本文主要是介绍i.mx8 DMA流程分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DMA无论是在mcu中还是在Soc中的使用都变得非常的普遍。从硬件的角度,DMA可以说是继中断之后另一个重要的里程碑。它开创了硬件加速的时代来解放处理器资源,继DMA之后各种特定功能的硬件加速应运而生,但只有DMA有如此广泛的应用。
本文不会对linux下的DMA映射做过多的描述,读者可以参考linux内核 Documentation下的DMA-API.txt ,DMA-API-HOWTO.txt文档,这些文档对dma空间的申请以及映射所需的API做了详细的描述。本篇文章的重点在于描述imx8 下DMA的驱动的注册。后续准备再写一篇文章将DMA的使用描述出来从设备树到驱动中如何去使用DMA的流程进行分析。希望读者手边能有一份代码。
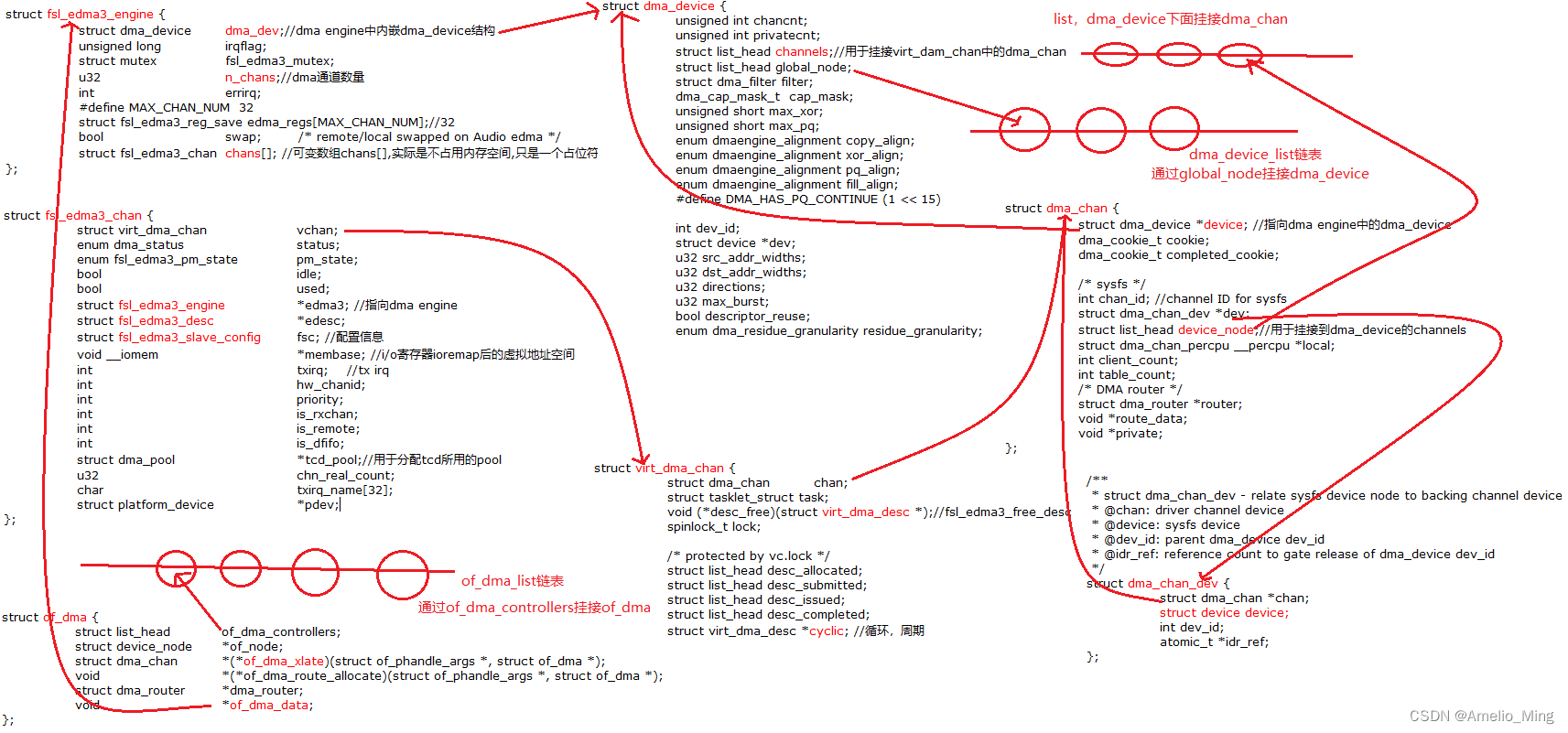
1.数据结构
我也知道看这么一大堆数据结构很不爽,但是莫得办法啊,这些核心的数据结构是绕不开的。如果不将各个数据结构之间的关系梳理清楚,一旦代码里面涉及到数据结构相互之间相互指向就会搞不清楚,所以梳理框架很大一部分工作是在梳理核心数据结构之间的关系。
DMA中涉及的数据结构也非常的多,imx8自身DMA的管理需要一些数据结构(一般fsl开头的数据结构用于imx8管理所用),其次就是dmaengine框架里面的核心数据结构,部分非关键数据结构未一一列出。
struct fsl_edma3_engine {
struct dma_device dma_dev;//dma engine中内嵌dma_device结构
unsigned long irqflag;
struct mutex fsl_edma3_mutex;
u32 n_chans;//dma通道数量
int errirq;
#define MAX_CHAN_NUM 32
struct fsl_edma3_reg_save edma_regs[MAX_CHAN_NUM];//32
bool swap; /* remote/local swapped on Audio edma */
struct fsl_edma3_chan chans[]; //可变数组chans[],实际是不占用内存空间,只是一个占位符
};
struct fsl_edma3_chan {
struct virt_dma_chan vchan;
enum dma_status status;
enum fsl_edma3_pm_state pm_state;
bool idle;
bool used;
struct fsl_edma3_engine *edma3; //指向dma engine
struct fsl_edma3_desc *edesc;
struct fsl_edma3_slave_config fsc; //配置信息
void __iomem *membase; //i/o寄存器ioremap后的虚拟地址空间
int txirq; //tx irq
int hw_chanid;
int priority;
int is_rxchan;
int is_remote;
int is_dfifo;
struct dma_pool *tcd_pool;//用于分配tcd所用的pool
u32 chn_real_count;
char txirq_name[32];
struct platform_device *pdev;
};
struct virt_dma_chan {
struct dma_chan chan;
struct tasklet_struct task;
void (*desc_free)(struct virt_dma_desc *);//fsl_edma3_free_desc
spinlock_t lock;
/* protected by vc.lock */
struct list_head desc_allocated;
struct list_head desc_submitted;
struct list_head desc_issued;
struct list_head desc_completed;
struct virt_dma_desc *cyclic; //循环,周期
};
struct dma_slave_config {
enum dma_transfer_direction direction;
phys_addr_t src_addr;
phys_addr_t dst_addr;
enum dma_slave_buswidth src_addr_width;
enum dma_slave_buswidth dst_addr_width;
u32 src_maxburst;
u32 dst_maxburst;
u32 src_port_window_size;
u32 dst_port_window_size;
u32 src_fifo_num;
u32 dst_fifo_num;
bool device_fc;
unsigned int slave_id;
};
struct dma_device是其中非常关键的数据结构,dma底层的实现如dma通道配置,申请,描述符的提交(submit),寄存器的配置 等核心函数都是以面向对象的思想给出了函数指针,驱动层实现这些函数并赋值给对应的函数指针。
struct dma_device {
unsigned int chancnt;
unsigned int privatecnt;
struct list_head channels;//用于挂接virt_dam_chan中的dma_chan
struct list_head global_node;
struct dma_filter filter;
dma_cap_mask_t cap_mask;
unsigned short max_xor;
unsigned short max_pq;
enum dmaengine_alignment copy_align;
enum dmaengine_alignment xor_align;
enum dmaengine_alignment pq_align;
enum dmaengine_alignment fill_align;
#define DMA_HAS_PQ_CONTINUE (1 << 15)
int dev_id;
struct device *dev;
u32 src_addr_widths;
u32 dst_addr_widths;
u32 directions;
u32 max_burst;
bool descriptor_reuse;
enum dma_residue_granularity residue_granularity;
int (*device_alloc_chan_resources)(struct dma_chan *chan); //fsl_edma3_alloc_chan_resources
void (*device_free_chan_resources)(struct dma_chan *chan); //fsl_edma3_free_chan_resources
struct dma_async_tx_descriptor *(*device_prep_dma_memcpy)(struct dma_chan *chan, dma_addr_t dst, dma_addr_t src,size_t len, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_xor)(struct dma_chan *chan, dma_addr_t dst, dma_addr_t *src,unsigned int src_cnt, size_t len, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_xor_val)(struct dma_chan *chan, dma_addr_t *src, unsigned int src_cnt,size_t len, enum sum_check_flags *result, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_pq)(struct dma_chan *chan, dma_addr_t *dst, dma_addr_t *src,unsigned int src_cnt, const unsigned char *scf,size_t len, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_pq_val)(struct dma_chan *chan, dma_addr_t *pq, dma_addr_t *src,unsigned int src_cnt, const unsigned char *scf, size_t len,enum sum_check_flags *pqres, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_memset)(struct dma_chan *chan, dma_addr_t dest, int value, size_t len,unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_memset_sg)(struct dma_chan *chan, struct scatterlist *sg,unsigned int nents, int value, unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_interrupt)(struct dma_chan *chan, unsigned long flags);
//fsl_edma3_prep_slave_sg
struct dma_async_tx_descriptor *(*device_prep_slave_sg)(struct dma_chan *chan, struct scatterlist *sgl,unsigned int sg_len, enum dma_transfer_direction direction,unsigned long flags, void *context);
//fsl_edma3_prep_dma_cyclic
struct dma_async_tx_descriptor *(*device_prep_dma_cyclic)(struct dma_chan *chan, dma_addr_t buf_addr, size_t buf_len,size_t period_len, enum dma_transfer_direction direction,unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_interleaved_dma)(struct dma_chan *chan, struct dma_interleaved_template *xt,unsigned long flags);
struct dma_async_tx_descriptor *(*device_prep_dma_imm_data)(struct dma_chan *chan, dma_addr_t dst, u64 data,unsigned long flags);
int (*device_config)(struct dma_chan *chan,struct dma_slave_config *config);//fsl_edma3_slave_config
int (*device_pause)(struct dma_chan *chan); //fsl_edma3_pause
int (*device_resume)(struct dma_chan *chan); //fsl_edma3_resume
int (*device_terminate_all)(struct dma_chan *chan); //fsl_edma3_terminate_all
void (*device_synchronize)(struct dma_chan *chan); //fsl_edma3_synchronize
enum dma_status (*device_tx_status)(struct dma_chan *chan,dma_cookie_t cookie,struct dma_tx_state *txstate);//fsl_edma3_tx_status
void (*device_issue_pending)(struct dma_chan *chan); //fsl_edma3_issue_pending
};
typedef s32 dma_cookie_t;
struct dma_async_tx_descriptor {
dma_cookie_t cookie;
enum dma_ctrl_flags flags; /* not a 'long' to pack with cookie */
dma_addr_t phys;
struct dma_chan *chan;
dma_cookie_t (*tx_submit)(struct dma_async_tx_descriptor *tx); //vchan_tx_submit
int (*desc_free)(struct dma_async_tx_descriptor *tx);
dma_async_tx_callback callback;
dma_async_tx_callback_result callback_result;
void *callback_param;
struct dmaengine_unmap_data *unmap;
#ifdef CONFIG_ASYNC_TX_ENABLE_CHANNEL_SWITCH
struct dma_async_tx_descriptor *next;
struct dma_async_tx_descriptor *parent;
spinlock_t lock;
#endif
};
struct virt_dma_desc {
struct dma_async_tx_descriptor tx;
/* protected by vc.lock */
struct list_head node;
};
下图将dma数据结构之间的关联描述出来
2、DMA驱动流程
DMA驱动流程涉及到其他外设中关于DMA的使用,只有这样才能将这个流程梳理的更加合理。
2.1、DMA设备驱动注册
static const struct of_device_id fsl_edma3_dt_ids[] = {
{ .compatible = "fsl,imx8qm-edma", }, //for eDMA used similar to that on i.MX8QM SoC
{ .compatible = "fsl,imx8qm-adma", }, //for audio eDMA used on i.MX8QM
{ /* sentinel */ }
};
MODULE_DEVICE_TABLE(of, fsl_edma3_dt_ids);
static struct platform_driver fsl_edma3_driver = {
.driver = {
.name = "fsl-edma-v3",
.of_match_table = fsl_edma3_dt_ids,
.pm = &fsl_edma3_pm_ops,
},
.probe = fsl_edma3_probe, //设备驱动和设备信息匹配后入口函数
.remove = fsl_edma3_remove,
};
static int __init fsl_edma3_init(void)
{
return platform_driver_register(&fsl_edma3_driver);
}
subsys_initcall(fsl_edma3_init);
static void __exit fsl_edma3_exit(void)
{
platform_driver_unregister(&fsl_edma3_driver);
}
module_exit(fsl_edma3_exit);
由于很多外设的读/写驱动依赖于DMA进行数据搬移,所以DMA的驱动匹配应该再其他依赖其的外设设备驱动匹配之前进行。
#define subsys_initcall(fn) __define_initcall(fn, 4)
#define device_initcall(fn) __define_initcall(fn, 6)
2.2、probe函数流程
fsl_edma3_probe流程说明:
1、获取设备树中"dma-channels"配置的DMA通道数量,根据通道数分配空间赋值给fsl_edma3,内存空间长度为len=sizeof(struct fsl_edma3_engine) + sizeof(struct fsl_edma3_chan) * chans。
2、获取设备树中"shared-interrupt"属性值,设置fsl_edma3->irqflag=IRQF_SHARED,Audio edma rx/tx通道共享中断。
3、遍历前面分配的DMA通道fsl_edma3_chan,对成员进行赋值。获取每个通道的I/O地址资源并进行ioremap,通过将设备树中配置的(寄存器地址>>16)&0x1f的结果作为hw_chanid。
解析"interrupt-names"获取通道的中断名txirq_name,通过txirq_name获取对应的txirq。
调用vchan_init进行继续初始化。vchan_init主要初始化vc dma cookie,初始化vc自旋锁,初始化vc list,通过tasklet_init(&vc->task, vchan_complete, (unsigned long)vc)开启tasklet处理,通过list_add_tail(&vc->chan.device_node, &dmadev->channels)将vc->chan挂接到dma_deivce的channles上.
4、初始化fsl_edma3_mutex锁。
5、设置DMA能力mask值,初始化dma_dev成员变量值。
dma_cap_set(DMA_PRIVATE, fsl_edma3->dma_dev.cap_mask);
dma_cap_set(DMA_SLAVE, fsl_edma3->dma_dev.cap_mask);
dma_cap_set(DMA_CYCLIC, fsl_edma3->dma_dev.cap_mask);
fsl_edma3->dma_dev.dev = &pdev->dev;
fsl_edma3->dma_dev.device_alloc_chan_resources = fsl_edma3_alloc_chan_resources;
fsl_edma3->dma_dev.device_free_chan_resources = fsl_edma3_free_chan_resources;
fsl_edma3->dma_dev.device_tx_status = fsl_edma3_tx_status;
fsl_edma3->dma_dev.device_prep_slave_sg = fsl_edma3_prep_slave_sg;
fsl_edma3->dma_dev.device_prep_dma_cyclic = fsl_edma3_prep_dma_cyclic;
fsl_edma3->dma_dev.device_config = fsl_edma3_slave_config;
fsl_edma3->dma_dev.device_pause = fsl_edma3_pause;
fsl_edma3->dma_dev.device_resume = fsl_edma3_resume;
fsl_edma3->dma_dev.device_terminate_all = fsl_edma3_terminate_all;
fsl_edma3->dma_dev.device_issue_pending = fsl_edma3_issue_pending;
fsl_edma3->dma_dev.device_synchronize = fsl_edma3_synchronize;
fsl_edma3->dma_dev.src_addr_widths = FSL_EDMA_BUSWIDTHS;
fsl_edma3->dma_dev.dst_addr_widths = FSL_EDMA_BUSWIDTHS;
fsl_edma3->dma_dev.directions = BIT(DMA_DEV_TO_MEM) | BIT(DMA_MEM_TO_DEV) | BIT(DMA_DEV_TO_DEV);
6、调用dma_async_device_register注册DMA设备。dma_async_device_register主要实现:检查capacity能力与其对应的函数是否实现.遍历dma device channels上挂载的 dma_chan结构,注册每个DMA通道设备。
7、遍历所有dam通道,设置每个通道的power domains.
8、调用of_dma_controller_register 进行控制器注册。
2.3、实现细节
其实就是将调用链中的所有关键函数一一罗列出来,并加上了关键的注释。
//将dma_device和virt_dma_chan进行关联
void vchan_init(struct virt_dma_chan *vc, struct dma_device *dmadev)
{
dma_cookie_init(&vc->chan);
spin_lock_init(&vc->lock);
INIT_LIST_HEAD(&vc->desc_allocated);
INIT_LIST_HEAD(&vc->desc_submitted);
INIT_LIST_HEAD(&vc->desc_issued);
INIT_LIST_HEAD(&vc->desc_completed);
//初始化 tasklet
tasklet_init(&vc->task, vchan_complete, (unsigned long)vc);
vc->chan.device = dmadev;//指向dma_device结构
list_add_tail(&vc->chan.device_node, &dmadev->channels);//将chan挂接到dma_deivce的channles上
}
/**
* dma_async_device_register - registers DMA devices found
* @device: &dma_device
*/
int dma_async_device_register(struct dma_device *device)
{
int chancnt = 0, rc;
struct dma_chan* chan;
atomic_t *idr_ref;
if (!device)
return -ENODEV;
/* validate device routines */
if (!device->dev) {
pr_err("DMAdevice must have dev\n");
return -EIO;
}
//检查capacity能力与其对应的函数是否实现
if (dma_has_cap(DMA_MEMCPY, device->cap_mask) && !device->device_prep_dma_memcpy) {
dev_err(device->dev,
"Device claims capability %s, but op is not defined\n",
"DMA_MEMCPY");
return -EIO;
}
if (dma_has_cap(DMA_XOR, device->cap_mask) && !device->device_prep_dma_xor) {
dev_err(device->dev,
"Device claims capability %s, but op is not defined\n",
"DMA_XOR");
return -EIO;
}
if (dma_has_cap(DMA_XOR_VAL, device->cap_mask) && !device->device_prep_dma_xor_val) {
dev_err(device->dev,
"Device claims capability %s, but op is not defined\n",
"DMA_XOR_VAL");
return -EIO;
}
if (dma_has_cap(DMA_PQ, device->cap_mask) && !device->device_prep_dma_pq) {
dev_err(device->dev,
"Device claims capability %s, but op is not defined\n",
"DMA_PQ");
return -EIO;
}
if (dma_has_cap(DMA_PQ_VAL, device->cap_mask) && !device->device_prep_dma_pq_val) {
dev_err(device->dev,
"Device claims capability %s, but op is not defined\n",
"DMA_PQ_VAL");
return -EIO;
}
if (dma_has_cap(DMA_MEMSET, device->cap_mask) && !device->device_prep_dma_memset) {
dev_err(device->dev,
"Device claims capability %s, but op is not defined\n",
"DMA_MEMSET");
return -EIO;
}
if (dma_has_cap(DMA_INTERRUPT, device->cap_mask) && !device->device_prep_dma_interrupt) {
dev_err(device->dev,
"Device claims capability %s, but op is not defined\n",
"DMA_INTERRUPT");
return -EIO;
}
//imx8 DMA具有该能力
if (dma_has_cap(DMA_CYCLIC, device->cap_mask) && !device->device_prep_dma_cyclic) {
dev_err(device->dev,
"Device claims capability %s, but op is not defined\n",
"DMA_CYCLIC");
return -EIO;
}
if (dma_has_cap(DMA_INTERLEAVE, device->cap_mask) && !device->device_prep_interleaved_dma) {
dev_err(device->dev,
"Device claims capability %s, but op is not defined\n",
"DMA_INTERLEAVE");
return -EIO;
}
if (!device->device_tx_status) {
dev_err(device->dev, "Device tx_status is not defined\n");
return -EIO;
}
if (!device->device_issue_pending) {
dev_err(device->dev, "Device issue_pending is not defined\n");
return -EIO;
}
/* note: this only matters in the CONFIG_ASYNC_TX_ENABLE_CHANNEL_SWITCH=n case */
if (device_has_all_tx_types(device)) //检查capacity能力
dma_cap_set(DMA_ASYNC_TX, device->cap_mask);
idr_ref = kmalloc(sizeof(*idr_ref), GFP_KERNEL); //原子变量
if (!idr_ref)
return -ENOMEM;
//分配一个ID值给device->dev_id
rc = get_dma_id(device);
if (rc != 0) {
kfree(idr_ref);
return rc;
}
atomic_set(idr_ref, 0); //设置原子变量为0
/* represent channels in sysfs. Probably want devs too */
list_for_each_entry(chan, &device->channels, device_node) { //遍历dma device channels上挂载的 dma_chan结构
rc = -ENOMEM;
chan->local = alloc_percpu(typeof(*chan->local)); //perCPU变量
if (chan->local == NULL)
goto err_out;
chan->dev = kzalloc(sizeof(*chan->dev), GFP_KERNEL); //分配chan->dev,dma_chan_dev空间
if (chan->dev == NULL) {
free_percpu(chan->local);
chan->local = NULL;
goto err_out;
}
//初始化dma_chan结构的成员变量
chan->chan_id = chancnt++;
//初始化dma_chan_dev成员变量
chan->dev->device.class = &dma_devclass;
chan->dev->device.parent = device->dev;
chan->dev->chan = chan;
chan->dev->idr_ref = idr_ref;
chan->dev->dev_id = device->dev_id;
atomic_inc(idr_ref);
dev_set_name(&chan->dev->device, "dma%dchan%d",device->dev_id, chan->chan_id);
rc = device_register(&chan->dev->device); //注册DMA设备的每个DMA通道
if (rc) {
free_percpu(chan->local);
chan->local = NULL;
kfree(chan->dev);
atomic_dec(idr_ref);
goto err_out;
}
chan->client_count = 0;
}
if (!chancnt) {
dev_err(device->dev, "%s: device has no channels!\n", __func__);
rc = -ENODEV;
goto err_out;
}
device->chancnt = chancnt; //DMA设备通道个数
mutex_lock(&dma_list_mutex);
/* take references on public channels */
if (dmaengine_ref_count && !dma_has_cap(DMA_PRIVATE, device->cap_mask))
list_for_each_entry(chan, &device->channels, device_node) {
/* if clients are already waiting for channels we need
* to take references on their behalf
*/
if (dma_chan_get(chan) == -ENODEV) {
/* note we can only get here for the first
* channel as the remaining channels are
* guaranteed to get a reference
*/
rc = -ENODEV;
mutex_unlock(&dma_list_mutex);
goto err_out;
}
}
//将dma_device挂接到dma_device_list链表上
list_add_tail_rcu(&device->global_node, &dma_device_list);
if (dma_has_cap(DMA_PRIVATE, device->cap_mask))
device->privatecnt++; /* Always private */
dma_channel_rebalance();
mutex_unlock(&dma_list_mutex);
return 0;
err_out:
/* if we never registered a channel just release the idr */
if (atomic_read(idr_ref) == 0) {
mutex_lock(&dma_list_mutex);
ida_remove(&dma_ida, device->dev_id);
mutex_unlock(&dma_list_mutex);
kfree(idr_ref);
return rc;
}
list_for_each_entry(chan, &device->channels, device_node) {
if (chan->local == NULL)
continue;
mutex_lock(&dma_list_mutex);
chan->dev->chan = NULL;
mutex_unlock(&dma_list_mutex);
device_unregister(&chan->dev->device);
free_percpu(chan->local);
}
return rc;
}
/**
* of_dma_controller_register - Register a DMA controller to DT DMA helpers
* @np: device node of DMA controller
* @of_dma_xlate: translation function which converts a phandle arguments list into a dma_chan structure
* @data pointer to controller specific data to be used by translation function
*
* Returns 0 on success or appropriate errno value on error.
*
* Allocated memory should be freed with appropriate of_dma_controller_free() call.
*/
int of_dma_controller_register(struct device_node *np,
struct dma_chan *(*of_dma_xlate)(struct of_phandle_args *, struct of_dma *),
void *data)
{
struct of_dma *ofdma;
if (!np || !of_dma_xlate) {
pr_err("%s: not enough information provided\n", __func__);
return -EINVAL;
}
//分配of_dma内存空间
ofdma = kzalloc(sizeof(*ofdma), GFP_KERNEL);
if (!ofdma)
return -ENOMEM;
ofdma->of_node = np;
ofdma->of_dma_xlate = of_dma_xlate;//fsl_edma3_xlate
ofdma->of_dma_data = data; //fsl_edma3
/* Now queue of_dma controller structure in list */
mutex_lock(&of_dma_lock);
//通过of_dma->of_dma_controllers将of_dma挂接到of_dma_list链表上
list_add_tail(&ofdma->of_dma_controllers, &of_dma_list);
mutex_unlock(&of_dma_lock);
return 0;
}
3、dma中断处理以及callback回调函数
//中断处理函数
static irqreturn_t fsl_edma3_tx_handler(int irq, void *dev_id)
{
struct fsl_edma3_chan *fsl_chan = dev_id;
unsigned int intr;
void __iomem *base_addr;
spin_lock(&fsl_chan->vchan.lock);
/* Ignore this interrupt since channel has been freeed with power off */
if (!fsl_chan->edesc && !fsl_chan->tcd_pool){
goto irq_handled;
}
base_addr = fsl_chan->membase;
intr = readl(base_addr + EDMA_CH_INT); //Channel Interrupt Status Register
if (!intr){
goto irq_handled;
}
writel(1, base_addr + EDMA_CH_INT); //清除中断状态
/* Ignore this interrupt since channel has been disabled already */
if (!fsl_chan->edesc){
goto irq_handled;
}
if (!fsl_chan->edesc->iscyclic) { //非周期
fsl_edma3_get_realcnt(fsl_chan);
//删除节点
list_del(&fsl_chan->edesc->vdesc.node);
//主要是将virt_dma_desc挂接到desc_completed链表上
vchan_cookie_complete(&fsl_chan->edesc->vdesc);
fsl_chan->edesc = NULL;
fsl_chan->status = DMA_COMPLETE;
fsl_chan->idle = true;
} else {
vchan_cyclic_callback(&fsl_chan->edesc->vdesc);
}
if (!fsl_chan->edesc){ //设置下一个描述符
fsl_edma3_xfer_desc(fsl_chan);
}
irq_handled:
spin_unlock(&fsl_chan->vchan.lock);
return IRQ_HANDLED;
}
/**
* vchan_cookie_complete - report completion of a descriptor
* @vd: virtual descriptor to update
*
* vc.lock must be held by caller
*/
static inline void vchan_cookie_complete(struct virt_dma_desc *vd)
{
struct virt_dma_chan *vc = to_virt_chan(vd->tx.chan);
dma_cookie_t cookie;
cookie = vd->tx.cookie;
dma_cookie_complete(&vd->tx);
dev_vdbg(vc->chan.device->dev, "txd %p[%x]: marked complete\n",vd, cookie);
//将virt_dma_desc挂接到desc_completed链表上
list_add_tail(&vd->node, &vc->desc_completed);
tasklet_schedule(&vc->task); //完成DMA传输后,启用tasklet下半部处理,执行vchan_complete
}
/**
* dma_cookie_complete - complete a descriptor
* @tx: descriptor to complete
*
* Mark this descriptor complete by updating the channels completed
* cookie marker. Zero the descriptors cookie to prevent accidental
* repeated completions.
*
* Note: caller is expected to hold a lock to prevent concurrency.
*/
static inline void dma_cookie_complete(struct dma_async_tx_descriptor *tx)
{
BUG_ON(tx->cookie < DMA_MIN_COOKIE);
tx->chan->completed_cookie = tx->cookie;
tx->cookie = 0;
}
4、tasklet处理callbaclk函数
vchan_init中使用taslet注册中断下半部处理接口vchan_complete
tasklet_init(&vc->task, vchan_complete, (unsigned long)vc);
/*
* This tasklet handles the completion of a DMA descriptor by calling its callback and freeing it.
*/
static void vchan_complete(unsigned long arg)
{
struct virt_dma_chan *vc = (struct virt_dma_chan *)arg;
struct virt_dma_desc *vd, *_vd;
struct dmaengine_desc_callback cb;
LIST_HEAD(head);
spin_lock_irq(&vc->lock);
//将desc_completed链表和head链表合并,desc_completed链表头desc_completed则被遗弃,所以需要重新初始化
//这里主要是释放desc_completed链表
list_splice_tail_init(&vc->desc_completed, &head);
vd = vc->cyclic;
if (vd) {
vc->cyclic = NULL;
//获取其callback函数
dmaengine_desc_get_callback(&vd->tx, &cb);
} else {
memset(&cb, 0, sizeof(cb));
}
spin_unlock_irq(&vc->lock);
//调用callback函数
dmaengine_desc_callback_invoke(&cb, NULL);
//遍历head链表
list_for_each_entry_safe(vd, _vd, &head, node) {
dmaengine_desc_get_callback(&vd->tx, &cb);
//将virt_dma_desc从head中删除
list_del(&vd->node);
调用callback函数
dmaengine_desc_callback_invoke(&cb, NULL);
if (dmaengine_desc_test_reuse(&vd->tx)) //reuse标志有效则将vd放回desc_allocated链表中
list_add(&vd->node, &vc->desc_allocated);
else
vc->desc_free(vd);
}
}
/**
* dmaengine_desc_get_callback - get the passed in callback function
* @tx: tx descriptor
* @cb: temp struct to hold the callback info
*
* Fill the passed in cb struct with what's available in the passed in
* tx descriptor struct
* No locking is required.
*/
static inline void dmaengine_desc_get_callback(struct dma_async_tx_descriptor *tx,struct dmaengine_desc_callback *cb)
{
cb->callback = tx->callback;
cb->callback_result = tx->callback_result;
cb->callback_param = tx->callback_param;
}
/**
* dmaengine_desc_callback_invoke - call the callback function in cb struct
* @cb: temp struct that is holding the callback info
* @result: transaction result
*
* Call the callback function provided in the cb struct with the parameter
* in the cb struct.
* Locking is dependent on the driver.
*/
static inline void dmaengine_desc_callback_invoke(struct dmaengine_desc_callback *cb,const struct dmaengine_result *result)
{
struct dmaengine_result dummy_result = {
.result = DMA_TRANS_NOERROR,
.residue = 0
};
if (cb->callback_result) {
if (!result)
result = &dummy_result;
cb->callback_result(cb->callback_param, result);
} else if (cb->callback) {
cb->callback(cb->callback_param);
}
}
这篇关于i.mx8 DMA流程分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




