本文主要是介绍13. SAP ABAP OData 服务的分页加载数据集的实现(Paging),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SAP UI5 应用的分页加载数据集,是一个极为重要的特性,需要 SAP UI5 前端和 OData 服务后端同时进行相应的开发工作,才能实现这个场景。
所谓分页加载数据集,就是默认情况下,SAP UI5 应用在启动后的默认页面里,只显示指定数据的数据集,这个个数默认为 20,也可以在系统或者代码里进行配置。因此我们可以理解成,SAP UI5 应用初始化时,默认从数据库加载第 1 到第 20 条数据。
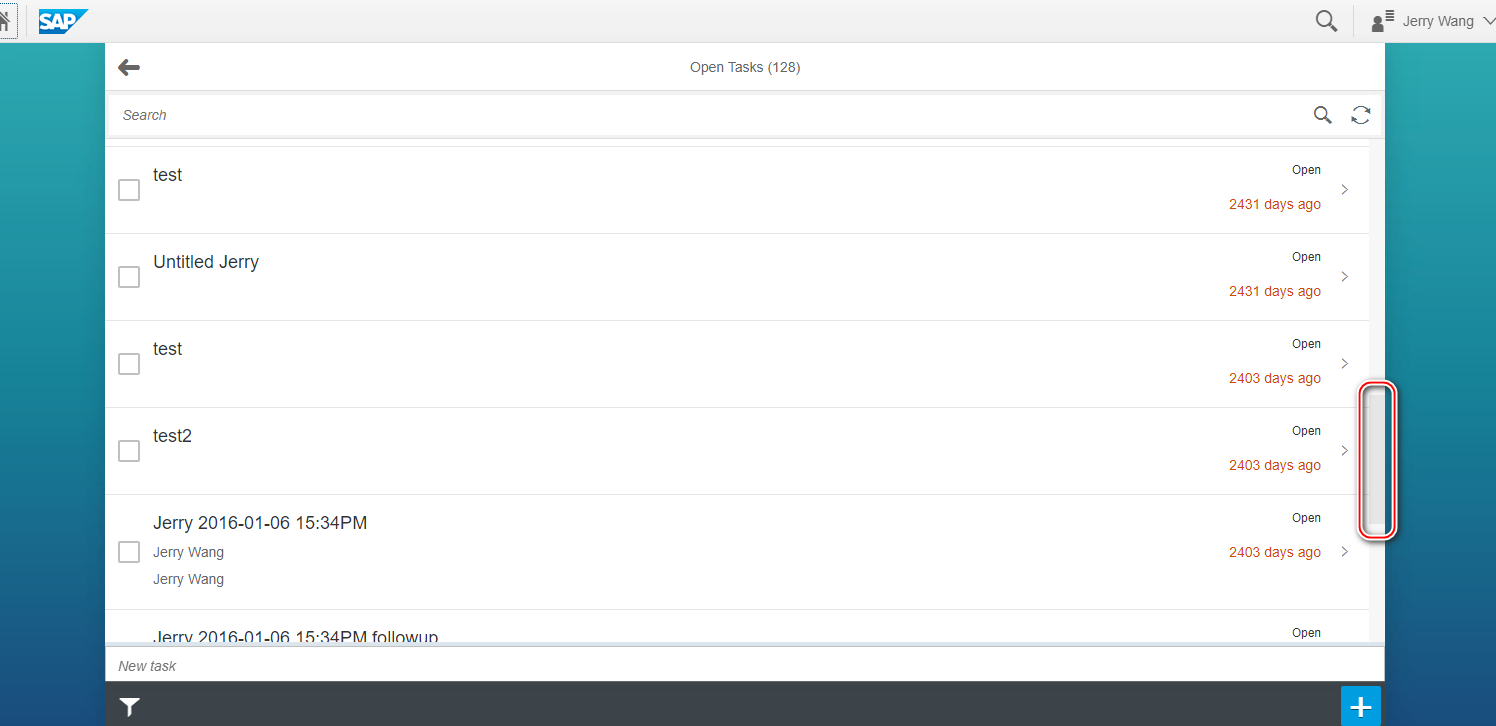
当我们的滚动条向下滑动至屏幕底部时,会触发新一批数据的加载,读取第 21 条到第 40条也就是第二个 20 条数据。
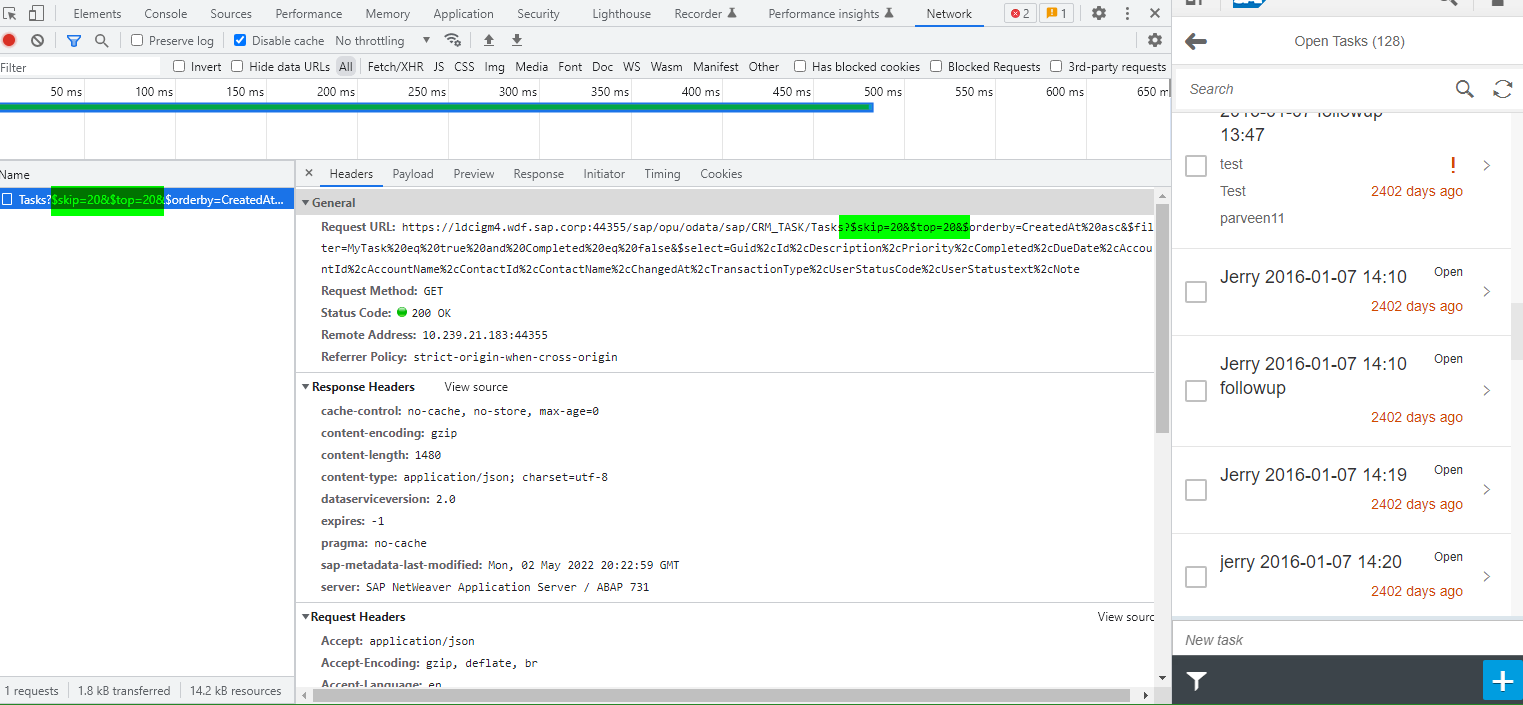
SAP UI5 调用后台 OData 服务时,通过参数 $skip=X&$top=Y 来进行分页场景的指定。
-
其中
$skip=X,代表跳过数据库第 X 条记录,从 X + 1 条记录开始读取(X为索引值,从 0 开始计数) -
$top=Y,代表总共读取数据库 Y 条记录。
假设后台的 SAP ABAP OData 服务针对消费者通过 url 传入的 $skip=X&$top=Y,已经正确实现,则 SAP UI5 应用,
这篇关于13. SAP ABAP OData 服务的分页加载数据集的实现(Paging)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







