本文主要是介绍ja3指纹 笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
通过给openssl和nginx打补丁获取ja3指纹:
https://github.com/phuslu/nginx-ssl-fingerprint

这个项目算出来的ja3指纹和wireshark的不完全一致,wireshark后面的是“-21,29-23-24,0”, 小小不同,👀。。
通过wireshark查看ja3指纹
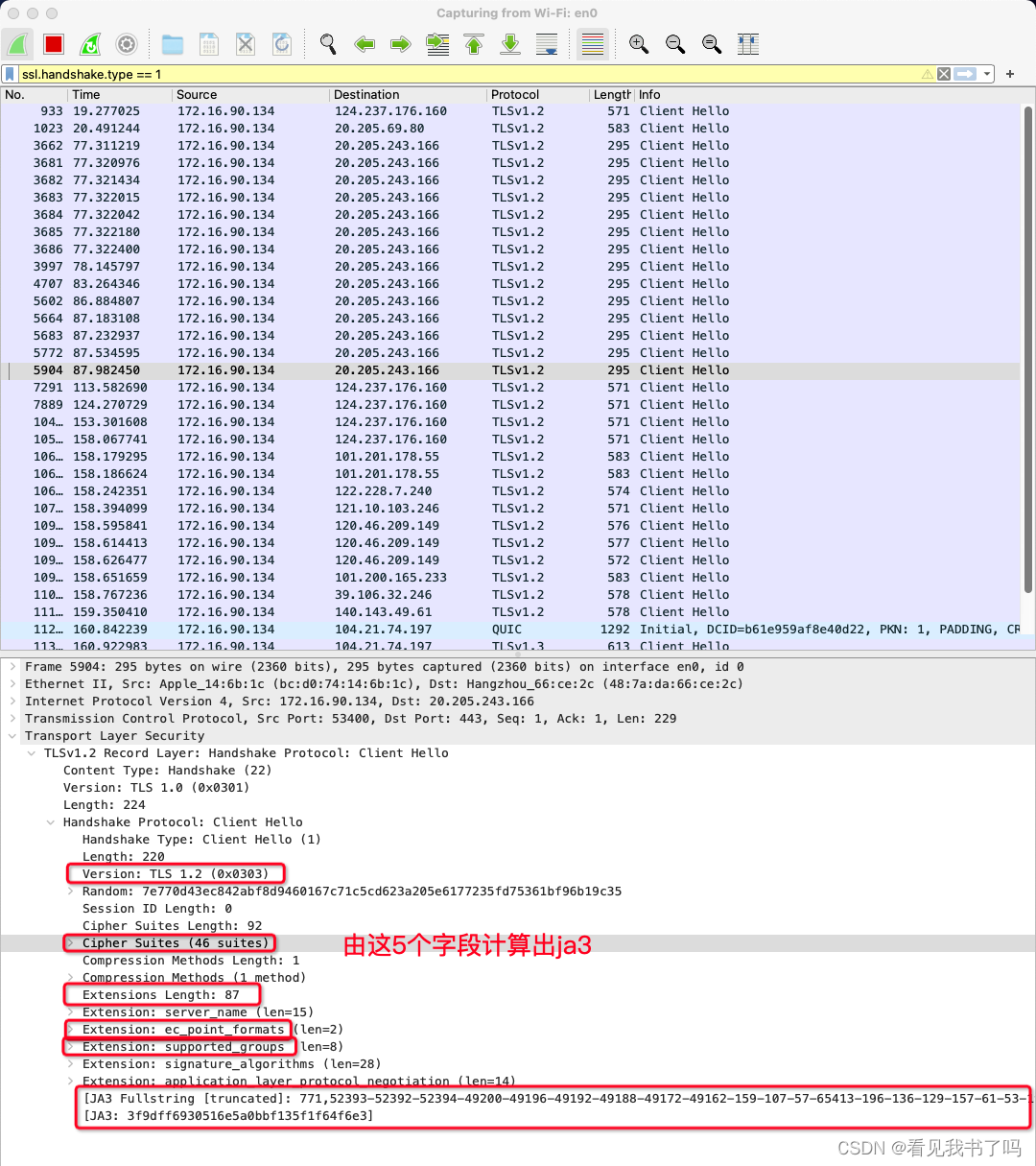
ssl.handshake.type == 1过滤出 Client Hello 包
如何绕过 JA3 指纹校验?
https://cn-sec.com/archives/1358869.html
【粉丝投稿】Aiohttp 与 Scrapy 如何绕过 JA3指纹反爬机制
https://mp.weixin.qq.com/s/tuZScT0qVwPl6bQewqz0zg
【粉丝投稿】scrapy 如何突破 ja3指纹
https://mp.weixin.qq.com/s/Zi26P1bAO85jOlEmSAZRgg
middlewares.pyimport random
from scrapy.core.downloader.handlers.http import HTTPDownloadHandler
from scrapy.core.downloader.contextfactory import ScrapyClientContextFactory
ORIGIN_CIPHERS = 'TLS13-AES-256-GCM-SHA384:TLS13-CHACHA20-POLY1305-SHA256:TLS13-AES-128-GCM-SHA256:ECDH+AESGCM:ECDH+CHACHA20:DH+AESGCM:DH+CHACHA20:ECDH+AES256:DH+AES256:ECDH+AES128:DH+AES:RSA+AESGCM:RSA+AES'
def shuffle_ciphers():ciphers = ORIGIN_CIPHERS.split(":")random.shuffle(ciphers)ciphers = ":".join(ciphers)return ciphers + ":!aNULL:!MD5:!DSS"class MyHTTPDownloadHandler(HTTPDownloadHandler):def download_request(self, request, spider):tls_cliphers = shuffle_ciphers()self._contextFactory = ScrapyClientContextFactory(tls_ciphers=tls_cliphers)return super().download_request(request, spider)settings.pyXIGUA_APP["DOWNLOAD_HANDLERS"].update({"https": "crawler.toutiao_luban.middlewares.MyHTTPDownloadHandler","http": "crawler.toutiao_luban.middlewares.MyHTTPDownloadHandler",}
)这篇关于ja3指纹 笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








