本文主要是介绍Elasticsearch cannot downgrade a node from version [7.x.x] to version [7.x.x],希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 背景和问题分析
- 1. 最简单方案
- 2. 复制数据仓库
cannot downgrade a node from version [7.x.x] to version [7.x.x]
Elasticsearch降级实践
背景和问题分析
首先官方是不支持降级的,想要降级必须从快照中恢复,这是最保险的,前提也比较多,成本较高。
但是你做了很小的版本升级,过后又非常想回退到原来的版本,怎么办呢?
注意:我的Elasticsearch是单机模式,集群模式自行研究吧。
以我的操作环境为例:从7.13.4回退到7.11.2。
直接启动7.11.2,报错如下:
cannot downgrade a node from version [7.13.4] to version [7.11.2]
报错原因是启动时会检查,当前服务版本和集群内部状态的版本,源码如下
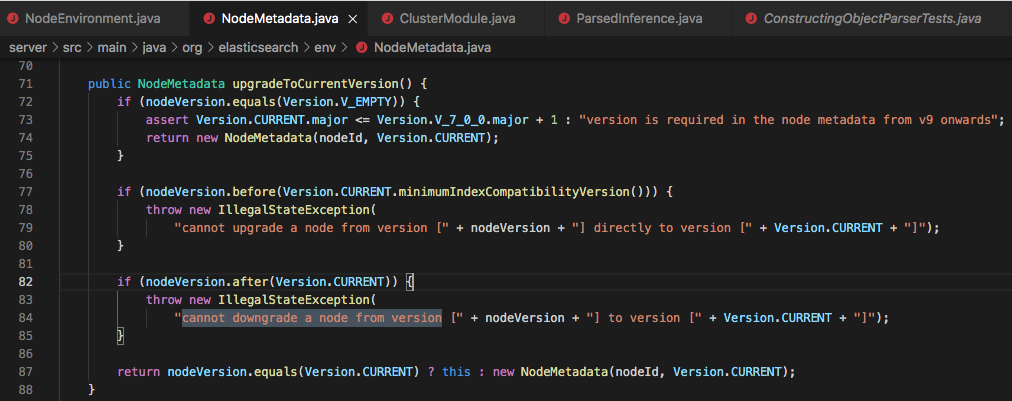
VSCode中打开该仓库:https://github1s.com/elastic/elasticsearch/blob/HEAD/server/src/main/java/org/elasticsearch/env/NodeMetadata.java
1. 最简单方案
版本做了很小的升级,你也很清楚,降级不会影响业务和程序。
最简单的方法,就是把集群内部状态的版本改下。
集群内部状态是基于lucene的文件系统,修改集群状态,代码如下:
public class Application {static final String NODE_VERSION_KEY = "node_version";//7130499 -> 7110299public static void main(String[] args) {int targetNodeVersion = 7110299;String _state = "/data/elk/elasticsearch-7.11.2/data/nodes/0/_state/";Path path = Paths.get(_state);try (DirectoryReader reader = DirectoryReader.open(new SimpleFSDirectory(path))) {final Map<String, String> userData = reader.getIndexCommit().getUserData();System.out.println(userData.toString());try (IndexWriter indexWriter =createIndexWriter(new SimpleFSDirectory(path), true)) {final Map<String, String> commitData = new HashMap<>(userData);commitData.put(NODE_VERSION_KEY, Integer.toString(targetNodeVersion));indexWriter.setLiveCommitData(commitData.entrySet());indexWriter.commit();}} catch (Exception e) {e.printStackTrace();}}private static IndexWriter createIndexWriter(Directory directory, boolean openExisting) throws IOException {final IndexWriterConfig indexWriterConfig = new IndexWriterConfig(new KeywordAnalyzer());// start empty since we re-write the whole cluster state to ensure it is all using the same format versionindexWriterConfig.setOpenMode(openExisting ? IndexWriterConfig.OpenMode.APPEND : IndexWriterConfig.OpenMode.CREATE);// only commit when specifically instructed, we must not write any intermediate statesindexWriterConfig.setCommitOnClose(false);// most of the data goes into stored fields which are not buffered, so we only really need a tiny bufferindexWriterConfig.setRAMBufferSizeMB(1.0);// merge on the write thread (e.g. while flushing)indexWriterConfig.setMergeScheduler(new SerialMergeScheduler());return new IndexWriter(directory, indexWriterConfig);}
}
2. 复制数据仓库
如果你的数据很少,比如索引、账号、Kibana索引等。重新建设很快,那我建议还是重新建设吧。
如果重建过程非常耗时,成本比较高,并且你有另外一套相同版本的环境,那就好办了。
打包另一个环境的path.data目录,复制到当前环境中,然后重新设置账号信息即可。
# 1. 创建一个管理员账号
bin/elasticsearch-users useradd admin -p 123456 -r superuser# 2. 重置elastic密码
curl --user admin:123456 -XPUT "http://localhost:9200/_security/user/elastic/_password?pretty" -H 'Content-Type: application/json' -d '{"password" : "123456"}'
这篇关于Elasticsearch cannot downgrade a node from version [7.x.x] to version [7.x.x]的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





