本文主要是介绍Python爬取CNKI论文的信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
学了2天,简单的来总结一下。因为毕业设计是有关于推荐系统的相关内容,利用python爬取文献库是里面最基础的一步。
代码无任何难度,不懂得直接复制代码上网查询也能明白具体代码的意思。
选择CNKI的原因很简单:
1、知网的网页源代码中,查询的结果是存储在iframe里面的,单纯的python+request是很难读取到iframe里面的内容的。我爬了一个晚上没爬出来。。
2、CNKI的网页源代码中,查询的结果没有iframe等框架,相对来说容易爬取。
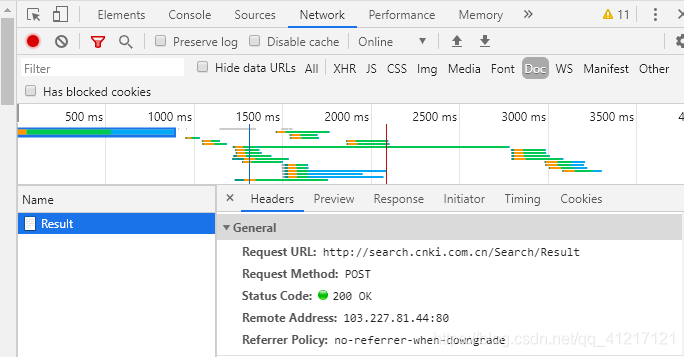
1、利用post的方法获取网页信息
CNKI和其他文献库不一样,当你在搜索框里搜索相应的内容的时候,跳转的页面的url还是原先未跳转的url,会出现url为定向的问题。此时不能用urlopen的方式采取get方法进行网页的爬取。我最终选择了request的表单数据提交方式。
2、利用beautifulsoup进行网页相应标签的爬取
beautifulsoup对于网页源代码中的特定标签的读取特别方便,所以最终采用的还是beautifulsoup的方式。
对于我个人的需求,我的爬取论文的情况对应的应该是第一种不包含任何图片,且有关键字提示;第二种不在我的爬取范围之内。
1、在beautifulsoup中,这两种链接的爬取区别区分不明显,且tag高度重合,所以此时我不能用beautifulsoup的find方法去读取a标签。
2、我的想法是一个论文的相应条目分开读取;
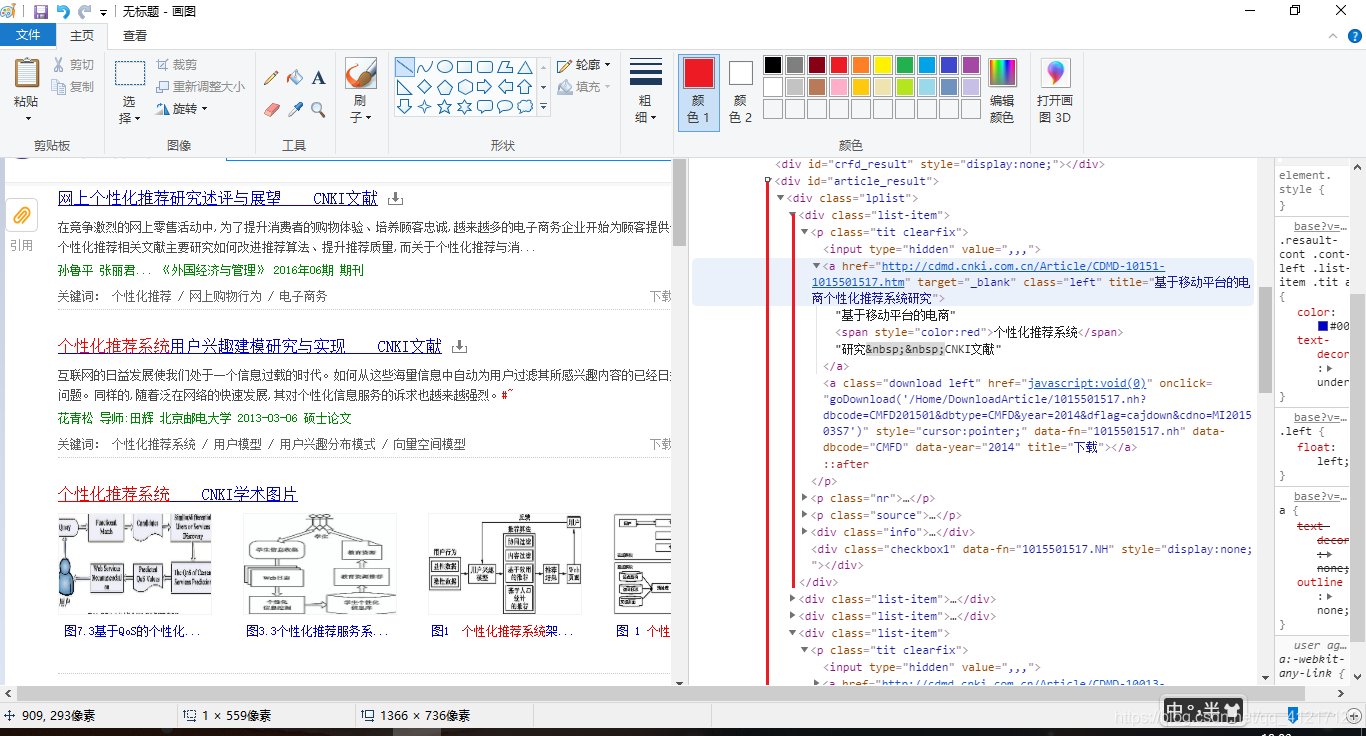
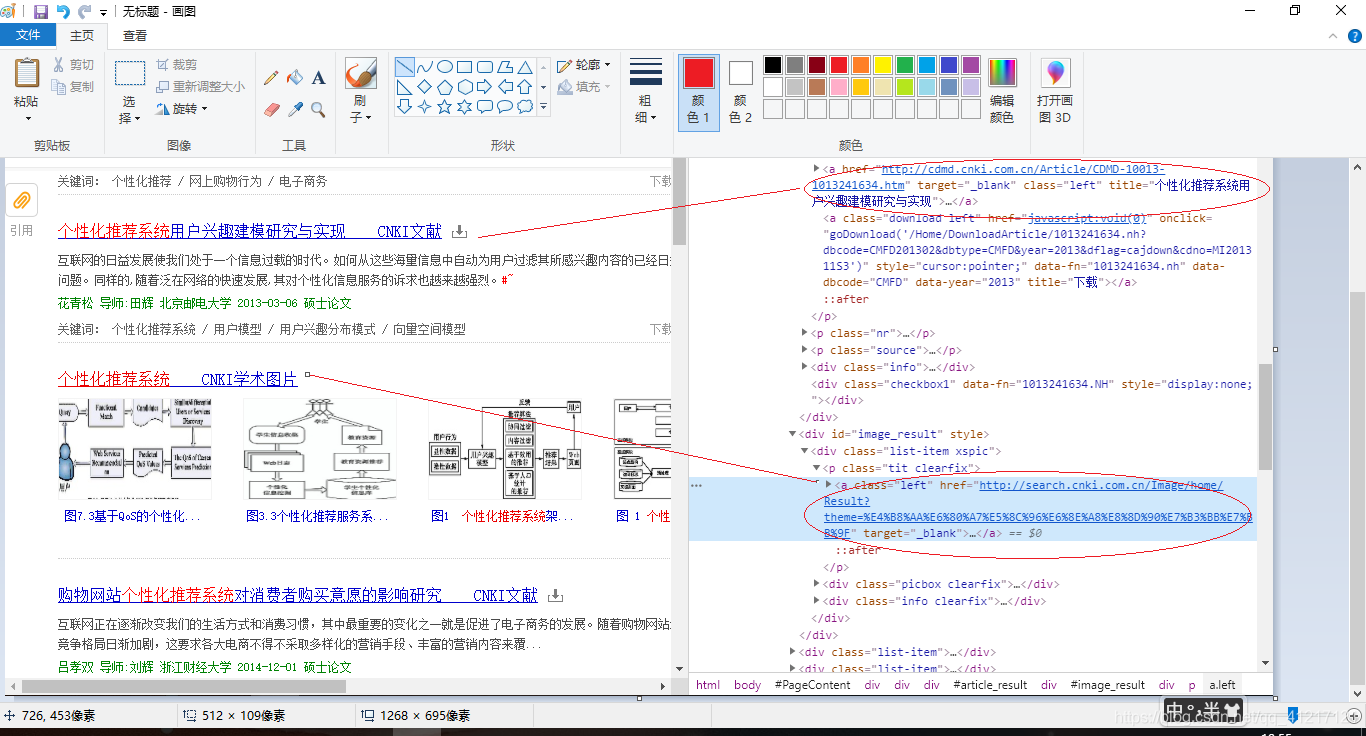
可以看出,搜索结果的一条结果,是在一个div class="list-item"里面的;而所有的搜索结果,是在一个div id = "article_result"里面的。所以我们的搜索方案现在就很明确了。
1、先将div id = "article_result"的内容全部爬取,里面包含了所有子的div class=“list-item”
2、针对每个div class=“list-item”,读取里面的论文题目和相关的关键字
为什么我不知觉读取所有的div class=“list-item”?因为通过观察可以发现,并不是所有的div class="list-item"标签里都会包含数据。在div id = "article_result"标签的范围之外,有很多div class="list-item"是不包含数据的。
3、利用beautifulsoup的方法将每个搜索结果读取,存入集合里面
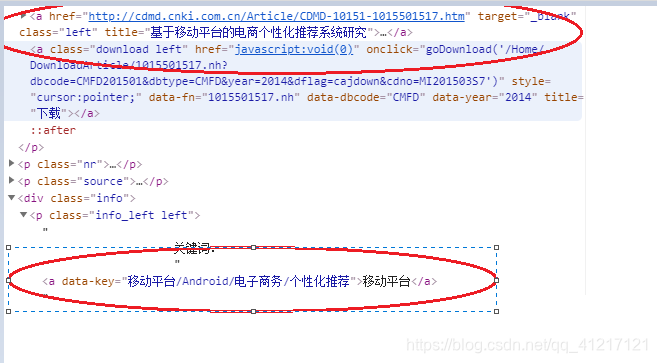
从图片的代码很容易得出,第一个圈的代码,我们需要从里面得出标题数据,数据在title属性里面;第二个圈得出的是关键词,数据在data-key属性里面。这里的解决方案可以利用正则表达式解决。
代码如下所示:
from bs4 import BeautifulSoup
from urllib.request import urlopen
import re
import random
import requestsurl = "http://search.cnki.com.cn/Search/Result"
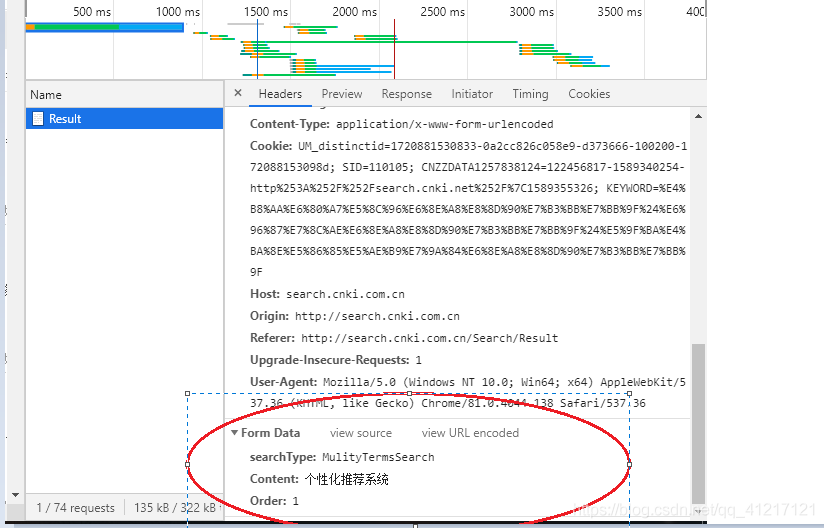
data = {'searchType': 'MulityTermsSearch', 'Content': '基于内容的推荐系统'}
#此处的data存储的post所提交的参数,从第一步的图片能看的出来
titles =[]
#存储从CNKI读取的所有标题
tags = []
#存储读取的每个标题对应的关键字res = requests.post(url, data=data)
html = res.text
soup = BeautifulSoup(html,'lxml')sum_article = soup.find("div",{"id":"article_result"})
sum_div = sum_article.find_all("div", {"class":"list-item"})for sub_div in sum_div:
#对于article里面的list-item作数据爬取if sub_div != None:sub_title = sub_div.find("a", {"target": "_blank", "title": re.compile("(.+?)"),"href": re.compile("http://(.*?).cnki.com.cn/Article/(.*?)")})#此处用标签加上相应的正则表达式,可以爬出所有包含论文标题的数据sub_tag = sub_div.find("a", {"data-key": re.compile("(.+)")})#此处用标签加上相应的正则表达式,可以爬出所有包含论文标题的关键字titles.append(sub_title['title'])tags.append(sub_tag['data-key'])print(titles)
print(tags)print(titles.__len__())
print(tags.__len__())
if tags.__len__() == titles.__len__():print("长度相等")
#用来判断爬出的论文标题数量,和对应的关键字数量是否相等。相等即爬取正确`建议可以去b站看一下莫烦python,讲的挺好的,可以快速入门以下基础。
这篇关于Python爬取CNKI论文的信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




