本文主要是介绍【Python】三方库:使用tle2czml库将tle数据转为czml数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文作者:我辈李想
版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。
文章目录
- 一、安装tle2czml
- 二、tle2czmlc创建czml
- 三、tle转成czml
- 1.字符串
- 2.文件(网络文件)
- 四、czml参数修改
一、安装tle2czml
使用清华源安装tle2czml
pip install tle2czml -i https://pypi.tuna.tsinghua.edu.cn/simple
现在时间2023年5月是10日,现在安装的tle2czml版本为0.3,依赖包括pygeoif和sgp4。上述安装会报错ImportError: cannot import name ‘as_shape’ from ‘pygeoif.geometry’,原因是pygeoif最新版是1.0,需要降低pygeoif版本为0.7。
pip install pygeoif==0.7 -i https://pypi.tuna.tsinghua.edu.cn/simple
基于tle2czml做了部分修改,请参考https://github.com/lpfandr/tle2czml
二、tle2czmlc创建czml
创建没什么问题,直接使用官方案例
tle.txt内容如下
ISS (ZARYA)
1 25544U 98067A 20293.22611972 .00000497 00000-0 17003-4 0 9991
2 25544 51.6436 94.7185 0001350 46.8729 126.5595 15.49312821251249
KESTREL EYE IIM (KE2M)
1 42982U 98067NE 20293.11355452 .00022129 00000-0 15728-3 0 9999
2 42982 51.6336 8.5058 0001619 215.9884 144.1006 15.73808685170523
DELLINGR (RBLE)
1 43021U 98067NJ 20292.66572402 .00020201 00000-0 13900-3 0 9998
2 43021 51.6343 8.5926 0000331 53.4398 306.6632 15.74631224166254
UBAKUSAT
1 43467U 98067NQ 20293.19063114 .00070844 00000-0 29473-3 0 9996
2 43467 51.6335 1.3662 0002867 6.9343 353.1700 15.85064344139669
CUBERRT
1 43546U 98067NU 20292.65915576 .00130902 00000-0 58528-3 0 9997
2 43546 51.6326 6.1225 0002465 18.8688 341.2406 15.83306046129681
代码
import tle2czml
from datetime import datetime# You can specify the time range you would like to visualise
start_time = datetime(2020, 10, 1, 17, 30)
end_time = datetime(2020, 10, 2, 19, 30)
tle2czml.create_czml("tle.txt", start_time=start_time, end_time=end_time)
三、tle转成czml
这里涉及到一个问题,就是tles的内容,tles的来源可能是字符串或文件(网络文件)。
1.字符串
tles为字符串是需要注意tles 的内容,示例代码如下;
import tle2czmltles = '''BEIDOU 2
1 31115U 07011A 21323.16884980 -.00000043 00000-0 00000-0 0 9993
2 31115 51.9034 274.7604 0003928 314.2233 45.7206 1.77349177 46511
BEIDOU 3
1 36287U 10001A 21323.54986160 -.00000268 00000-0 00000-0 0 9995
2 36287 1.7347 43.1625 0001966 74.6398 279.3247 1.00266671 43404'''
czml = tle2czml.tles_to_czml(tles)
print(czml)
fo = open("test.czml", "w")
fo.write(czml)
fo.close()
如果封装为函数,示例代码如下:
import tle2czmldef test():tles = '''BEIDOU 2
1 31115U 07011A 21323.16884980 -.00000043 00000-0 00000-0 0 9993
2 31115 51.9034 274.7604 0003928 314.2233 45.7206 1.77349177 46511
BEIDOU 3
1 36287U 10001A 21323.54986160 -.00000268 00000-0 00000-0 0 9995
2 36287 1.7347 43.1625 0001966 74.6398 279.3247 1.00266671 43404'''czml = tle2czml.tles_to_czml(tles)print(czml)fo = open("test.czml", "w")fo.write(czml)fo.close()
2.文件(网络文件)
import json
import tle2czmlstations_url = 'https://x.xxx.com/tle/tle.txt'
tles = requests.get(stations_url).text
czml = tle2czml.tles_to_czml(tles, silent=True)
print(json.loads(czml))
四、czml参数修改
tle2czml中封装了czml生成涉及到的相关参数,但是没有提供参数的修改方法。
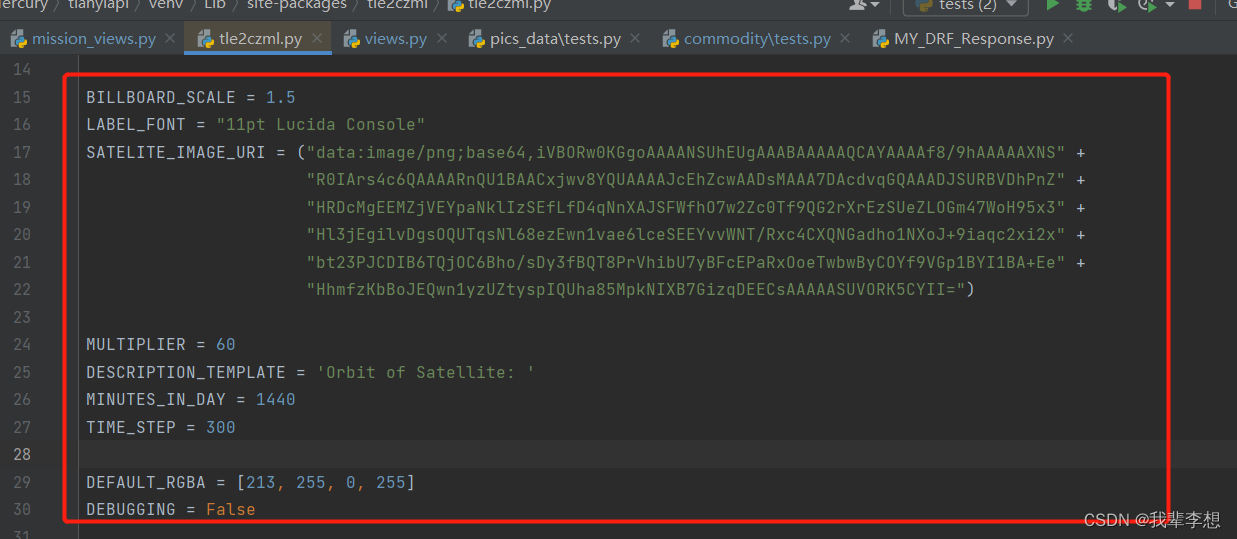
根据实际项目,有些参数需要修改,比如MULTIPLIER代表乘数,影响Cesium中轨道的速度;SATELITE_IMAGE_URI代表模型,类型为图片bsae64,影响Cesium中轨道上展示的卫星图形。如果想要使用上述参数,可以按照如下示例:
import jsonimport requests
from tle2czml import *stations_url = 'https://x.xxx.com/tle/tle.txt'
tles = requests.get(stations_url).text
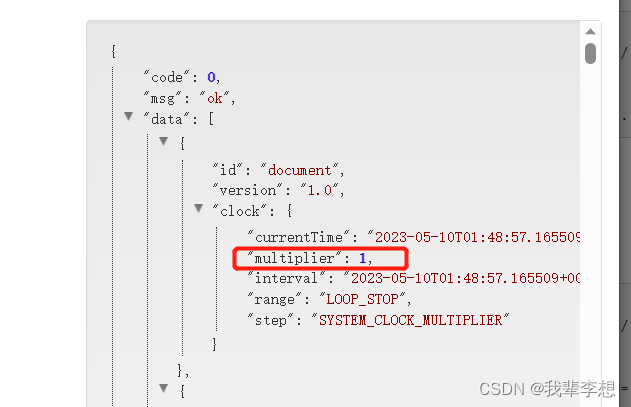
tle2czml.MULTIPLIER = 1
czml = tle2czml.tles_to_czml(tles, silent=True)
# print('data', type(data))
print(json.loads(czml)[0]['clock']['multiplier'])
MULTIPLIER 参数前后对比如下:

这篇关于【Python】三方库:使用tle2czml库将tle数据转为czml数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




