的值从零到无穷大变化很大,所以使用归一化的(t,)作为权重。
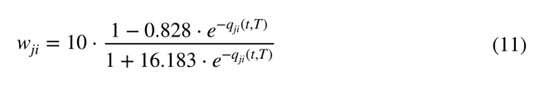
因此,对来自更著名期刊的引文赋予更大的权重,也就是说,来自更著名期刊的引文被认为更重要。为了得到更准确的结果,在首次计算WIF后,可以用WIF代替用于计算权重的JIF。Habibzadeh和Yadollahie声称WIF提供了一个比JIF更好的“尺度”。然而,Waltman和vaneck(2008)指出WIF存在一些严重的计算问题,这可能导致误导性的结果
后来,Zitt和Small(2008)提出了受众因素(AF)。AF和WIF的定义基本相同,只是重量不同。WIF从被引方的角度对引文进行加权,这对于同一领域的文章来说是足够的。然而,引用行为在不同领域有显著差异(Zitt等人,2005)。图2的数据来源于2014年的科学网。数据呈现了2014年27个领域的引用次数,反映了不同领域引用行为的差异。如图2所示,医学论文的被引次数最多,但每篇论文的被引次数低于平均水平,而多学科论文恰恰相反。因此,与WIF不同的是,AF从引用方对引文进行加权,取期刊的引用
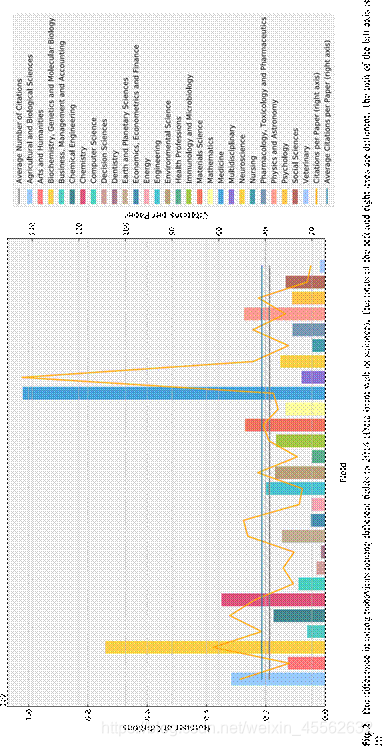
考虑的倾向。
引用倾向通过(t,)来衡量,即中文章发出的“活跃”引文的平均数量,其中活跃引文被定义为在时间窗口t中发出的引文。同样,让(t,)表示所有源期刊中文章发出的活跃引文的平均数量。然后,计算(t,)的重量为

因此,参考文献列表较短的期刊所引用的文献将获得更大的权重。AF独立于领域间不同的引用倾向,独立于领域分类系统。此外,文中还提出了一种基于字段的AF变量,将权重的分母替换为一个字段中文章的平均引用次数。Zitt和Small声称这种变体更为健壮,但它取决于野外分类系统。
Leydesdorff和Opthof(2010)介绍了另一种旨在消除场差异的加权方案。这种加权方案称为分数引用计数,它还考虑了参考文献列表的长度。然而,它没有像AF那样使用平均参考文献列表长度在期刊级别对引文进行加权,而是在文章级别对引文进行加权。例如,如果一篇文章引用了x篇文章,那么每一篇文章都可以算作1/x的引用,即该篇文章发出的每一篇引用的权重都是1/x,不同领域的文章发出的引用,由于引用行为的不同,权重也会不同。Leydesdorff和Bornmann(2011)声称,基于分数统计引文计算的JIF可以进行跨学科比较。然而,实验(Waltman和van Eck 2013;Waltman和van Eck 2013)表明,分数计数方案没有针对不同的场进行适当的规范化。
*3.4.2* *Crown indicators*
皇冠指标(也称为CPP/FCSm指标)是由科学技术研究中心(CWTS)创建的一个实地加权指标,用于评估一组出版物(期刊、研究组等)。在这里,我们把它作为期刊评价的一个指标。CPP和FCSm分别代表每份出版物的引文和平均领域引文得分。因此,CCP/FCSm指标定义为
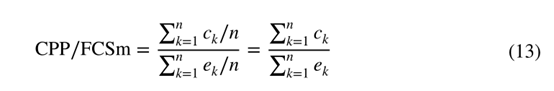
其中表示对的引用次数的期望,即对同一领域的所有文章的平均引用次数。由于引文的数量是由平均领域引文得分标准化的,因此CCP/FCSm指标具有跨学科可比性。Lundberg(2007)和Opthof and Leydesdorff(2010)指出,CCP/FCSm指标存在一些缺陷,其中最重要的一个缺陷是它对文章的聚合进行加权,而不是对单个文章进行加权。对于同一领域的期刊而言,CCP/FCSm指标在数学上与引文总数相同。因此,旧的出版物和评论在CCP/FCSm指标方面仍然具有优势。Moed(2010a)认为,选择这种加权方法是因为整体质量比引文的具体分布更重要。
Lundberg(2007)提出了引文z-score作为Crown指标的一种替代方法,Crown指标在文章层面衡量引文的权重。它采用z-score对引文进行规范化处理,以便综合考虑引文的分布情况s的标准化引文数定义为

式中和分别表示同一领域文章引文自然对数的平均值和标准差。注意,不是直接使用引文数量,而是引文z-score使用引文数量的对数(ck)来减少字段和期刊之间的偏度。然而,使用对数可能是一个缺点的情况下,人们只感兴趣的极端分布。最后,引文z评分被定义为期刊中所有文章的平均标准化引文。
Waltman等人(2011a)提出了平均标准化引文分数(MNCS)作为新的皇冠指标,这是另一个文章级字段标准化方案。可以认为,CPP/FCSm指标是平均值的商,而跨国公司指标是商的平均值。具体而言,跨国公司的定义是

与CCP/FCSm指标对高期望引文领域的文章赋予更多权重不同,跨国公司指标对引文的权重更为平均。Leydesdorff和Opthof(2011)指出,跨国公司使用的领域分类体系是重叠的,跨领域的文章没有很好的加权。尽管如此,Smolinsky(2016)的实验证明,跨国公司指标在保持计算简单性的同时满足一些基本要求。
Waltman等人(2011b)结合了MNCS的基本原理和基于PageRank的迭代方法,提出了一种称为递归MNCS指示符的递归字段规范化方案。该过程首先计算非递归的MNCS值,也称为一阶MNCS。然后,在计算二阶跨国公司时,对一阶跨国公司较高的期刊的引文赋予更大的权重。类似地,三阶跨国公司是基于二阶跨国公司来计算的。虽然同时用领域差异和声望来衡量引文的权重是合理的,但递归跨国公司指标的表现并不令人满意。它对分类系统和子场特征过于敏感。
*3.4.3* *SNIP*
Moed(2010b)引入了一个新的期刊评价指标,称为源标准化每篇论文的影响(SNIP),它可以被认为是AF的一个扩展。因此,与AF类似,SNIP也是一种引用侧规范化方案(在原文中表示为“源规范化”),考虑了引用倾向(或“引用潜力”)。然而,SNIP以更全面的方式对引文进行加权,考虑到参考文献列表的长度、引文成熟所需的时间以及用于评估的数据库的覆盖率。具体地说,SNIP的定义
其中RIP和RDCP分别代表每篇论文的原始影响和相对数据库引用潜力。数据库引用潜力(DCP)的定义是引用文章的参考文献列表的平均长度。的DCP除以的主题字段的DCP中值,称为RDCP。请注意,in-SNIP scheme的主题字段定义为引用的期刊集。因此SNIP独立于分类系统,可以消除特定主题或研究范围之间的差异。纪纪纪纪纪纪
Leydesdorff和Opthof(2010)指出了SNIP指标的一些不足。他们认为“SNIP违反了数学运算的顺序”。Waltman等人(2013)对SNIP进行了许多修改。修订后的SNIP解决了原SNIP存在的“反直觉”问题,引用权重的基本思想保持不变。实验(Pajić2015;Mingers和Yang 2017)表明,SNIP在规范化场差异方面做得最好。
3.5基于网络的加权方法
*3.5.1Y-factor*
如前所述,JIF只能反映期刊的知名度,而不能反映期刊的声望。考虑到期刊引用关系可以表示为期刊引用网络(节点表示期刊,有向边表示引用),Bollen等人(2006)提出加权PageRank算法可以作为期刊声誉的指标。用PageRank评价期刊威望的基本思想是,被许多著名期刊引用的期刊也可以被认为是有威望的。通过反复引用来重新分配期刊的声誉,最终达到一个稳定的状态,可以用来评价期刊的声誉。此外,Bollen等人(2006)认为引用期刊的声望应该与其引用其他期刊的频率相匹配。因此,它们定义了从到的边的权重,即从到的加权引文

其中是从到的引用次数。因此,例如,如果引用两次和一次,将获得的2/3的威望,而得到的1/3。
最后,Bollen等人(2006)提出了Y因子,即期刊的JIF与其加权PageRank值的乘积。因此,当期刊具有高JIF或高加权PageRank值或两者兼有时,它将具有高Y因子。Dellavalle等人(2007)声称Y因子比JIF提供了更精确的结果。
*3.5.2Eigenfactor*
Bergstrom(2007)提出了特征因子度量来评估期刊的影响,这也是受到PageRank算法的启发。与Y因子的加权PageRank部分类似,从有影响力的期刊获得更多引用的期刊被认为更具影响力。然而,eignfactor使用参考文献列表的字段平均长度来衡量每个引用(West等人,2010)。例如,如果引用期刊的字段引用每篇论文x篇文章,则每个引用的权重为1/x。注意,在特征因子度量中,完全排除自引,时间窗口设置为5年。由于期刊的质量不一定与期刊的规模有关,因此本文还提出了一种与期刊规模无关的文章影响力评分(AIS)指标。期刊的AIS定义为其特征因子得分除以发表的文章数。商标**纪纪商标
Davis(2008)和Fersht(2009)的实验表明,特征因子得分与总引文数显著相关,即特征因子提供的信息并不比原始引文数多。此外,Waltman和Van Eck(2010)发现特征因子与房颤之间存在显著相关性。他们声称,在大多数实际情况下,这两个指标可以被视为相同的。
*3.5.3 SJR indicators*
SCImago研究小组(Gonzalezpereira et al.2010)开发的SCImago期刊排名(SJR)指标是PageRank启发的另一个指标。虽然SJR indicator计算权重的方法与Y因子的加权PageRank部分相同,但是SJR indicator更好地处理了“悬挂节点”(不引用其他期刊的期刊)的问题。Eigenfactor和SJR indicator的主要区别在于使用不同的数据库(Ramin和Shirazi 2012),SJR indicator限制自引次数,而Eigenfactor排除所有自引,SJR indicator将时间窗口设置为三年。不同领域的不同研究人员对JIF、特征因子和SJR指标进行了比较(Ramin和Shirazi 2012;Kianifar等人2014;Cantin等人2015)。所有结果表明,同时考虑这三个指标更为合适。
后来,Guerrero Bote和Moya Anengón(2012)建议将SJR2指标作为SJR指标的改进。除了声望之外,SJR2指标还考虑了期刊的密切程度。贴近度是通过两种期刊的共引曲线之间的余弦来衡量的。余弦越大,两种期刊的主题越接近,权重应该越大。换言之,来自同一领域或同一特定学科领域的引文被认为更为重要。因此,与SJR指标相比,SJR2指标的声望分布更为平均。
***3.5.3****加权影响因子*
考虑到引文网络的结构,Zitt(2010)开发了另一种AF变体,它兼有上述两种AF变体的优点。它不使用期刊或领域中的文章来衡量引用倾向,而是使用特定邻域中的文章,根据引用关系来区分。其邻域定义为被引用期刊的集合。此外,的第二级邻域定义为的邻域,包括重复的邻域。让(t,)表示所有源期刊的二级邻域参考文献表长度的中位数,(t,)表示所有源期刊的二级邻域参考文献表长度的中位数。则式9中的重量计算如下:

式中,k(t,t)是使JIF和AF的标度相等的校正因子。由于AF变体可以基于引文网络检测研究领域,因此它独立于分类系统,这意味着它更健壮。但是,它仍然有一些局限性。对于参考文献较少的期刊,其结果并不十分准确。引用倾向可能受到参考文献列表长度编辑限制的影响。然而,AF可以有效地减少由于场间引用倾向不同而引起的偏差。
Zyczkowski(2010)提出了一种文章级加权JIF。这种加权方案是基于这样一种想法:一位科学家的文章被多次引用,他的引用比一位新来者的引用更为重要。具体来说,每个作者的权重是根据作者引用网络计算的。假设总共有样本作者,第i作者表示为。如果作者引文矩阵的前导特征向量为=(x,…),则其权重(ai)计算如下:

加权引文定义为

引用文章的作者人数在哪里。然后,将加权引文与时间窗T内发表的文章进行求和,计算出期刊的加权引文,该加权方案区分了每个引文的质量,从而减少了引文膨胀。然而,在实际应用中,很难区分相同的作者,也很难计算出一个巨大矩阵的特征向量。
4公开发行
真实性和公平性是学术影响评价的最基本原则。所有指标和方法都应允许这一原则。在现有的学术影响评价方法的基础上,还存在一些有待解决的问题,需要在今后的工作中加以解决。在本节中,我们将对这些问题进行简要介绍。
4.1有待探讨的权重因素
我们在表5中列出了已知的所有权重因子。对于不同的评价对象(文章、作者或期刊),研究者倾向于选择不同的权重因子。期刊评估指标倾向于按领域或来源对引文进行加权。然而,文章评价指标往往考虑发表时间和引用的副作用,而作者评价指标则特别关注自引和合著问题。Vaccario等人(2017)将年龄和领域因素结合起来进行文章评估,结果是积极的。因此,有可能了解哪些权重因子可用于不同的评估对象。例如,发表时间可能是期刊评价的一个重要权重因素,作者所属领域可能会影响其引用行为。像这样的问题还需要进一步研究。
此外,还有其他一些因素尚未充分探讨,但可能有用。具体而言,特征如出现频率(Zhu et al.2015)、时间间隔、引用句子的平均长度、引用出现的平均密度(Wan and Liu 2014)、发表语言(Ordunalea and Lopezcozar 2014)、关键词相似性(Fujita et al.2014)和社会网络影响(Priem and Hemminger 2010;Costas等人(2015年)可能是有价值的因素。
表****5在学术影响评估中可以加权的因素
| 评价对象 | 加权因子 |
|---|---|
| 文章 | 引用作者、期刊、文章的声望 (丁和严2010;萨亚迪和格图尔2009) 出版时间、语言(Walker等人,2007年) (Sayyadi和Getoor,2009年;Fiala,2012年;Abujbara等人,2013年)正面、中性和负面引用 (Bai等人,2016a;Valenzuela等人,2015;Wan和Liu,2014) 机构间的地理距离(Bai等人,2017a) 是否属于交叉领域(Vaccario et al.2017) 是否属于研究前沿(Fujita et al.2014) 引用的位置特征(Valenzuela等人,2015) 引用次数(Zhu等人,2015) 引用句子的平均长度(Abujbara等人,2013年) 引文出现的平均密度(Wan和Liu 2014) 参考相似性(Fujimagari和Fujita 2015) 作者相似性(Fujimagari和Fujita 2015) |
| 作者 | 合著者贡献的分布(Sekercioglu 2008) (张2009a;加拉姆2011;哈根2010) 是否自引(Kosmulski 2006;Schreiber 2010;Brown 2009) 作者是否来自同一机构(Bai等人,2016a) 作者是否合作过(Bai等人,2016a) |
| 期刊 | 引用期刊、作者的声望 (Habibzadeh和Yadollahie,2008年) 字段或邻域中引用列表的平均长度 (Zitt 2010年) 每篇文章的引用次数 (Leydesdorff和Opthof 2010) 每篇文章所属领域的平均引用次数之和 (Leydesdorff和Opthof 2010) 出版时间(Moed 2010b) 数据库覆盖率(Moed 2010b) 期刊的封闭性(Guerrero Bote和Moya Anegón,2012) 引用期刊的引文数量(Zyczkowski 2010) |
4.2有待探讨的加权方法
Valenzuela等人(2015年)提出了一种监督分类方法,用于识别学术出版物中的重要引文。他们把引文分为两类:重要引文和附带引文。他们将出现在方法或讨论部分的引文视为重要引文,而相关工作部分的引文视为附带引文。不管这种分类方法是否合理,在这种分类方法的基础上建立一个综合指标是一个好主意。具体来说,可以根据分类结果对引文赋予权重,然后计算加权JIF或加权h指数等。此外,自然语言处理(NLP)还可以用于检测正、中、负引文或引用目的(Abujbara et al.2013;Jha et al.2017)。同样,也可以在此基础上构建综合评价指标。
4.3数据库偏差
许多潜在因素可能导致数据库偏差。首先,分类系统因数据库而异,有些分类系统过于宽泛,无法进行引文分析。因此,对于依赖于分类系统的指标,数据库的偏倚不容忽视。因此,提出了基于引文关系的不同分类系统(Waltman和van Eck 2012;Gómez-Núñez等人2014;Ruiz Castillo和Waltman 2015)。然而,没有一个标准的方法来评估分类系统,也没有一个指标在分类系统上的表现如何。要解决这个问题还需要进一步的研究。
其次,缺失数据和数据库覆盖率可能会影响评估结果。无论是直接利用引文数量还是构建引文网络,都要保证引文数据的可靠性和真实性,才能得到准确的评价结果。Su等人(2011)提出了PrestigeRank,使用“虚拟节点”来弥补缺失的数据。PrestigeRank仍有局限性,需要更多的研究。
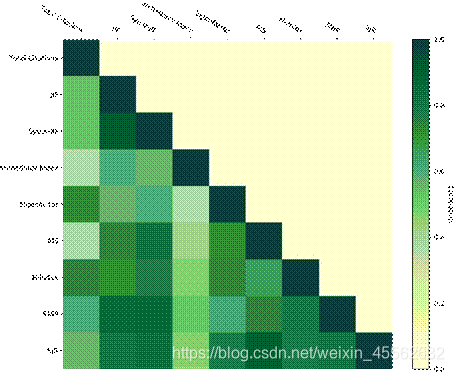
图****3某些指标之间的相关性,来自Mingers和Yang在评估商业和管理期刊中的实验数据Mingers和Yang(2017)
4.4合作者的贡献分布
协作文章中学术贡献的分配是另一个问题。虽然有大量学者提出了解决这一问题的方法,但这些方法并不一定合理。一种新的观点是,当我们审查作者对学术论文的贡献时,我们需要考虑作者发表的其他相关论文。作者其他相关论文的影响力越大,作者对这篇学术论文的贡献就越大。
4.5通用指示器
研究人员一直在努力寻找一个完美的学术评估指标。在过去十年中,提出了许多指标。尽管定义、加权因子和加权方法各不相同,但其中只有少数提供了额外信息(Waltman 2016)。某些指标之间有很强的相关性,如图3所示。可以理解,一个指标很难涵盖各个方面。然而,也许有一些现有的指标从不同方面反映了学术影响的组合。可作为通用指示剂。
5.结论
学术影响的评估是非常有意义的。这也是学术界最流行的趋势之一。有无数的研究人员和研究团队致力于利用统计分析、机器学习、数据挖掘或网络科学等关键技术对学术影响评估进行研究。虽然新的方法和技术不断涌现,但在加权引文方向上仍有很大的发展空间。当我们使用加权引文评价期刊、作者或文章时,评价结果反映的是他们各自的声望,而不是受欢迎程度。因此,加权引文可以更好地反映期刊、作者和文章的学术影响力。本文综述了现有的期刊、作者和文章的加权因子和加权方法。经过总结,我们发现其背后的各种特征会导致引文分析的偏斜和不公平,因此我们考虑了多种因素来衡量引文的权重。尽管如此,并没有一个完美的加权方法,因为很难证明一个指标优于另一个指标。为了不断完善绩效指标和方法,更准确地评估学术影响,可以考虑各种方法的优点和可以加权的因素。我们希望这篇简短的综述将有助于研究者在未来找到更合理的评估学术影响的方法。
这也是学术界最流行的趋势之一。有无数的研究人员和研究团队致力于利用统计分析、机器学习、数据挖掘或网络科学等关键技术对学术影响评估进行研究。虽然新的方法和技术不断涌现,但在加权引文方向上仍有很大的发展空间。当我们使用加权引文评价期刊、作者或文章时,评价结果反映的是他们各自的声望,而不是受欢迎程度。因此,加权引文可以更好地反映期刊、作者和文章的学术影响力。本文综述了现有的期刊、作者和文章的加权因子和加权方法。经过总结,我们发现其背后的各种特征会导致引文分析的偏斜和不公平,因此我们考虑了多种因素来衡量引文的权重。尽管如此,并没有一个完美的加权方法,因为很难证明一个指标优于另一个指标。为了不断完善绩效指标和方法,更准确地评估学术影响,可以考虑各种方法的优点和可以加权的因素。我们希望这篇简短的综述将有助于研究者在未来找到更合理的评估学术影响的方法。
参考文献:
[1]Liwei Cai, Jiahao Tian, Jiaying Liu, Xiaomei Bai, Ivan Lee, Xiangjie Kong, Feng Xia:Scholarly impact assessment: a survey of citation weighting solutions. Scientometrics 118(2): 453-478 (2019)
这篇关于Scholarly impact assessment:a survey of citation weighting solutions 2019翻译的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![BUUCTF靶场[web][极客大挑战 2019]Http、[HCTF 2018]admin](https://i-blog.csdnimg.cn/direct/ed45c0efd0ac40c68b2c1bc7b6d90ebc.png)