本文主要是介绍论文阅读——Distillation-guided Image Inpainting,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文链接:Distillation-Guided Image Inpainting (ICCV 2021). Maitreya Suin, Kuldeep Purohit, A. N. Rajagopalan [Paper]
本文创新点:提出了一种基于知识蒸馏的修复方法,构建辅助网络(重构图像)为修复网络提供监督信号。
网络结构
网络主要由两个部分组成,一是修复网络(IN),而是辅助网络(AN),辅助网络仅用于训练。
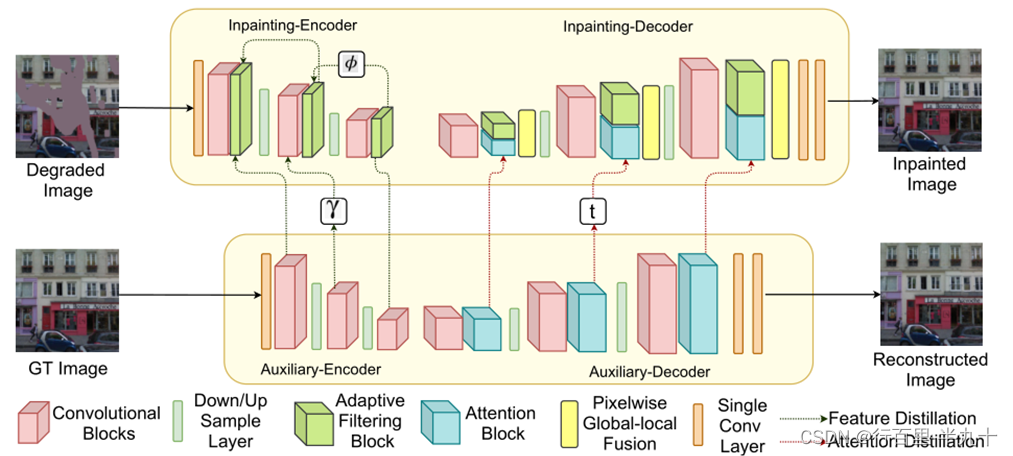
Cross-Distillation (CD)
交叉蒸馏是编码阶段修复网络学习辅助网络中的特征。
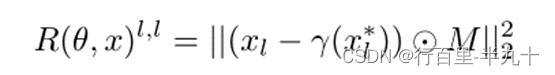
其中,x 为输入图像,θ为修补网络的参数,M 为二值掩码(1为缺失区域,0为已知区域),γ代表一个meta net-work(元网络),xl 为IN(修补网络)编码器第l 层的输出,xl* 为AN(辅助网络)编码器第l 层的输出。
cross distillation loss
用另一组由全连接层组成的元网络(ρ ),来决定AN模型的哪些特征通道对嵌入任务是有用的,假设编码器有L 层,

其中![]() ,
,![]() ,为通道c的非负权重,
,为通道c的非负权重,![]() 。
。
Self-Distillation (SD)
IN(修补网络)较深层充当老师,较浅层充当学生。
self distillation loss
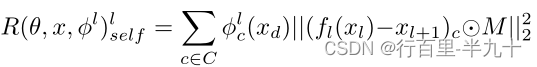
其中![]() ,
,![]() ,为通道c的非负权重,
,为通道c的非负权重,![]() ,
,![]() 为卷积层,使
为卷积层,使![]() 与
与![]() 尺寸相同,
尺寸相同,![]() 代表一个元网络。
代表一个元网络。
final distillation loss
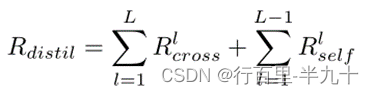
Adaptive Completion-block (CB)
CB在编码器每层的末尾更新缺失区域,
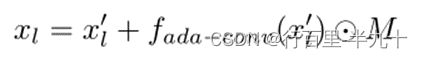
其中,xl' 是编码器第l 层特征,fada-conv 为自适应卷积。
自适应卷积层
设y 为自适应卷积层的输出,![]() 为输入特征,
为输入特征,

其中,K 为卷积核的大小,j 为输出像素的位置,jk 为dilation为1的卷积核的位置,
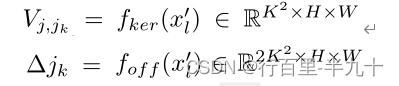
Vj,jk ,∆jk 分别为可学习的像素相关核和偏移,fker 和foff 代表卷积层。
Attention Transfer
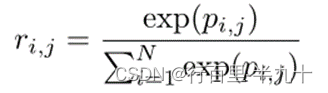
其中,![]() ,fQ 和fK 为1*1的卷积,N 为总像素数,d 为输入特征。
,fQ 和fK 为1*1的卷积,N 为总像素数,d 为输入特征。
该注意力层的输出由下式给出
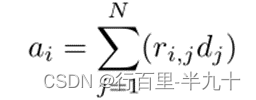
注意力转移损失为:
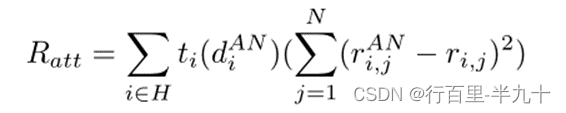
其中,H 表示缺失区域,t 为一个元网络,主要从 AN 网络中选择学习相似性的相对重要性,ti 介于0-1之间。
Pixel-adaptive Global-Local Fusion (PGL)
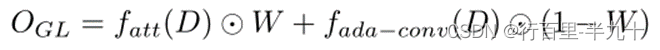
其中,![]() 是像素权重图,fw 是单个卷积层,D 为输入特征图,OGL 为混合输出,fatt 为全局注意力自适应卷积模块,fada-conv 为局部注意力自适应卷积模块。
是像素权重图,fw 是单个卷积层,D 为输入特征图,OGL 为混合输出,fatt 为全局注意力自适应卷积模块,fada-conv 为局部注意力自适应卷积模块。
总体损失
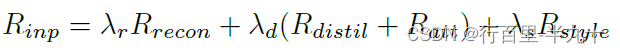
这篇关于论文阅读——Distillation-guided Image Inpainting的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)